分布式日志服务的设计
学习如何设计一个分布式日志服务。
现在我们将设计分布式日志系统。我们的日志系统应该记录所有活动或消息(我们将不会将采样能力纳入我们的设计中)。
需求
让我们列出设计分布式日志系统的需求:
功能需求
我们系统的功能需求如下:
- 写日志:分布式系统的服务必须能够写入日志系统中。
- 可搜索的日志:系统应该很容易找到日志。同样,应用程序从端到端的流程也应很容易。
- 存储日志:日志应存储在分布式存储中,以便于访问。
- 集中日志可视化器:系统应提供全球分离服务的统一视图。
非功能需求
我们系统的非功能需求如下:
- 低延迟:记录日志是一种I/O密集型操作,通常比CPU操作慢得多。我们需要设计系统,使记录日志不处于应用程序的关键路径上。
- 可扩展性:我们希望我们的日志系统具有可扩展性。它应该能够处理日志随着时间和并发用户数量的增加而增加的数量。
- 可用性:记录系统应高度可用,以记录数据。
我们将使用的构建块
设计分布式日志系统将利用以下构建块:
- Pub-sub系统:我们将使用Pub-sub系统来处理大量的日志。
- 分布式搜索:我们将使用分布式搜索来高效查询日志。
API设计
此问题的API设计如下:
写入消息
执行写操作的API调用应该像这样:
write(unique_ID, message_to_be_logged)
| 参数 | 描述 |
|---|---|
unique_ID | 它是一个包含应用程序ID、服务ID和时间戳的数字ID。 |
message_to_be_logged | 它是存储在唯一键下的日志消息。 |
搜索日志
搜索数据的API调用应该像这样:
searching(keyword)
此调用返回包含关键字的日志列表。
| 参数 | 描述 |
|---|---|
keyword | 用于查找包含关键字的日志。 |
初始设计
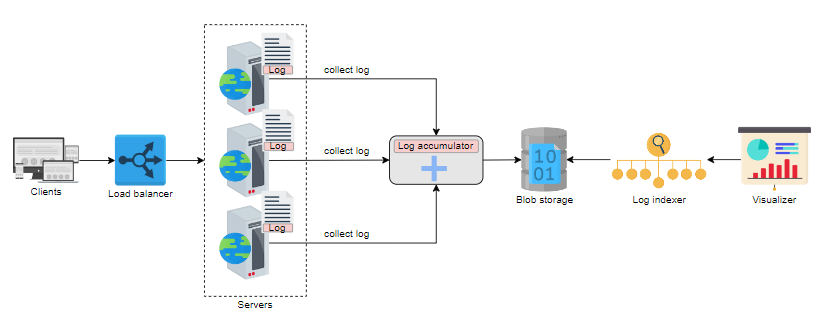
在分布式系统中,全球客户端通过从不同的服务节点请求服务来生成事件。节点在处理每个请求时生成日志。这些日志累积在各自的节点上。
除了构建块外,让我们列出系统的主要组件:
- 日志累加器:从每个节点收集日志并将它们转储到存储器中的代理。因此,如果我们想知道某个特定事件,我们不需要访问每个节点,我们可以从我们的存储器中获取它们。
- 存储器:日志需要在累加后存储在某个地方。我们将选择Blob存储器来保存我们的日志。
- 日志索引器:日志文件数量的增加影响了搜索能力。日志索引器将使用分布式搜索来高效搜索。
- 可视化器:可视化器用于提供所有日志的统一视图。
该方法的设计如下:
在分布式系统中有数百万个服务器,使用单个日志累加器严重影响可扩展性。让我们学习如何扩展我们的系统。
在不同层级上的日志记录
让我们探索不同层级上日志系统的工作方式。
在服务器上
在本节中,我们将学习不同应用程序中的各种服务如何登入服务器。
