监控系统的设计
学习通用监控系统的初始设计。
需求
让我们总结一下我们希望监控系统为我们完成的任务:
- 监视服务器上关键本地进程的崩溃情况。
- 监视服务器上进程使用 CPU/内存/磁盘/网络带宽的任何异常情况。
- 监视服务器的整体健康状况,例如 CPU、内存、磁盘、网络带宽、平均负载等等。
- 监视服务器硬件组件故障,例如内存故障、失败或减慢的磁盘等等。
- 监视服务器能否到达关键的服务——例如网络文件系统等等。
- 监视数据中心内部所有网络交换机、负载均衡器和任何其他专用硬件。
- 监视服务器、机架和数据中心水平的功耗。
- 监视服务器、机架和数据中心上的任何电源事件。
- 监视外部客户端的路由信息和 DNS。
- 监视数据中心内部和跨数据中心的网络链接和路径延迟。
- 监视互联网互连点的网络状态。
- 监视可能跨多个数据中心的整体服务健康状况——例如 CDN 和其性能。
我们希望通过自动化监控来识别系统中的异常情况并通知警报管理器或在仪表盘上显示进度。云服务提供商提供其服务的健康状况:
- AWS: https://health.aws.amazon.com/health/status
- Azure: https://status.azure.com/en-us/status
- Google: https://status.cloud.google.com/
我们将使用的构建块
分布式监控的设计将包含以下构建块:
Blob 存储:我们将使用 Blob 存储来存储有关指标的信息。
高级设计
我们监控服务的高级组件如下:
- 存储:时序数据库存储指标数据,例如当前 CPU 使用情况或应用程序中异常的数量。
- 数据收集器服务:此服务从每个服务中获取相关数据并将其保存在存储中。
- 查询服务:这是一个 API,可以查询时间序列数据库并返回相关信息。
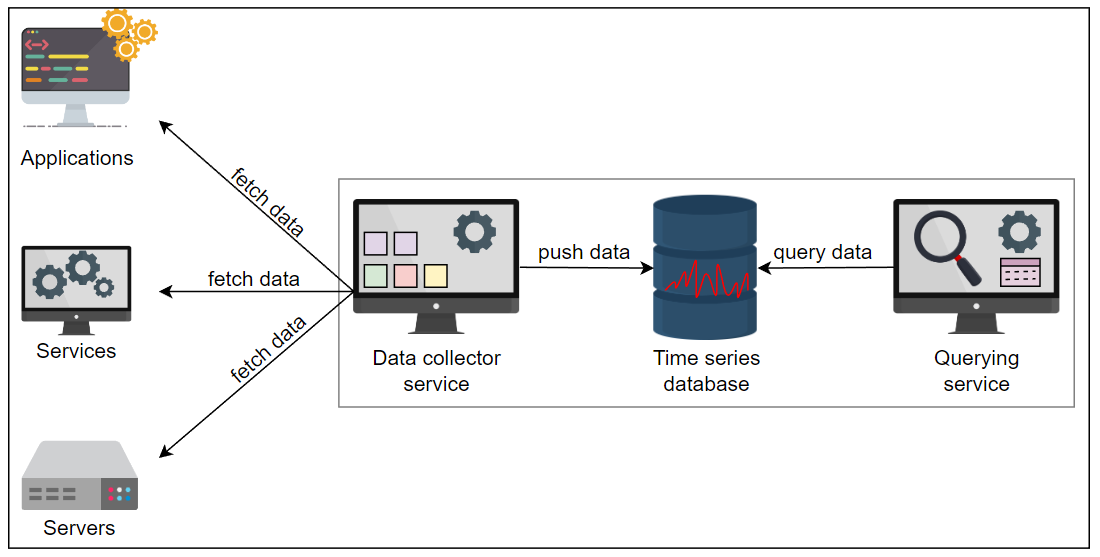
让我们在下一课程中深入探讨上述组件。