分布式搜索的设计
概述每秒管理大量查询的分布式搜索系统的设计。
高级设计
在进入详细讨论之前,让我们塑造分布式搜索系统的总体设计。这种系统有两个阶段,如下图所示。离线 阶段 涉及数据爬取和索引,用户无需执行任何操作。 在线阶段 包括根据用户的搜索查询搜索结果。
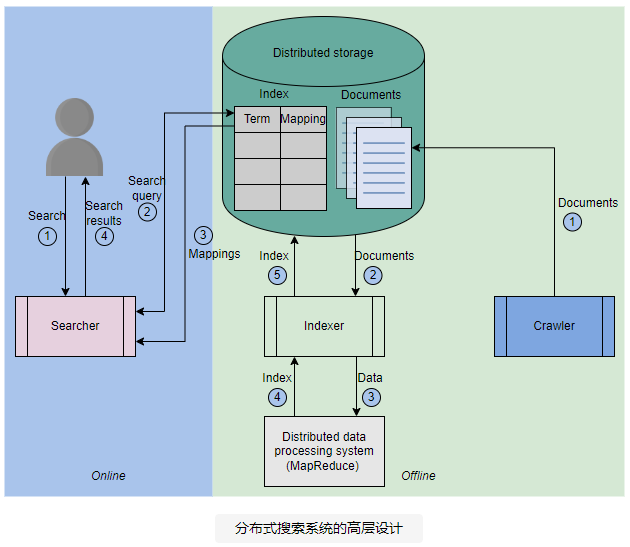
- 爬虫从目标资源中收集内容 。例如 ,如果我们为 YouTube 应用程序构建搜索,爬虫将爬取 YouTube 上的所有视频并提取每个视频的文本内容。内容可以是视频的标题、描述、频道名称,甚至可以是视频的注释,以便不仅可以根据标题和描述,还可以根据视频的内容进行智能搜索。爬虫将提取的每个视频的内容格式化为 JSON 文档,并将这些 JSON 文档存储在分布式存储中。
- 索引器 从分布式存储中获取文档并使用 MapReduce 对这些文档进行索引,MapReduce 在商用机器的分布式集群上运行。索引器使用像 MapReduce 这样的分布式数据处理系统进行并行和分布式索引构建。构建的索引表存储在分布式存储中。
- 分布式存储 用于存储文档和索引。
- 用户在搜索栏中 输入包含多个单词的搜索字符串。
- 搜索器 解析搜索字符串,从存储在分布式存储中的索引中搜索映射,并将最匹配的结果返回给用户。搜索器智能地将搜索字符串中拼写错误的单词映射到最接近的词汇表单词。它还会查找包含所有单词的文档并对它们进行排序。
API设计
由于用户只发送字符串形式的请求,API设计相当简单。
搜索: 该search函数在用户查询系统以查找某些内容时运行。
search(query)
| 范围 | 描述 |
|---|---|
query | 这是用户在搜索栏中输入的文本查询,基于它找到结果。 |
详细讨论
由于索引器是搜索系统的核心组件,我们在上一课中讨论了索引技术以及与集中索引相关的问题。在本课中,我们考虑用于索引和搜索的分布式解决方案。
分布式索引和搜索
让我们看看如何开发分布式索引和搜索系统。我们知道索引系统的输入是我们在抓取过程中创建的文档。为了以分布式方式开发索引,我们使用大量低成本机器(节点)并根据它们拥有的资源对文档进行分区或划分。所有节点都已连接。一组节点称为集群。
提示
为了执行分布式索引,集群中的机器通常具有运行 Linux 的双处理器 x86 处理器,每台机器具有 2-4 GB 的内存。不必所有机器都具有相同的规格,尽管它们应该具有一定的可比性。MapReduce 框架非常智能,可以为更强大的机器提供更多工作。
我们使用大量的小节点进行索引以实现成本效益。这个过程需要我们在这些节点之间划分或拆分输入数据(文档)。但是,需要解决一个关键问题:我们如何执行此分区?
