分布式日志介绍
学习为什么在分布式系统中需要进行日志记录。
分布式系统中的日志记录
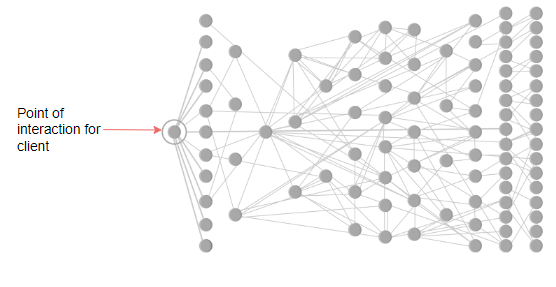
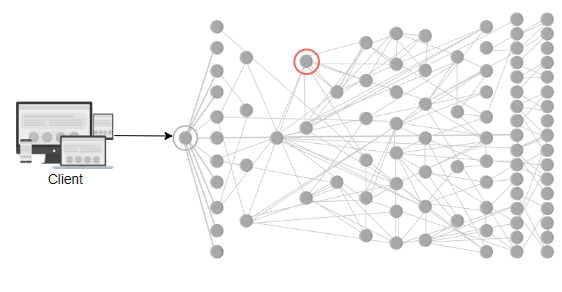
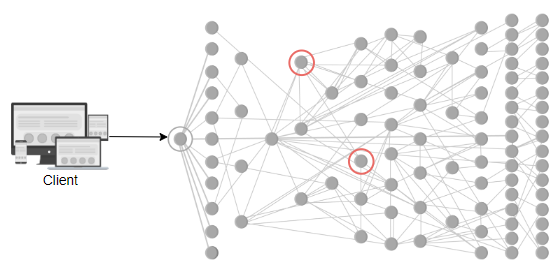
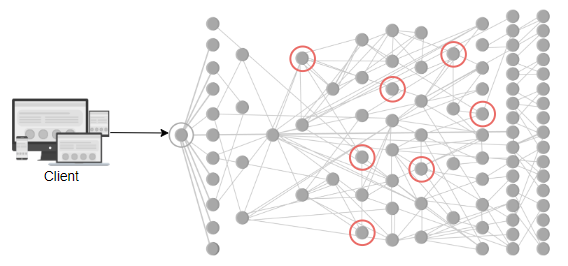
在当今世界中,越来越多的设计采用微服务架构而不是单片架构。在微服务架构中,每个微服务的日志会累积在各自的机器上。如果我们想了解某个由多个微服务处理的事件,就很难进入每个节点,找出流程并查看错误消息。但是,如果我们能够跟踪任何特定流程的日志从头到尾,就会变得方便。
此外,微服务不一定只部署在一个节点上。它可以部署在成千上万的节点上。考虑以下例子,其中数百个微服务是相互依赖的,一个服务的故障可能会导致其他服务的故障。如果没有日志,我们可能无法确定故障的根本原因。这强调了日志记录的必要性。

限制日志大小
日志的数量随时间增加。一次可能需要记录数百个并发消息。但问题是,它们全部都值得记录吗?为了解决这个问题,必须对日志进行结构化处理。我们需要决定在应用程序或日志级别上要记录到系统中的内容。
使用采样
在这种方法中,我们将确定应该记录哪些消息到系统中。考虑这样一种情况,在这种情况下,我们有许多来自同一组事件的消息。例如,有人在评论一篇文章,其中个人X评论了个人Y的文章,然后个人Z评论了个人Y的文章,依此类推。我们可以使用采样器服务,只从更大的块中记录较小的消息集合。这样,我们就可以决定记录最重要的消息。
提示
对于像Facebook这样的大型系统,每秒可能会发生数十亿个事件,无法全部记录它们。必须选择适当的采样阈值和策略,以选择性地选择代表性数据集。
我们还可以对消息类型进行分类,并应用一个过滤器,以识别重要的消息,并仅将它们记录到系统中。
问题:采样方法不适用的场景是什么?
解答:让我们考虑一种处理金融ATM交易的应用程序。它运行各种服务,例如欺诈检测、到期时间检查、卡验证等等。如果我们开始省略任何服务的日志记录,我们不能识别影响调试的端到端流程,并且这样使用采样是不理想的,并导致丢失有用的数据。
使用分类
让我们看看各种编程语言提供的日志记录支持。例如,有log4j和Python中的logging。以下严重级别通常用于日志记录:
DEBUGINFOWARNINGERRORFATAL/CRITICAL
通常,产品日志设置为打印严重性为WARNING及以上的消息。但是,为了获得更详细的流程,可以将严重级别设置为DEBUG和INFO级别。点击“运行”按钮,查看使用Python的日志记录库打印日志的示例的执行情况。
日志结构
应用程序可以选择其日志数据的结构。例如,应用程序可以自由地将日志记录为二进制或文本数据,但是强制对日志进行一些结构化处理通常会更有帮助。结构化日志的第一个好处是更好的日志编写者和读者之间的互操作性。其次,结构可以使日志处理系统的工作更容易。
提示
注意:对日志的结构化处理本身是一个密集的主题。我们将有兴趣的学习者转到Ryan Braud的博士学位论文“基于查询的分布式系统调试”中。
适用于分布式系统的基于查询的调试系统--论文](https://escholarship.org/uc/item/2p06d5sv)
记录日志时应考虑的要点
记录日志时我们应该小心谨慎。记录信息应只包含相关信息,而不会违反安全问题。对于安全数据,我们应该记录加密数据。记录日志时,考虑以下几点:
- 避免记录个人身份信息(PII),如名称、地址、电子邮件等。
- 避免记录敏感信息,如信用卡号、密码等。
- 避免过度信息记录。记录所有信息是不必要的。这只会占用更多的空间并影响性能。由于记录日志是一个I/O密集型操作,因此有其性能惩罚。
- 记录机制应该是安全的而不容易受到攻击,因为日志包含应用程序的流,不安全的日志机制容易受到黑客的攻击。
记录基础设施的漏洞
最近,Java中著名的日志框架Log4j中发现了一个零日漏洞。从2013年以来,Log4j一直存在隐藏的漏洞Log4Shell(CVE-2021-44228)。Apache给Log4Shell赋予了最高的CVSS严重性评分10。这个漏洞很容易实施,并影响了数亿设备。安全专家相信,这个漏洞可以允许对国际网络发起灾难性的网络攻击,因为它可以使攻击者运行恶意代码并控制机器。