扩展搜索和索引
了解在搜索系统中扩展索引和搜索的有效方法。
建议设计的问题
尽管上一课中提出的设计看似合理,但仍然存在一些严重的缺陷。我们将在下面讨论这些缺点:
- 并置索引和搜索:我们创建了一个系统,可以在同一节点上并置索引和搜索。虽然这看起来是对资源的有效利用,但它也有其缺点。搜索和索引都是资源密集型操作。两种操作都会影响彼此的性能。此外,这种共置设计无法随着时间的推移随着索引和搜索操作的变化而有效扩展。在同一台机器上同时执行这两个操作可能会导致不平衡,并导致可伸缩性问题。
- 索引重新计算:我们假设每个副本都会单独计算索引,这会导致资源使用效率低下。此外,索引计算是一项资源密集型任务,可能包含数百个流水线操作阶段。因此,在不同的副本上重新计算相同的索引需要强大的机器。相反,合乎逻辑的方法是计算一次索引并将其复制到可用区域。
由于这些关键原因,我们将研究分布式索引和搜索的替代方法。
解决方案
我们不是在每个副本上重新计算索引,而是只在主节点上计算倒排索引。接下来,我们将倒排索引(二进制 blob/文件)传递给副本。这种方法的主要好处是它避免使用重复的 CPU 和内存来对副本进行索引。
警告
问题
上述解决方案的缺点是什么?
答案
由于倒排索引将被传输到副本,这将引入复制倒排索引文件的传输延迟,因为索引文件的大小可能非常大。
当主节点接收到新的索引操作时,倒排索引文件发生变化。在一定数量的索引操作达到定义的阈值后,每个副本都需要获取文件的最新版本。
分离索引和搜索
随着网络和虚拟化技术的出现,云计算已成为一项成功的技术。在这种技术中,我们可以访问大量带宽(高达 100 Gbps)和可扩展的分布式存储。这些进步允许在索引和搜索之间进行强有力的分离,而不会产生索引延迟的负面影响。由于这种隔离,索引不会影响搜索可扩展性,反之亦然。此外,我们可以只复制索引文件,而不是在副本节点上重新计算索引,这会浪费资源。
我们将使用这些技术来重新设计我们的分布式索引和搜索系统。此搜索系统设计涉及三个组件:
- 索引器:它由一组计算索引的节点组成。
- 分布式存储:该系统用于存储分区和计算索引。
- 搜索器:它由许多执行搜索的节点组成。
下图描述了索引器和搜索器节点之间倒排索引的生成和传输:
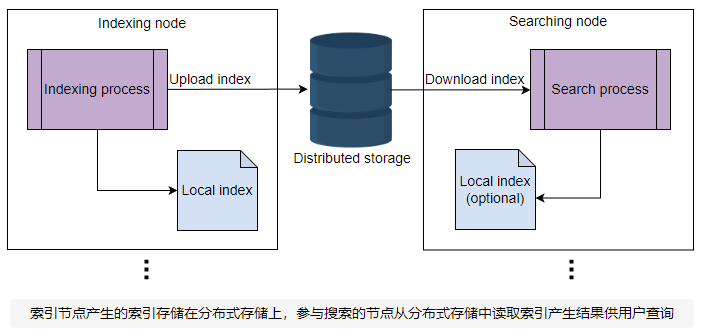
在上图中,为每个索引和搜索操作显示了一个节点。但实际上,会有一个 N 索引阶段的节点数,每个分区(一组文档)一个节点,用于产生倒排索引。倒排索引以二进制文件的形式存储在节点的本地存储中。缓存这些 blob 文件将提高性能。这些二进制文件也被推送到分布式存储。在硬件故障的情况下,将添加新的搜索器或索引机,并从分布式存储中检索数据的副本。
