监控系统的详细设计
学习监控系统的详细设计,了解其优缺点。
我们将讨论监控系统的核心组件,确定我们设计的不足之处,并改进设计以满足我们的要求。
存储
我们将使用时序数据库将数据保存在运行监控服务的服务器上。然后,我们将与一个单独的存储节点集成。我们将使用 blob 存储来存储我们的指标。
我们需要存储指标并知道如果一个指标达到特定的值,该采取哪些操作。例如,如果 CPU 使用率超过90%,我们会向最终用户生成警报,以便警报接收器可以采取必要的步骤,例如分配更多资源以进行扩展。
为此,我们需要另一个存储区域,其中将包含规则和操作。让我们称其为规则数据库。在违反规则时,我们可以采取适当的行动。
在这里,我们确定了设计中的另外两个组件,即规则和操作数据库和存储节点(blob 存储)。
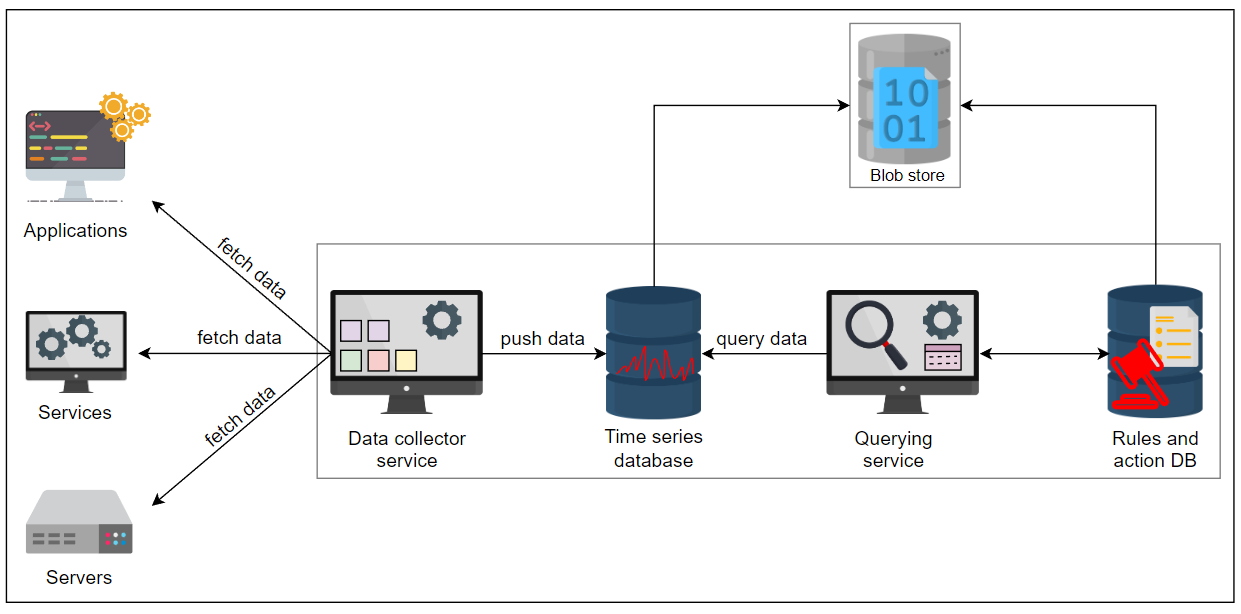
添加 Blob 存储和规则和操作数据库
数据收集器
我们需要一个监控系统来更新我们的几个数据中心。如果我们的进程的信息到达我们,我们就可以保持更新,这可以通过日志记录实现。
我们将选择拉取策略。然后,我们将从应用程序的日志中提取相关指标。如我们在日志设计中讨论的那样,我们使用了分布式消息队列。
队列中的消息具有服务名称、ID 和日志的简短描述。这将帮助我们识别特定服务的指标及其信息。
将相关指标暴露给数据收集器对于监控任何服务都是必要的,以便我们的数据收集器可以从服务中获取指标并将其存储到时序数据库中。
基于拉取策略的监控系统的真实世界示例是 DigitalOcean。它监控了分布在全球的数百万台机器。
警告
问题
使用推送式方法的一些缺点是什么?
答案
推送式监控工具从应用程序和服务器收集指标数据并将其发送到集中式收集平台。每个微服务都将其指标发送到监控系统,这会对基础架构造成沉重的流量负载。这就是监控可能成为业务操作的瓶颈的原因。监控可以是几乎实时的。然而,如果不采取适当的措施,它可能会以持续的推送请求从所有服务来,导致网络洪水。我们还必须在每个目标上安装守护程序以将指标发送到监控服务器,这需要额外的工作.
