版本控制数据和实现可配置性
学习如何通过版本控制解决冲突,以及如何将键值存储转换成可配置的服务。
数据版本控制
当更新过程中发生网络分区和节点故障时,对象的版本历史可能会变得不连续。
因此,需要对系统进行调和。必须建立一种明确接受同一数据的多个副本的方法,以避免任何更新的丢失。
重要的是要意识到,某些故障情况可能导致系统中存在多个相同的数据副本。这些副本可能相同也可能不同。
解决这些不同历史之间的冲突对于保持一致性至关重要和关键。
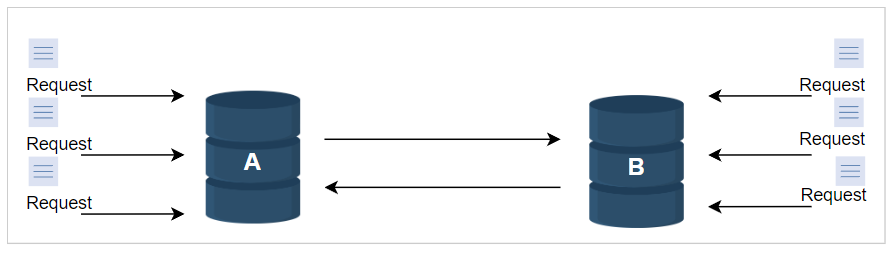
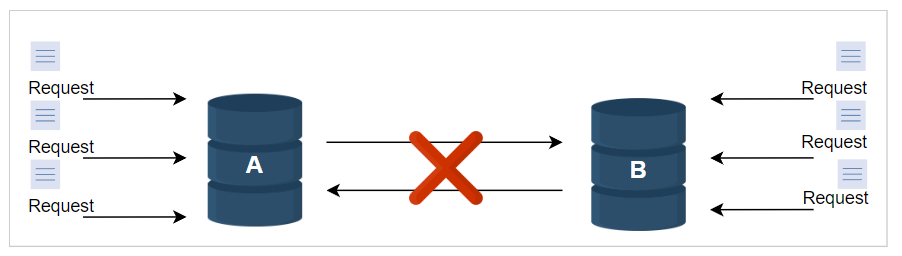


为了处理不一致性,需要保持事件之间的因果关系。可以使用时间戳来实现这一点,并使用最新请求的值更新所有冲突的值。
但在分布式系统中,时间并不可靠,因此不能将其作为决定因素。
另一种有效地保持因果关系的方法是使用向量时钟。
向量时钟是(节点,计数器)对的列表。
每个对象的每个版本都有一个单独的向量时钟。
如果两个对象具有不同的向量时钟,我们可以判断它们是否因果相关(稍后会详细介绍)。
