分布式缓存的高级设计
了解我们如何开发分布式缓存的高级设计。
在本课中,我们将学习设计分布式缓存。我们还将讨论在开发解决方案的过程中可能发生的权衡和设计选择。
要求
让我们首先了解我们的解决方案的要求。
功能
以下是功能要求:
- 插入数据:使用分布式缓存系统的用户必须能够向缓存中插入一个条目。
- 检索数据:用户应该能够检索与特定键对应的数据。
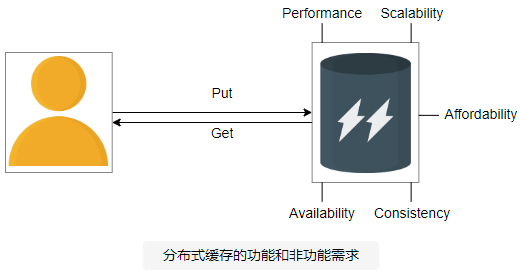
非功能性需求
我们将考虑以下非功能性需求:
- 高性能:缓存的主要原因是能够快速检索数据。因此,
insert和retrieve操作都必须很快。 - 可扩展性:缓存系统应该水平扩展,在请求数量增加时不会出现瓶颈。
- 高可用性:缓存的不可用性会给数据库服务器带来额外的负担,它也可能在高峰负载间隔下降。我们还要求我们的系统能够承受组件和网络偶尔出现的故障以及断电。
- 一致性:存储在缓存服务器上的数据应该是一致的。例如,从不同缓存服务器(主要或次要)检索相同数据的不同缓存客户端应该是最新的。
- 可承受性:理想情况下,缓存系统应该从商品硬件而不是系统设计中昂贵的支持组件来设计。
API设计
这个问题的 API 设计非常简单,因为只有两个基本操作。
插入
执行插入的 API 调用应如下所示:
insert(key, value)
| 范围 | 描述 |
|---|---|
key | 这是一个唯一标识符。 |
value | 这是针对唯一存储的数据key。 |
此函数返回描述服务器端问题的确认或错误。
检索
从缓存中检索数据的 API 调用应如下所示:
retrieve(key)
| 范围 | 描述 |
|---|---|
key | 这将返回针对key. |
这个调用返回一个对象给调用者。
指向思考
问题
分布式缓存的 API 设计看起来与键值存储非常相似。键值存储和分布式缓存之间可能存在哪些区别?
一些主要区别如下:
- 键值存储需要持久存储数据(持久性)。除了持久存储之外,还使用缓存来提高读取性能。
- 缓存提供来自 RAM 的数据。键值存储将数据写入非易失性存储。
- 键值存储是健壮的,应该能经受住失败。但是,缓存可能会崩溃并在恢复后从头开始填充。
设计注意事项
在设计分布式缓存系统之前,考虑一些设计选择很重要。这些选择中的每一个都将完全基于我们的应用程序要求。但是,我们可以在这里强调一些关键差异:
存储硬件
如果我们的数据很大,我们可能需要分片,因此使用分片服务器进行缓存分区。这些分片服务器应该是专用硬件还是商用硬件?专用硬件将具有良好的性能和存储容量,但成本更高。我们可以从商用服务器构建一个大型缓存。一般来说,分片服务器的数量取决于缓存的大小和访问频率。
此外,我们可以考虑将我们的数据存储在这些服务器的辅助存储上以实现持久性,同时我们仍然从 RAM 提供数据。二级存储可用于重启,缓存重建时间较长的情况。但是,如果存在专用的持久层(例如数据库),则缓存系统可能不需要持久性。
数据结构
访问数据的速度是设计的一个重要部分。哈希表是平均需要固定时间来存储和检索数据的数据结构。此外,我们需要另一种数据结构来对缓存数据执行逐出算法。特别是,链表是一个不错的选择(如上一课所述)。
另外,我们需要了解缓存可以存储什么样的数据结构。尽管我们在 API 设计部分讨论过为简单起见我们将使用字符串,但可以在缓存中存储不同的数据结构或格式,如哈希映射、数组、集合等。在下一课中,我们将看到此类缓存的实际示例。
缓存客户端
它是放置insert和retrieve调用的客户端进程或库。客户端进程的位置是一个设计问题。例如,如果缓存仅供内部使用,则可以将客户端进程放在服务主机中。否则,在缓存系统作为服务提供给外部使用的情况下,专用的缓存客户端可以将用户的请求发送到缓存服务器。
编写策略
缓存和数据库的写入策略具有一致性影响。一般来说,没有最佳选择,但根据我们的应用程序,写入策略的偏好非常重要。
驱逐政策
按照设计,缓存提供低延迟读取和写入。为实现这一点,数据通常由 RAM 内存提供。通常,由于与完整数据集相比缓存的大小有限,我们不能将所有数据都放入缓存中。因此,我们需要仔细决定缓存中保留的内容以及如何为新条目腾出空间。
随着新数据的添加,一些现有数据可能必须从缓存中逐出。但是,选择受害者条目取决于逐出策略。存在许多驱逐策略,但选择又取决于使用它的应用程序。例如,最近最少使用 (LRU) 可能是社交媒体服务的不错选择,因为最近上传的内容可能会获得最多的浏览量。
除了上述部分的详细信息外,优化生存时间 (TTL) 值可以在减少缓存未命中数方面发挥重要作用。
高层设计
下图描述了我们的高级设计:
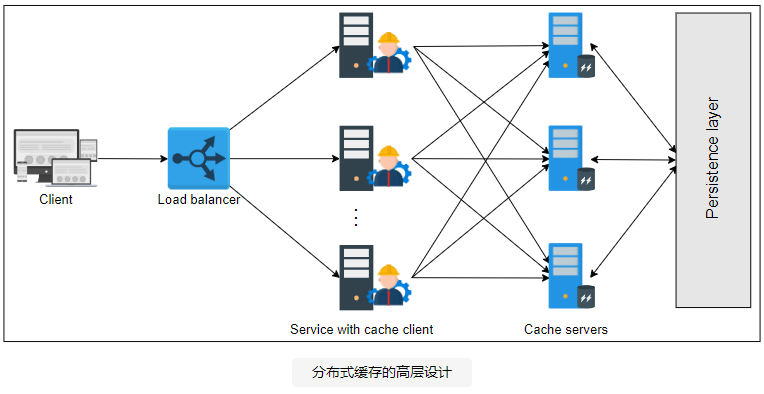
此高级设计中的主要组件如下:
- 缓存客户端:该库驻留在服务应用程序服务器中。它包含有关缓存服务器的所有信息。
insert缓存客户端将为每个传入和请求使用散列和搜索算法选择其中一个缓存服务器retrieve。所有缓存客户端都应该具有所有缓存服务器的一致视图。此外,将数据移入和移出缓存服务器的解析技术应该相同。否则,不同的客户端会向不同的服务器请求相同的数据。 - 缓存服务器:这些服务器维护数据的缓存。每个缓存服务器都可以被所有缓存客户端访问。每个服务器都连接到数据库以存储或检索数据。缓存客户端使用 TCP 或 UDP 协议与缓存服务器进行数据传输。但是,如果任何缓存服务器关闭,对缓存服务器的请求将被缓存客户端解析为丢失的缓存。