服务发现器
数据收集器负责从它监视的服务中获取指标。这样,监控系统就不需要跟踪服务。相反,它可以使用发现器服务找到它们。我们将保存我们要监视的服务的相关信息。我们将使用服务发现解决方案,并与 EC2、Kubernetes 和 Consul 等多个平台和工具进行集成。这将允许我们发现我们必须监视哪些服务。类似的动态发现也可以用于新委托的硬件。
让我们将我们新确定的组件添加到现有的设计中。
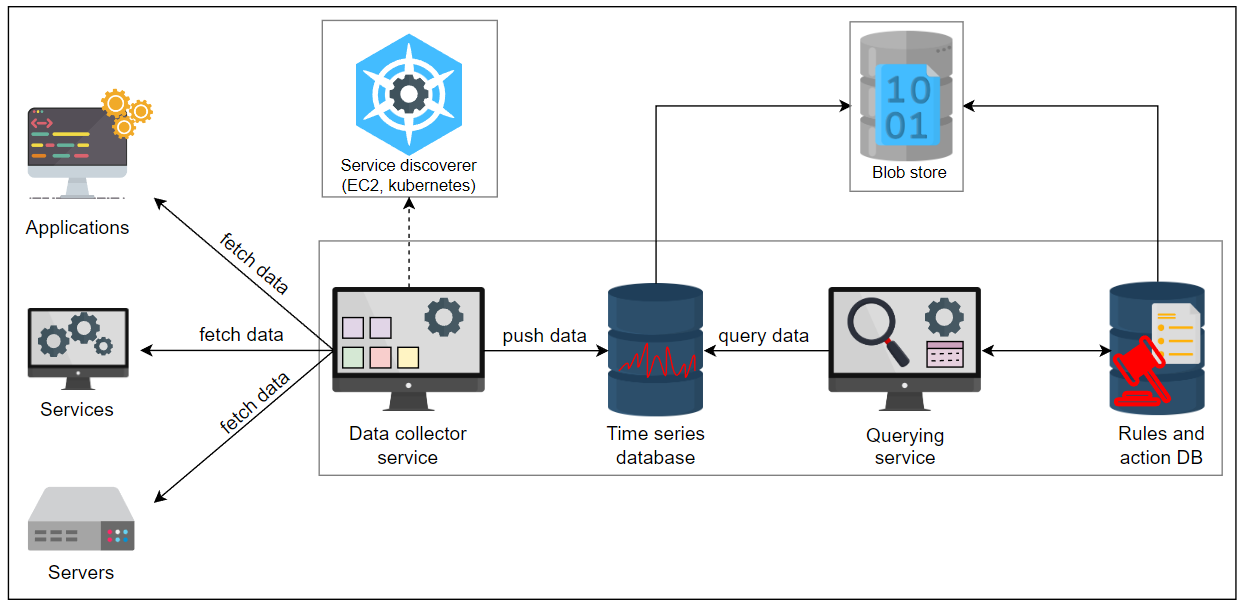
添加服务发现器
查询服务
我们想要一个服务来访问数据库并获取相关的查询结果。我们需要这个是因为我们想要查看像特定节点的内存使用值这样的错误,或者在指标超过设定限制时发送警报。让我们添加我们需要的两个组件以及查询。
警报管理器
警报管理器负责在违反设定规则时发送警报。它可以发送电子邮件、Slack 消息等警报。
仪表板
我们可以使用收集的指标设置仪表板,显示所需的信息,例如当前一周的请求数量。
让我们添加上面讨论的组件,这样就完成了我们的监控系统设计。
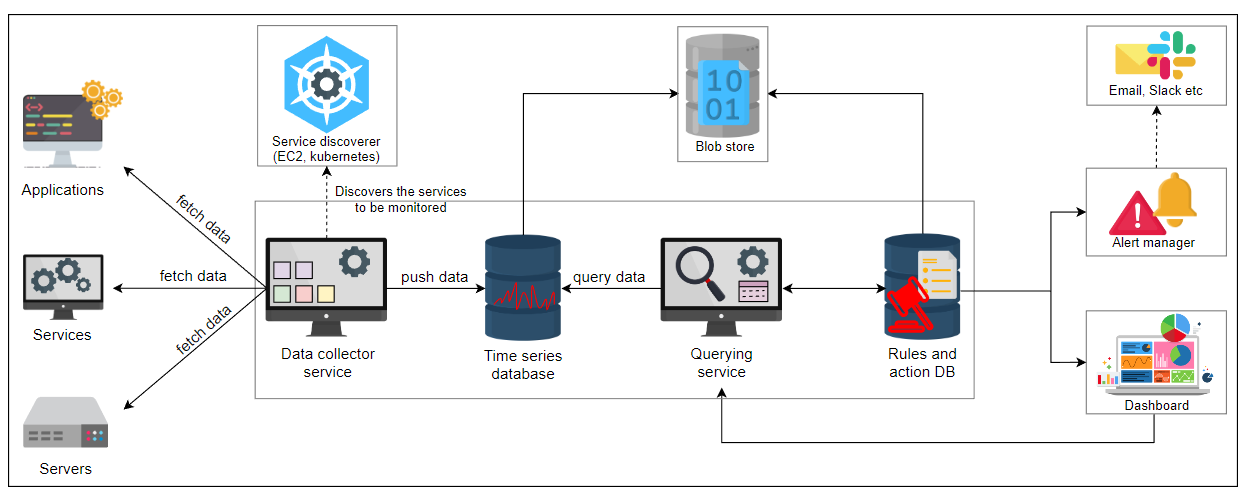
监控系统的详细设计
我们的一体化监控服务适用于积极跟踪系统和服务。它收集和存储数据,并支持搜索、图形和警报。
优点
- 我们的监控服务设计确保运营顺畅,并关注即将出现的问题的迹象。
- 我们的设计通过自己获取数据避免了网络流量过载。
- 监控服务提供更高的可用性。
缺点