假设我们在服务器上有多个不同的应用程序,例如App 1、App 2等。每个应用程序也有多个微服务正在运行。例如,电子商务应用程序可以同时运行验证用户、获取购物车等服务。每个服务都会产生日志。我们通过带有application-id、service-id和时间戳的ID来唯一标识多个应用程序的各种服务。时间戳可帮助我们确定事件的因果关系。
每个服务将将其数据推送到日志累加器服务。它负责以下操作:
- 接收日志。
- 将日志存储在本地。
- 将日志推送到发布-订阅系统。
我们使用发布-订阅系统来解决可扩展性问题。现在,每个服务器都有其自己的日志累加器(或多个累加器)将数据推送到发布-订阅系统。发布-订阅系统能够管理大量的日志。
为了满足低延迟的另一个要求,我们不希望日志记录影响其他进程的性能,因此我们通过低优先级线程异步发送日志。通过这样做,我们的系统不会干扰其他进程的性能,同时确保可用性。
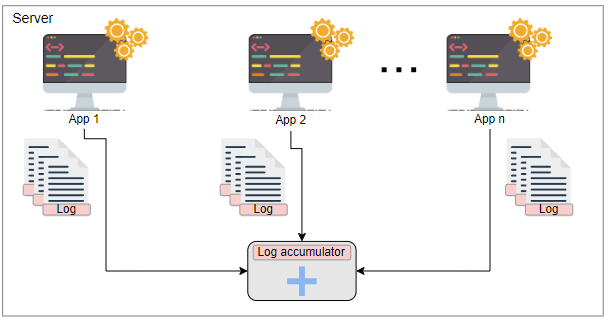
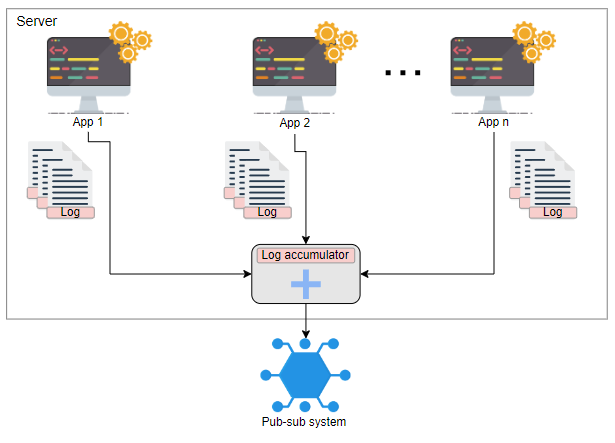
我们应该注意到在记录大量消息的过程中可能会丢失数据。在用户感知的延迟和保证日志数据持久性之间存在权衡。为了降低延迟,日志服务通常会将数据保留在RAM中,并异步地将其持久化。此外,通过添加冗余的日志累加器来处理不断增长的并发用户,我们可以最大程度地减少数据丢失。
问题:
在多租户云(如AWS)上托管服务时,日志记录如何发生变化,而当组织控制基础设施时(如Facebook)又如何,特别是在日志方面?
答案:
安全性可能是多租户和单租户设置之间不同的方面。当我们对所有日志进行加密并在端点到端点上保护日志服务时,这不是免费的,并且会有性能损失。此外,对于多租户设置,需要对日志进行严格分离,而对于单租户设置,我们可以提高存储和处理利用率。
让我们以Facebook的Meta为例。他们有数百万台机器产生日志,它的大小可以达到几PB每小时。因此,每台机器将其日志推送到一个名为Scribe的发布-订阅系统中。Scribe会将数据保留几天,并且各种其他系统会处理驻留在其中的数据。他们还将日志存储在分布式存储中。管理日志可以是应用程序特定的。
另一方面,对于多租户情况,我们需要为每个租户(或每个应用程序)使用单独的发布-订阅实例来严格分离日志。
提示
对于银行和金融应用程序等应用程序,日志必须非常安全,以确保黑客无法窃取数据。通常的做法是对数据和日志进行加密。通过这种方式,没有人可以使用日志中的数据解密加密信息。
在数据中心层次上
数据中心中的所有服务器都将日志推送到一个发布-订阅系统中。由于我们使用的是水平可扩展的发布-订阅系统,因此可以处理大量的日志数据。我们可以在每个数据中心使用多个发布-订阅实例。这使得我们的系统具有可扩展性,可以避免瓶颈问题。然后,发布-订阅系统将数据推送到 Blob 存储中。
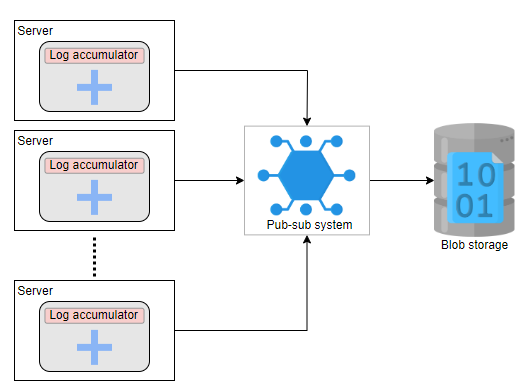
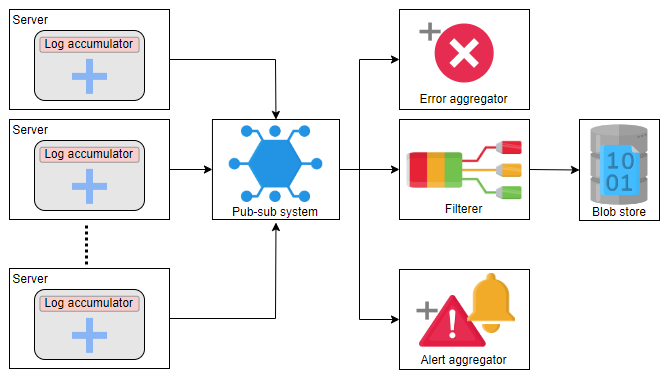