上传完成后,搜索器节点下载索引文件。根据用户搜索模式,搜索节点将维护一个常见查询的缓存并从 RAM 提供数据。用户搜索查询将扩展到所有搜索器节点,这些节点将根据各自的索引生成响应。前端服务器中的合并节点将合并所有搜索结果并将它们呈现给用户。
一旦新文档可用,索引过程就会对其进行索引。同时,搜索器节点获取更新的索引以提供改进的搜索结果。
索引解释
到目前为止,我们已经解释了使用低成本节点开发高度可扩展和高性能的设计。但是,我们不知道索引节点的内部结构。在本节中,我们将了解如何使用 MapReduce 分布式模型和并行处理框架执行索引。
MapReduce 框架 是在集群管理器和一组分类为 Mappers 和 Reducers 的工作节点的帮助下实现的。顾名思义,MapReduce 由两个阶段组成:
- 映射阶段
- 还原阶段
此外,MapReduce 的输入是多个分区或文档集,而其输出是聚合倒排索引。
让我们了解一下上述组件的用途:
- 集群管理器:管理器通过将一组分区分配给映射器来启动该过程。Mappers 完成后,集群管理器将 Mappers 的输出分配给 Reducers。
- 映射器:该组件从集群管理器分配给它的分区中提取和过滤术语。这些机器并行输出倒排索引,作为 Reducers 的输入。
- Reducers:reducer 组合各种术语的映射以生成汇总索引。
集群管理器确保所有工作节点在集群中得到有效利用。MapReduce 是为在部分故障下工作而构建的。如果一个节点出现故障,它会重新安排另一个节点上的工作。
请注意,只要 Mappers 正在工作,Reducers 就无法启动。这意味着集群管理器可以使用与 Mapper 和 Reducer 相同的节点。
下面的幻灯片描述了如何使用 MapReduce 生成倒排索引的简化设置:
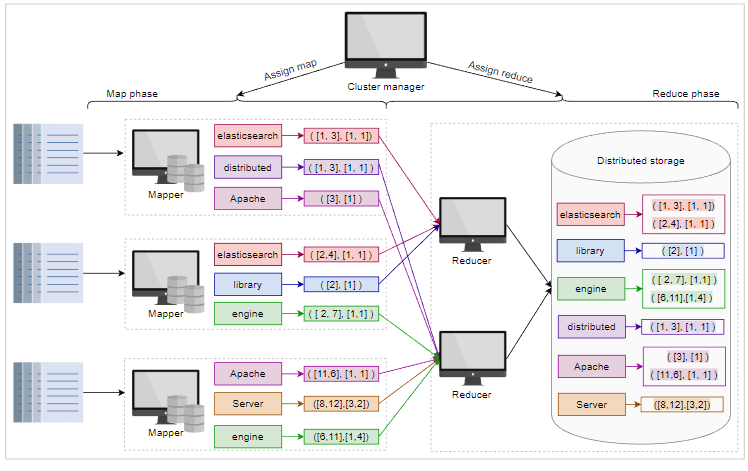
相关信息
集群管理器和文档分区 映射阶段开始,集群管理器将文档分区分配给集群中的空闲节点.我们称这些节点为映射器 映射器从分配的文档中提取术语并生成N个较小的倒排索引 Reduce阶段开始,集群管理器识别出运行Reduce功能的空闲节点,并将工作分配给Reducers reducer 将来自所有映射器的分配术语中的相似术语组合在一起,并将术语的所有条目放在分布式存储中
为了简单起见,我们在上图中只为每个术语显示了两个指标:该术语出现的文档列表和该术语在每个文档中的频率列表(详见索引)。
提示
上面的 MapReduce 设置是实际情况的简化版本。需要 MapReduce 框架的复杂管道来管理现实世界搜索引擎的复杂性。但是,基本原则与我们在此介绍的相同。
摘要
在本课中,我们通过使用专用节点进行索引和搜索,解决了可扩展性(由于共置索引和搜索)和资源浪费(由于索引重新计算)这两个关键问题。这两种操作都依赖于分布式存储。此外,我们还提供了 MapReduce 框架的简化描述,以并行化索引过程。