分布式索引中用于数据分区的两种最常用技术如下:
- 文档划分:在文档划分中,网络爬虫收集的所有文档被划分为文档的子集。然后每个节点对分配给它的文档子集执行索引。
- 术语划分:所有术语的字典被划分成子集,每个子集驻留在一个节点上。例如,文档子集由包含术语“搜索”的节点处理和索引。
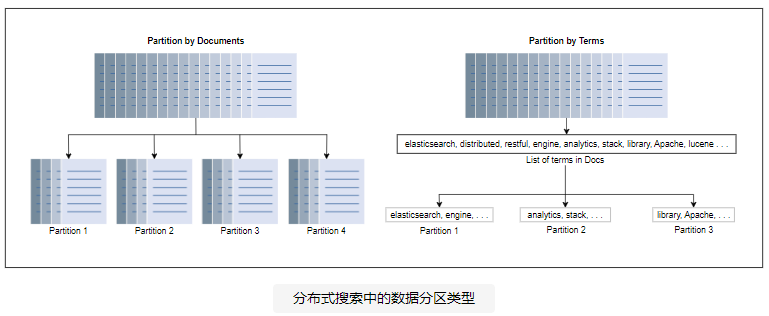
在术语划分中,搜索查询被发送到与查询术语对应的节点。这提供了更多的并发性,因为具有不同查询词的搜索查询流将由不同的节点提供服务。然而,术语划分在实践中被证明是一项艰巨的任务。多词查询需要在节点组之间发送长映射列表以进行合并,这可能比增加并发性带来的好处更昂贵。
在文档分区中,每个查询分布在所有节点上,这些节点的结果在显示给用户之前被合并。这种分区方法需要较少的节点间通信。在我们的设计中,我们使用文档分区。
在文档分区之后,让我们看一下用于索引构建和查询的分布式设计,如下图所示。我们使用一个由许多低成本节点和一个集群管理器组成的集群。集群管理器使用 MapReduce 编程模型来并行化每个分区上的索引计算。MapReduce 可以处理难以由单个大型服务器处理的大得多的数据集。
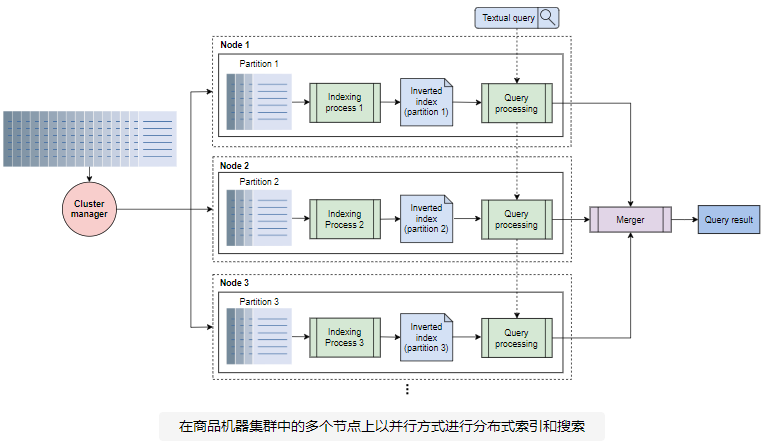
上述系统的工作原理如下:
索引
- 我们有一个已被爬虫收集的文档集。
- 集群管理器将输入文档集拆分为N分区数,其中 N 在上图中等于三。每个分区的大小由集群管理器根据数据大小、计算、内存限制和集群中的节点数量决定。由于各种原因,所有节点可能都不可用。集群管理器通过定期心跳监测每个节点的健康状况。将文档分配给其中一个 N 分区,可以使用散列函数。
- 分区后,集群管理器为所有分区运行索引算法 N 同时分区 N 集群中的节点数。每个索引过程都会产生一个微小的倒排索引,该索引存储在节点的本地存储中。这样,我们生产 N 微小的倒排索引而不是一个大的倒排索引。
搜索中
- 在搜索阶段,当用户查询出现时,我们对存储在节点本地存储中的每个微小倒排索引运行并行搜索,生成 N 个查询。
- 每个反向微型索引的搜索结果是一个针对查询词的映射列表(我们假设单个词/词用户查询)。合并聚合了这些映射列表。
- 聚合映射列表后,合并器根据术语在每个文档中的频率对聚合映射列表中的文档列表进行排序。
- 排序后的文档列表作为搜索结果返回给用户。文档按排序(升序)顺序显示给用户。
相关信息
我们设计了一个搜索系统,我们利用分布式系统并并行化了索引和搜索过程。这有助于我们通过处理较小的文档分区来处理大型数据集。应该注意的是,搜索和索引都是在同一个节点上执行的。我们将这个想法称为托管
提议的设计可行,我们可以在全球各个数据中心复制它,以方便所有用户。因此,我们可以获得以下优势:
- 我们的设计不会受到单点故障 (SPOF) 的影响。
- 所有用户的延迟将保持很小。
- 个别数据中心的维护和升级将成为可能。