除非其中一个变更被调和,否则这两个对象将被视为不一致。
修改API设计
我们已经讨论过如何使用向量时钟值来确定两个事件是否因果相关。
为此,我们需要关于哪个节点执行了操作以及它的向量时钟值的信息。
这是一个操作的上下文。因此,我们将修改API设计如下。
获取值的API调用应该像这样:
get(key)
| 参数 | 描述 |
|---|---|
key | 这是我们想要获取value的key。 |
我们返回一个对象或一组冲突对象,以及一个context。context包含有关对象的编码元数据,包括对象的版本等详细信息。
将值放入系统的API调用应该像这样:
put(key, context, value)
| 参数 | 描述 |
|---|---|
key | 这是我们必须在其中存储value的key。 |
context | 这包含每个对象的元数据。 |
value | 这是需要存储在key下的对象。 |
该函数根据key查找节点并将与之关联的值存储在其中。
context在get操作之后由系统返回。
如果我们在context中有一个冲突的对象列表,我们将要求客户端解决它。
要更新键值存储中的对象,客户端必须提供context。
我们使用向量时钟来确定版本信息,通过提供先前读取操作的context。
如果键值存储有多个分支,它在处理读取请求时会提供所有叶节点的对象以及它们各自在上下文中的版本信息。
将不同版本调和并合并成一个新版本被认为是一个更新操作。
提示
注意: 解决冲突的这个过程类似于在Git中执行的过程。如果Git能够将多个版本合并为一个版本,那么自动合并将自动执行。
如果自动冲突解决不可能,则由客户端(开发人员)手动解决冲突。
同样,我们的系统可以尝试自动解决冲突,如果不可能,则要求应用程序提供最终的解决方案。
向量时钟使用示例
让我们考虑一个例子。假设我们有一个写操作请求。
节点A处理写请求的第一个版本E1,其中E表示事件。
相应的向量时钟具有节点信息和其计数器,即[A,1]。
节点A在同一对象上执行了另一个写操作,即E2,因此,对于E2,我们有[A,2]。
E1不再需要,因为E2在同一节点上被更新了。
E2读取了由E1所做的更改,然后进行了新的更改。
假设发生了网络分区。现在,请求由两个不同的节点B和C处理。
现在,具有更新版本(即E3,E4)及其相关时钟(即([A,2],[B,1])和([A,2],[C,1]))的上下文已在系统中。
