分布式搜索中的索引
了解索引及其在分布式搜索中的使用。
我们将首先描述什么是索引,然后我们将着手在许多节点上分布索引。
索引
索引是为了促进快速准确的信息检索而对数据进行的组织和操作。
建立一个可搜索的索引
构建可搜索索引的最简单方法是为每个文档分配一个唯一 ID,并将其存储在数据库表中,如下表所示。表中的第一列是文本的 ID,第二列包含每个文档中的文本。
简单文档索引
| ID | 文件内容 |
|---|---|
| 1个 | Elasticsearch 是基于 REST API 的分布式分析引擎。 |
| 2个 | Elasticsearch 是一个基于 Lucene 库的搜索引擎。 |
| 3个 | Elasticsearch 是一个基于 Apache Lucene 的分布式搜索和分析引擎。 |
上面给出的表格的大小会有所不同,具体取决于我们拥有的文档数量和这些文档的大小。上表只是一个示例,每个文档的内容仅由一两个句子组成。举一个真实的例子,表中每个文档的内容都可能有几页那么长。这将使我们的表非常大。在上面给出的文档级索引上运行搜索查询并不是一个快速的过程。在每个搜索请求中,我们必须遍历所有文档并计算每个文档中搜索字符串的出现次数。
提示
对于模糊搜索,我们还必须执行不同的模式匹配查询。文档中的许多字符串会以某种方式匹配搜索到的字符串。首先,我们必须通过遍历所有文档来找到唯一的候选字符串。然后,我们必须从这些字符串中挑出最接近匹配的字符串。我们还必须找到每个文档中最匹配的字符串的出现。这意味着每个搜索查询都需要很长时间。
搜索查询的响应时间取决于几个因素:
- 数据库中的数据组织策略。
- 数据的大小。
- 用于构建索引和处理搜索查询机器的处理速度和 RAM(运行内存)。
对文档级索引的数十亿文档运行搜索查询将是一个缓慢的过程,可能需要几分钟甚至几小时。让我们看看另一种有助于减少搜索时间的数据组织和处理技术。
倒排索引
倒排索引是一种类似于 HashMap 的数据结构,它使用文档术语矩阵。它不是按原样存储完整的文档,而是将文档拆分为单个单词。在此之后,文档-术语矩阵识别独特的词并丢弃频繁出现的词,如“to”、“they”、“the”、“is”等。像这样经常出现的词被称为术语。文档术语矩阵通过识别唯一单词和删除不必要的术语来维护术语级索引。
对于每个术语,索引计算以下信息:
- 出现该术语的文档列表。
- 术语在每个文档中出现的频率。
- 术语在每个文档中的位置。
倒排索引
| 术语 | 映射**( [文档], [频率], [[位置])** |
|---|---|
| 弹性搜索 | ( [1, 2, 3], [1, 1, 1], [[1], [1], [1]] ) |
| 分散式 | ( [1, 3], [1, 1], [[4], [4]] ) |
| 宁静的 | ( [1], [1], [[5]] ) |
| 搜索 | ( [1, 2, 3], [1, 1, 1], [[6], [4], [5]] ) |
| 分析 | ( [1, 3], [1, 1], [[8], [7]] ) |
| 引擎 | ( [1, 2, 3], [1, 1, 1], [[9], [5], [8]] ) |
| 心 | ( [1], [1], [[12]] ) |
| 松紧带 | ( [1], [1], [[15]] ) |
| 堆 | ( [1], [1], [[16]] ) |
| lucene | ( [2, 3], [1, 1], [[9], [12]] ) |
| 图书馆 | ( [2], [1], [[10]] ) |
| 阿帕奇 | ( [3], [1], [[11]] ) |
在上表中,“术语”列包含从所有文档中提取的所有唯一术语。“映射”列中的每个条目都包含三个列表:
- 出现该术语的文档列表。
- 一个列表,用于计算术语在每个文档中出现的频率。
- 一个二维列表,用于精确定位术语在每个文档中的位置。一个术语可以在单个文档中出现多次,这就是使用二维列表的原因。
提示
除了列表,映射也可以采用元组的形式——例如 doc、freq 和 loc。
倒排索引是文档检索中最流行的索引机制之一。它可以有效地实现boolean、extended boolean、proximity、relevance和许多其他类型的搜索算法。
使用倒排索引的优点
- 倒排索引有助于全文搜索。
- 倒排索引减少了在运行时计算每个文档中单词出现的频率,因为我们有针对每个术语的映射。
使用倒排索引的缺点
- 将倒排索引与实际文档一起维护会产生存储开销。但是,我们减少了搜索时间。
- 添加、更新或删除文档的维护成本(处理)。要添加文档,我们从文档中提取术语。然后,对于每个提取的术语,我们要么在倒排索引中添加一个新行,要么更新现有的行(如果该术语在倒排索引中已经有一个条目)。类似地,对于删除文档,我们在倒排索引中查找已删除文档术语的条目,并相应地更新倒排索引。
从倒排索引中搜索
当我们搜索单词“搜索引擎”时,考虑一个具有以下映射的系统:
| 术语 | 映射 |
|---|---|
| 搜索 | ( [1, 2, 3], [1, 1, 1], [[6], [4], [5]] ) |
| 引擎 | ( [1, 2, 3], [1, 1, 1], [[9], [5], [8]] ) |
这两个词都在文档 1、2 和 3 中找到。这两个词在每个文档中出现一次。
“搜索”在文档 1 中位于位置 6,在文档 2 中位于位置 4,在文档 3 中位于位置 5。
“引擎”一词在文档1中位于第9位,在文档2中位于第5位,在文档3中位于第8位。
一个术语可以出现在数百万个文档中。因此,针对搜索查询返回的文档列表可能会很长。
问题
当针对单个术语找到太多文档时,此技术是否有效?