- 我们系统的可扩展性(每秒服务更多用户)将得到改善。
复制
我们制作索引节点的副本,为分配的分区生成倒排索引。我们可以用副本回答来自几组节点的查询。整体概念很简单。我们继续使用与以前相同的架构,但我们不再只有一组节点,而是有R节点组来回答用户查询。R是副本的数量。副本的数量可以根据请求的数量扩展或收缩,并且每组节点都具有回答每个查询所需的所有分区。
每组节点都托管在不同的可用性区域,以便在数据中心出现故障时提高系统的性能和可用性。
提示
需要一个负载平衡器组件来将查询分散到不同的节点组,并在出现任何错误时重试。
复制因子和副本分布
通常,复制因子为 3 就足够了。复制因子为三意味着三个节点托管相同的分区并生成索引。三个节点之一成为主节点,而另外两个节点是副本。这些节点中的每一个都以相同的顺序生成索引以收敛于相同的状态。
为了说明,让我们将数据(文档集)分成四个分区。由于复制因子为三,一个分区将由三个节点托管。我们假设有两个可用区( 一个Z1 和 一个Z2 ). 在每个可用区中,我们有两个节点。每个节点仅作为一个分区的主节点(例如,节点 1 中的 一个Z1 是分区的主节点 P1 ). 分区的三个副本(粉色、蓝色和紫色)在两者之间共享 一个Z 实例,以便两个副本位于一个区域中,第三个副本位于另一个区域中。三种颜色代表每个分区的三个副本。例如,下面的分区是正确的是 P4:
- 第一个副本,用粉红色表示,放置在 Z2 的节点2中
- 第二个副本,用蓝色表示,放置在 Z2 的节点1中
- 第三个副本,由紫色表示,放置在 Z1 的节点2中
下图中的每个组都包含来自所有四个分区的一个副本(P1,P2,P3,P4)
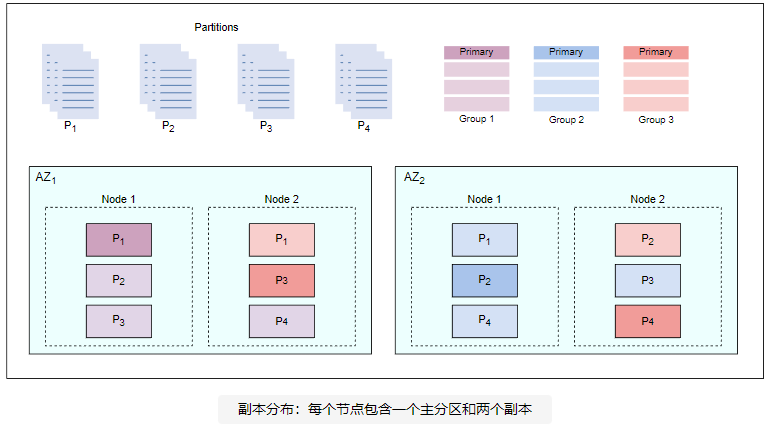
在上图中,P1 的主副本由深紫色表示,P2 的主副本由由深蓝色表示,P3 P4 的主副本由深粉色表示。
现在我们已经完成了复制,让我们看看如何在这些副本中执行索引和搜索。
用副本索引
从上图中,我们假设每个分区都被转发到每个副本以进行索引计算。让我们看一下我们要索引分区的示例 P1 . 这意味着同一个分区将被转发到两个可用区中的所有副本。因此,每个节点将同时计算索引并达到相同的状态。
这种策略的优点是如果主节点发生故障,索引操作不会受到影响。
用副本搜索
我们有每个分区索引的三个副本。负载均衡器选择每个分区的三个副本之一来执行查询。副本数量的增加提高了系统的可扩展性和可用性。现在,系统可以在相同的时间内处理三倍多的查询。
摘要
在本课中,我们学习了如何使用这些策略处理大量数据和大量查询:
- 并行索引和搜索,其中这两个进程都位于相同的节点上。
- 复制每个分区,这意味着我们也复制索引和搜索过程。
我们成功地设计了一个系统,该系统可通过在同一节点上并置的读取(搜索)和写入(索引)操作进行扩展。但是,这种缩放方法带来了一些缺点。我们将在下一课中研究缺点及其解决方案。