数据不会永远驻留在发布-订阅系统中,并且在存储到归档存储之前的几天内被删除。但是,在可用的发布-订阅系统中使用这些数据是可以的。以下服务将处理发布-订阅数据:
- 过滤器:它识别应用程序并将日志存储在为该应用程序保留的 Blob 存储中,因为我们不想混合两个不同应用程序的日志。
- 错误汇总器:尽快识别错误非常重要。我们使用一个服务从发布-订阅系统中提取错误消息,并通知相应的客户端。这样,我们就不必搜索日志了。
- 警报汇总器:警报也很关键。因此,尽早了解它们非常重要。该服务识别警报并在遇到严重错误时通知适当的利益相关者,或者向监控工具发送消息。
以下是更新的设计:
问题:我们对日志进行终身存储吗?
答案:日志也有一个过期日期。我们可以在几天或几个月后删除常规日志。合规性日志通常存储三到五年。这取决于应用的要求。
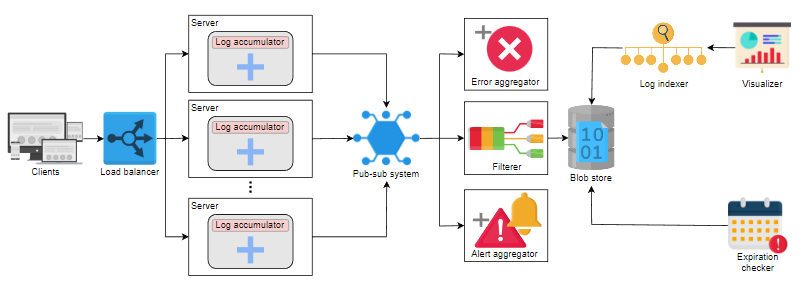
在我们的设计中,我们还确定了另一个组件,称为 过期检查器。它负责以下任务:
- 验证要删除的日志。
- 验证存储在冷存储库中的日志。
此外,我们的组件日志索引器和可视化器在 Blob 存储中工作,为最终用户提供良好的搜索体验。下面是日志服务的最终设计:
问题:
我们之前学习过,对于一个简单的用户级 API 调用一个大型服务可能涉及数百个内部微服务和数千个节点。如何按照完整性将一条请求的日志从端到端连接起来?
答案:
大多数复杂的服务使用前端服务器来处理最终用户的请求。一旦接收到请求,前端服务器可以使用一个序列号获得一个唯一标识符。此唯一标识符将附加到所有扇出的服务中。系统中任何地方生成的每条日志消息也会发出唯一标识符。
稍后,我们可以根据唯一标识符过滤日志(或进行预处理)。此步骤可以将特定请求的所有日志跨微服务进行收集。在序列器构建块中,我们讨论了可以获取保持发生在前面的时刻关系的唯一标识符。这种标识符具有的属性是,如果 ID1 小于 ID2,则 ID1 表示在 ID2 之前发生的时间。现在,每个日志条目都可以使用一个时间戳,并且我们可以按升序对特定请求的日志条目进行排序。
将日志按照时间(或因果关系)正确排序简化了日志分析过程。
提示
Windows Azure Storage System (WAS) 在其开发中使用了一个广泛的日志记录基础设施。它将日志存储在本地磁盘中,由于日志数量庞大,他们并不将日志推送到分布式存储中。相反,他们使用类似于 grep 的实用程序作为分布式搜索。通过这种方式,他们可以获得全球分布式日志数据的统一视图。
设计分布式日志记录服务的方式可能有很多种,但它完全取决于我们应用的要求。
结论
- 我们了解了在理解分布式系统事件流中日志记录的重要性。它有助于通过引导我们找到问题的根本原因来减少修复时间(MTTR)。
- 日志记录是一项 I/O 密集型操作,需要耗费大量时间和精力。因此,必须小心处理,不能影响其他服务执行的关键路径。
- 日志记录对监控至关重要,因为从日志中获取的数据有助于监视应用程序的健康状况(警报和错误汇总器可以实现此目的)。