隐藏答案
返回所有找到的文档可能行不通。相反,我们应该根据与搜索查询的相关性对它们进行排序。应该将排名靠前的结果返回给用户,而不是返回所有文档。
索引设计因素
以下是我们在设计索引时应牢记的一些因素:
- 索引大小:保留索引需要多少计算机内存和 RAM。我们将索引保存在 RAM 中以支持搜索的低延迟。
- 搜索速度:我们可以多快从倒排索引中找到一个词。
- 索引的维护:如果我们添加或删除文档,索引的更新效率如何。
- 容错性:服务保持可靠的重要性。应对索引损坏、支持无效数据是否可以隔离处理、处理有缺陷的硬件、分区和复制都是这里要考虑的问题。
- 弹性:系统对试图玩弄系统并防范搜索引擎优化 (SEO) 方案的人的弹性有多大,因为我们只返回少数相关搜索结果。
鉴于上面列出的设计因素,让我们看一下在中心化系统上构建索引的一些问题。
在集中式系统上建立索引
在 集中式搜索系统 中,所有搜索系统组件都在一个节点上运行,该节点在计算能力上非常强大。集中搜索系统的架构如下图所示:
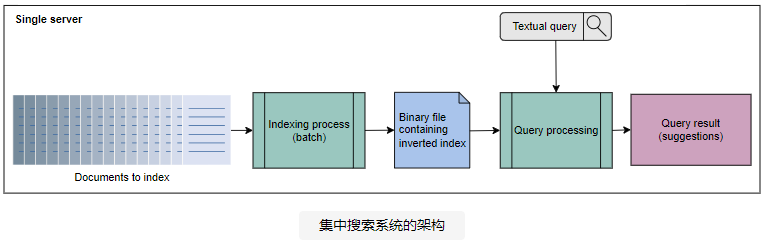
- 索引过程将文档作为输入并将它们转换为倒排索引,以二进制文件的形式存储。
- 查询处理或搜索过程解释包含倒排索引的二进制文件。它还计算给定查询的倒排列表的交集,以返回针对该查询的搜索结果。
这些是中心化搜索系统架构带来的问题:
- SPOF(单点故障)
- 服务器过载
- 索引量大
SPOF:集中式系统是单点故障。如果它死了,则无法执行任何搜索操作。
服务器过载:如果查询用户多,查询复杂,对服务器(节点)造成压力。
大索引:倒排索引的大小随着文档数量的增加而增加,对单个服务器提出了资源需求。计算机系统越大,管理它的成本和复杂性就越高。
相关信息
对于分布式系统,使用低成本的计算机系统,总体上具有成本效益。
添加文档或运行搜索查询时,需要将倒排索引加载到主内存中。为了提高效率,倒排索引的很大一部分必须装入机器的 RAM 中。
根据谷歌分析,2022 年,网页数量达数千亿个,总大小约为 100 PB。如果我们为万维网做一个搜索系统,倒排索引的大小也将以 PB 为单位。这意味着我们必须将 PB 级的数据加载到 RAM 中。增加单台机器的资源来索引十亿页而不是转移到分布式系统并利用并行化的力量是不切实际且低效的。在单个大型倒排索引上运行搜索查询会导致响应时间变慢。
提示
从拥有一百本书的书架中搜索一本书比从拥有一百万本书的书架中搜索一本书更容易。搜索时间随着我们搜索的数据量的增加而增加。
对集中式索引的攻击比对分布式索引系统的攻击具有更大的影响。此外,分布式索引中出现瓶颈的几率(可能出现在服务器带宽或 RAM 中)也较低。
在本课中,我们学习了索引,并研究了集中式系统上的索引问题。下一课介绍索引的分发解决方案。