- 系统似乎是可扩展的,但管理更多的服务器进行监控可能会成为一个问题。例如,我们有一个专用的服务器负责运行监控服务。它可能是一个单点故障(SPOF)。
- 为了解决 SPOF 问题,我们可以为监控系统设置故障转移服务器。然后,我们还需要在实际服务器和故障转移服务器之间保持一致性。
- 然而,随着服务器数量的进一步增加,这样的设计也会达到可扩展性的极限。
- 监控每天24/7收集大量数据,将其永久保留可能不可行。我们需要一个政策和机制来定期删除不需要的数据,以有效利用资源。
让我们想一种方法来克服我们监控服务的问题。
改进我们的设计
我们希望改进我们的设计,使我们的系统可以更好地扩展,并决定保留哪些数据和删除哪些数据。让我们看看推送式方法如何工作。在推送式方法中,应用程序将其数据推送到监控系统。
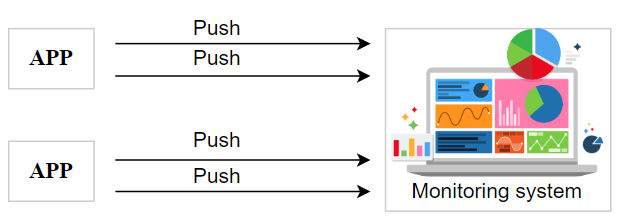
推送式监控系统
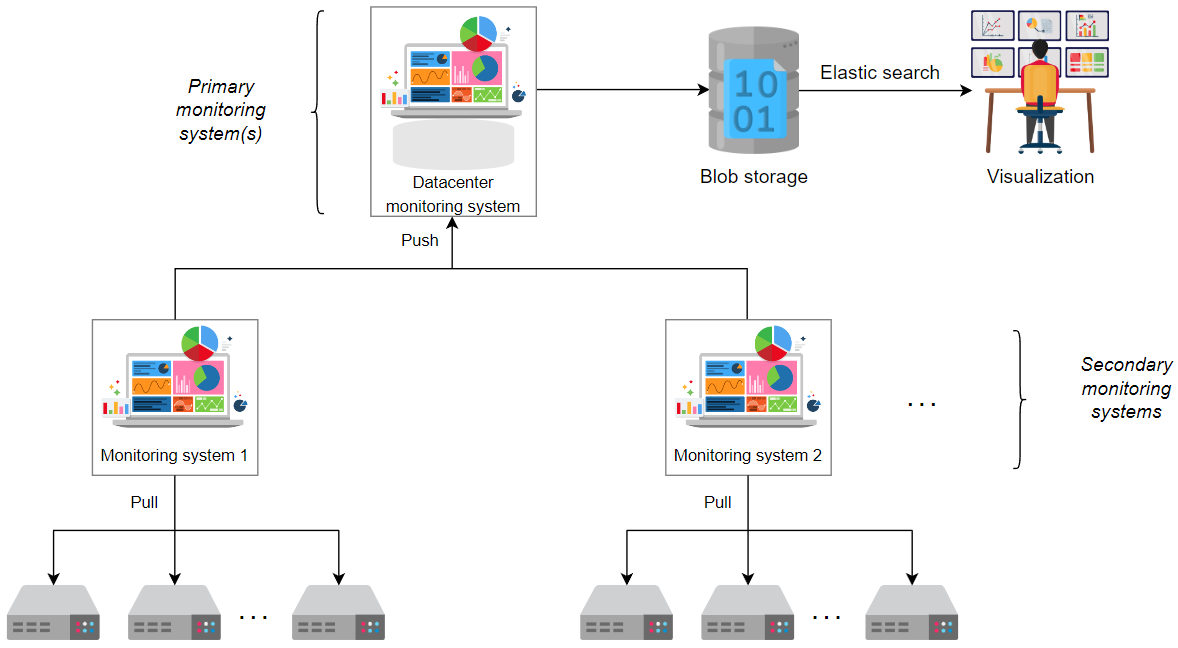
我们使用拉取策略来避免网络拥堵。这也使应用程序免于必须将相关监控数据发送到系统的方面。相反,监控系统会自己获取或拉取数据。为了满足扩展需求,我们也需要应用推送式方法。我们将使用混合方法,将我们的拉取策略与推送策略相结合。
我们将继续使用拉取策略来监视数据中心内的多个服务器。我们还将为数据中心内的数百或数千台服务器分配多个监控服务器——假设一个服务器监控 5,000 台服务器。我们将称它们为次要监控服务器。
