系统设计:分布式缓存
了解分布式缓存的基础知识。
问题陈述
一个典型的系统由以下组件组成:
- 它有一个请求服务的客户端。
- 它有一个或多个服务主机来处理客户请求。
- 它有一个数据库,供服务用于数据存储。
在正常情况下,这种典型的系统表现良好。但是,随着用户数量的增加,对数据库的操作频率也会增加。随着这种频率的增加,数据库的压力不断加大,从而导致性能下降。
在这种情况下,系统会添加缓存以应对性能下降。缓存是一种临时数据存储,它可以通过将数据条目保存在内存中来更快地给用户提供数据。缓存只存储最常访问的数据。当请求到达服务主机时,它会从缓存中检索数据(缓存命中)并为用户提供服务。但是,如果数据在缓存中不可用(缓存未命中),则会从数据库中查询数据。此外,缓存会填充新值以避免下次缓存未命中。
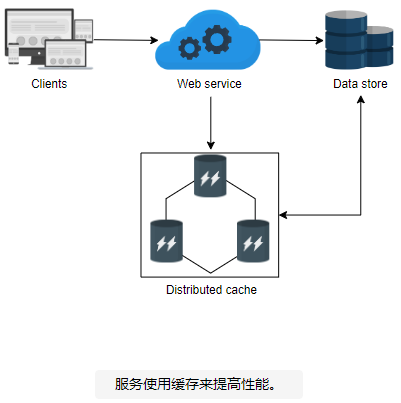
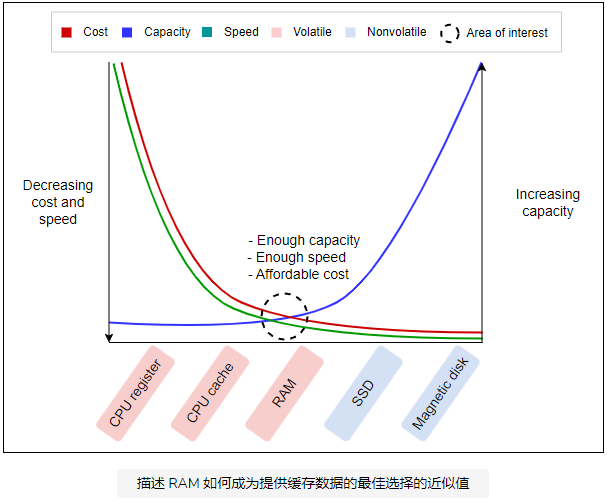
缓存是一种非持久性存储区域,用于保存重复读写的数据,为用户提供更低的感知延迟。因此,缓存必须提供来自存储组件的数据,该存储组件速度快、存储空间充足,并且在我们扩展缓存服务时在经济成本方面可以负担得起。下图突出显示了 RAM 作为缓存的原始构建块的适用性:
我们知道需要缓存和合适的存储硬件,但什么是分布式缓存?我们接下来讨论这个。
什么是分布式缓存?
分布式缓存是一种缓存系统,其中会有多个缓存服务器协调存储频繁访问的数据。在单个缓存服务器不足以存储所有数据的情况下需要构建分布式缓存系统。同时,它具有可扩展性并保证了更高程度的可用性。
缓存通常很小,是一种访问频繁,读取时间快的短期存储。缓存使用 局部引用原则。
一般来说,分布式缓存有以下几个好处:
- 它们通过预先计算结果和存储经常访问的数据来最大限度地减少用户感知的延迟。
- 他们从数据库中预先生成基础的数据条目。
- 它们临时存储用户会话数据。
- 即使数据存储暂时关闭,它们也会从临时存储中提供数据。
- 最后,它们通过从本地资源提供数据来降低网络成本。
为什么使用分布式缓存?
当缓存中所需数据的数量增加时,将整个数据存储在一个系统中是不切实际的。这是因为以下三个原因:
- 它可能是潜在的单点故障 (SPOF)。
- 系统是分层设计的,每一层都应该有自己的缓存机制,保证不同层敏感数据的解耦。
- 在不同位置缓存有助于减少该层的服务延迟。
在下表中,我们描述了如何通过使用各种技术来执行不同层的缓存。重要的是要了解键值存储组件在各个层中使用。
在系统的不同层缓存
| 系统层 | 使用中的技术 | 用法 |
|---|---|---|
| 网络 | HTTP 缓存标头、Web 加速器、键值存储、CDN 等 | 加速静态 Web 内容的检索并管理会话 |
| 应用 | 本地缓存和键值数据存储 | 加速应用级计算和数据检索 |
| 数据库 | 数据库缓存、缓冲区和键值数据存储 | 减少数据检索延迟和降低数据库的 I/O 负载 |
提示
除了上述三个系统层之外,缓存还在 DNS 和客户端技术(如浏览器或终端设备)中执行。
我们将如何设计分布式缓存?
我们将设计和强化学习分布式缓存主要概念的任务分为五个课程:
- 分布式缓存的背景:在设计分布式缓存时,必须构建做出关键决策所需的背景知识。本课将重温一些基本但重要的概念。
- 分布式缓存的高级设计:我们将在本课中构建分布式缓存的高级设计。
- 分布式缓存的详细设计:我们将确定我们的高级设计的一些局限性,并致力于实现可扩展、价格合理且高性能的解决方案。
- 分布式缓存设计的评估:本课将评估我们的设计是否满足各种非功能性需求,例如可伸缩性、一致性、可用性等。
- Memcached 与 Redis:我们将讨论著名的工业解决方案,即 Memcached 和 Redis。我们还将详细了解它们并比较它们的功能,以帮助我们了解它们的潜在用例以及它们与我们的设计的关系。
让我们在下一课开始探索分布式缓存的背景。