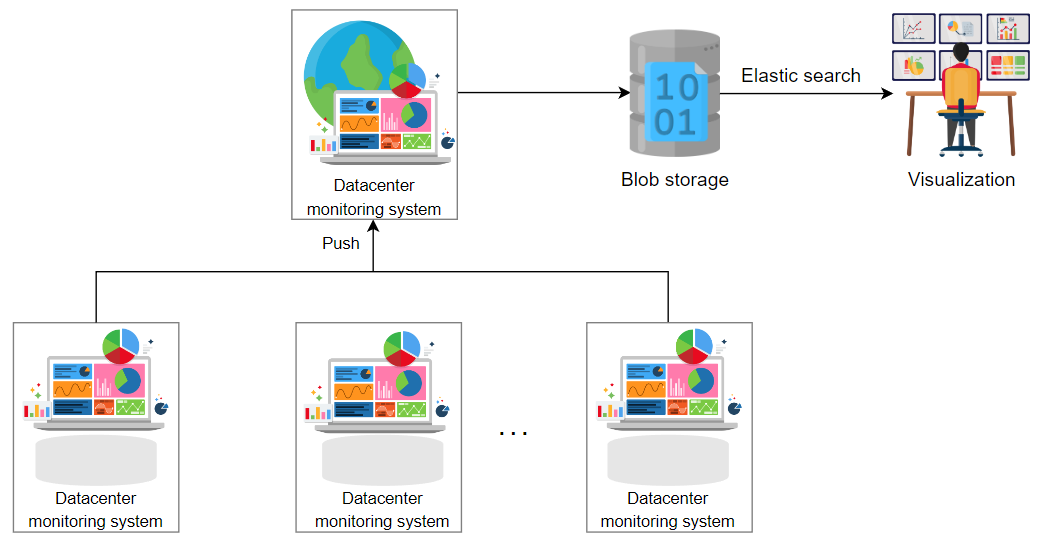
现在,我们将应用推送式策略。次要监控系统将把它们的数据推送到一个主数据中心服务器。主数据中心服务器将把其数据推送到负责检查全球分布的所有数据中心的全球监控服务。
我们将使用 blob 存储来存储我们过多的数据,应用弹性搜索,并使用可视化器查看相关统计数据。随着我们的服务器或数据中心的增加,我们将添加更多的监控系统。此设计如下所示。
相关信息
在系统设计中,使用系统层次结构进行扩展的模式是一种常见的设计模式。通过在层次结构中增加节点或引入其他层次,我们可以根据当前需求扩展。
警告
问题
如果本地或全局监控系统出现故障会发生什么?
答案
我们可以将数据存储在本地并等待系统重新运行。但本地数据存储是有限的。因此,我们要么删除先前的数据,要么不存储新数据。为做出决策,需要创建相关的策略。
问题
如果一个监控系统使用其所监控的数据中心中的相同基础架构,它如何可靠地工作?考虑到数据中心的网络故障可能会使监控组件失效。
答案
实际部署监控系统需要特别注意。我们可能会有一个专门用于监控的内部网络,以将其与普通网络隔离。
我们应该使用独立的 blob 存储实例和其他服务。同时,可以将监控的外部组件放在独立的服务提供商基础架构上。然而,设计这样的系统是复杂的,而且成本更高。
人类需要消耗大量的数据,即使进行了不同类型的数据汇总,数据仍然可能非常庞大。接下来,我们将解决如何将大量的数据呈现给人类管理员的问题。