假设网络分区现在已被修复,并且客户端再次请求写入,但现在我们有冲突。
将返回冲突的上下文([A,3],[B,1],[C,1])给客户端。
客户端进行调和并由节点A协调写操作后,我们将E5与时钟([A,4])绑定。
假设我们有三个节点。向量时钟计数器对于所有节点都设置为1

节点A处理写请求的第一个版本E1,向量时钟计数器增加了1
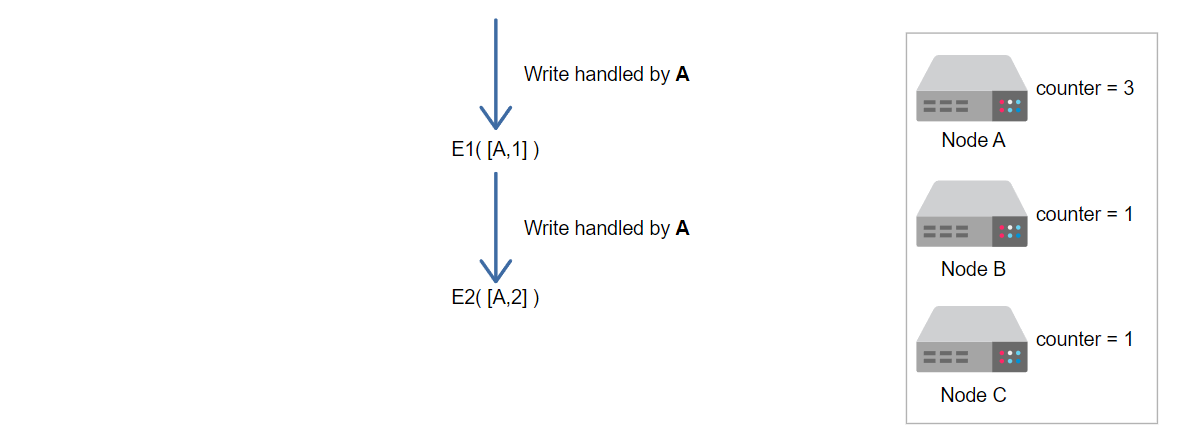
节点A处理写请求的第二个版本E2,向量时钟计数器增加了2
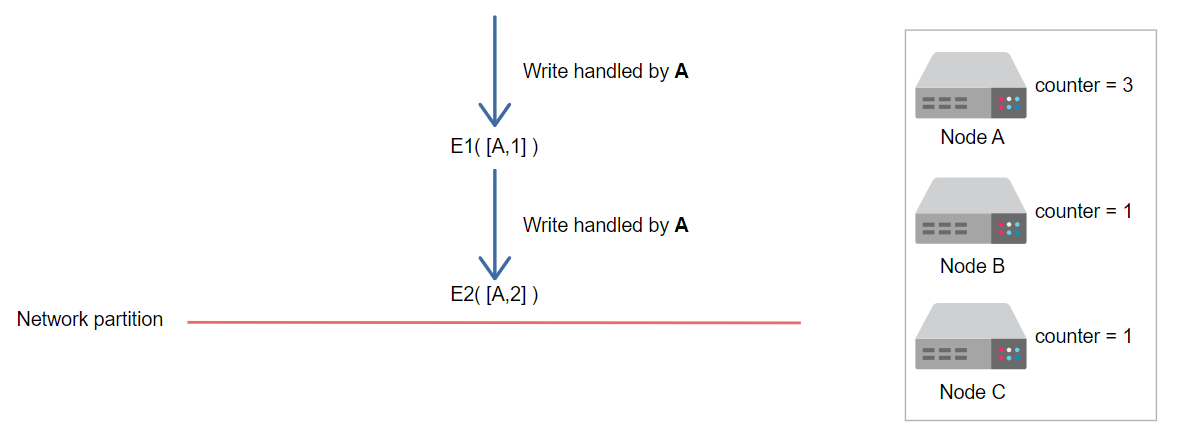
假设发生了网络分区
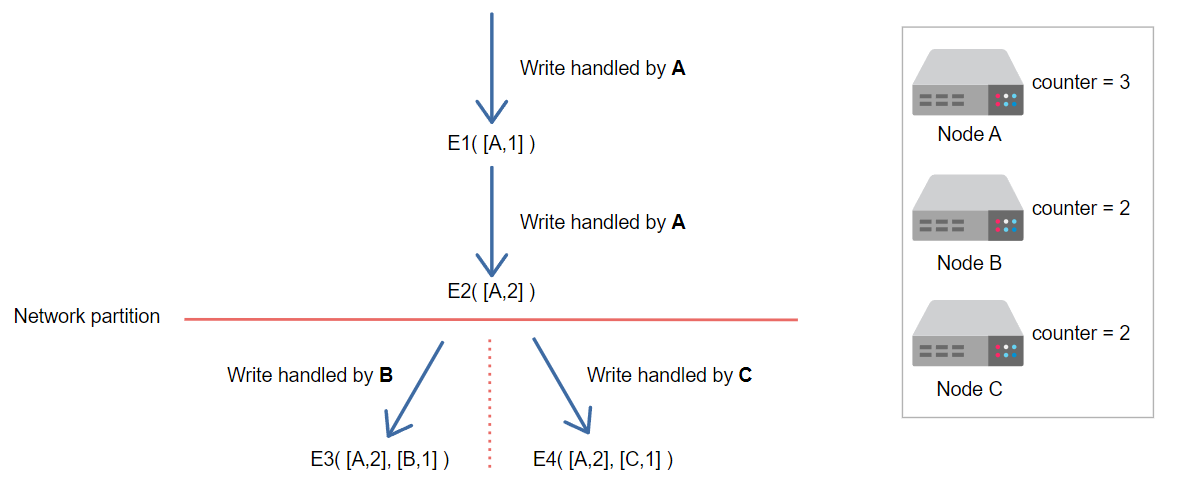
现在,请求由节点B和节点C处理,它们各自的向量时钟计数器都增加了
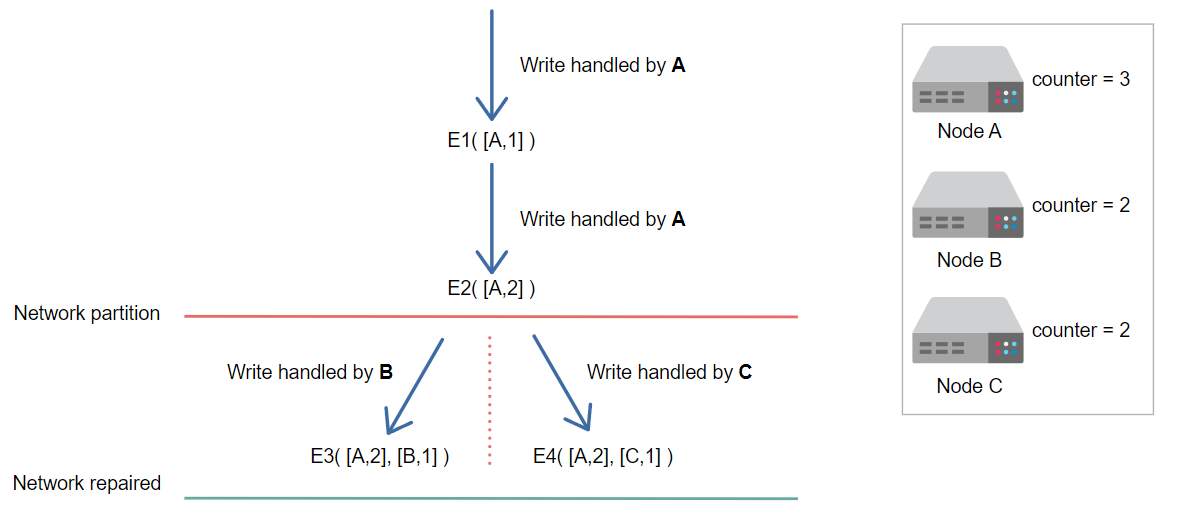
假设网络现在已修复
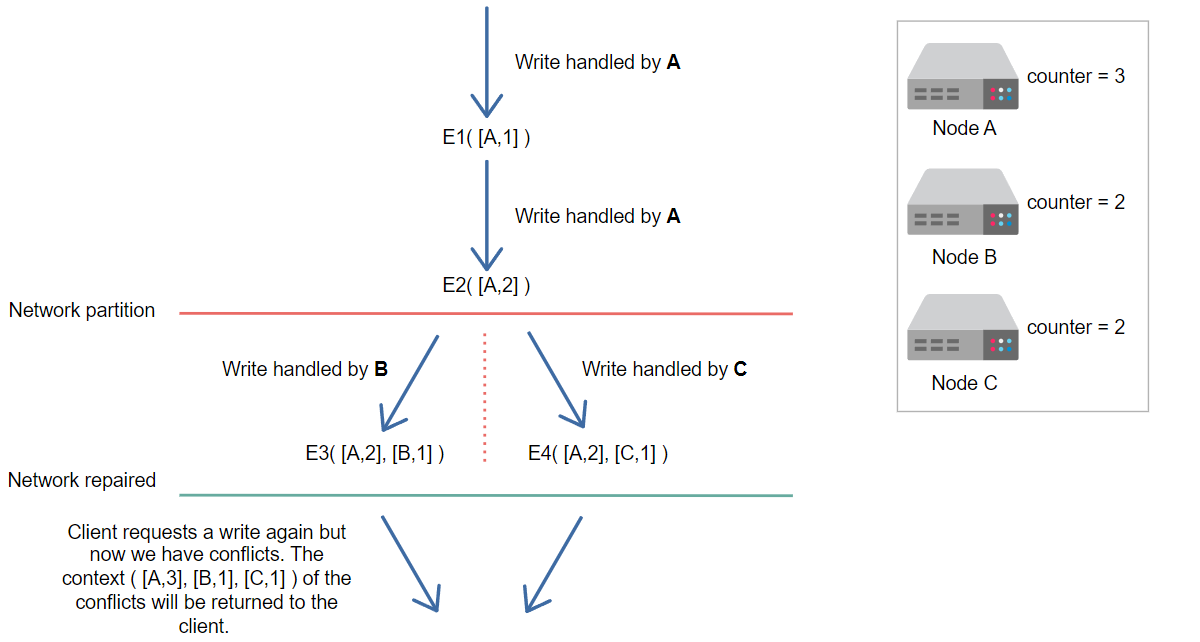
请求发送给节点A进行处理,但现在有冲突。我们要求客户端解决它
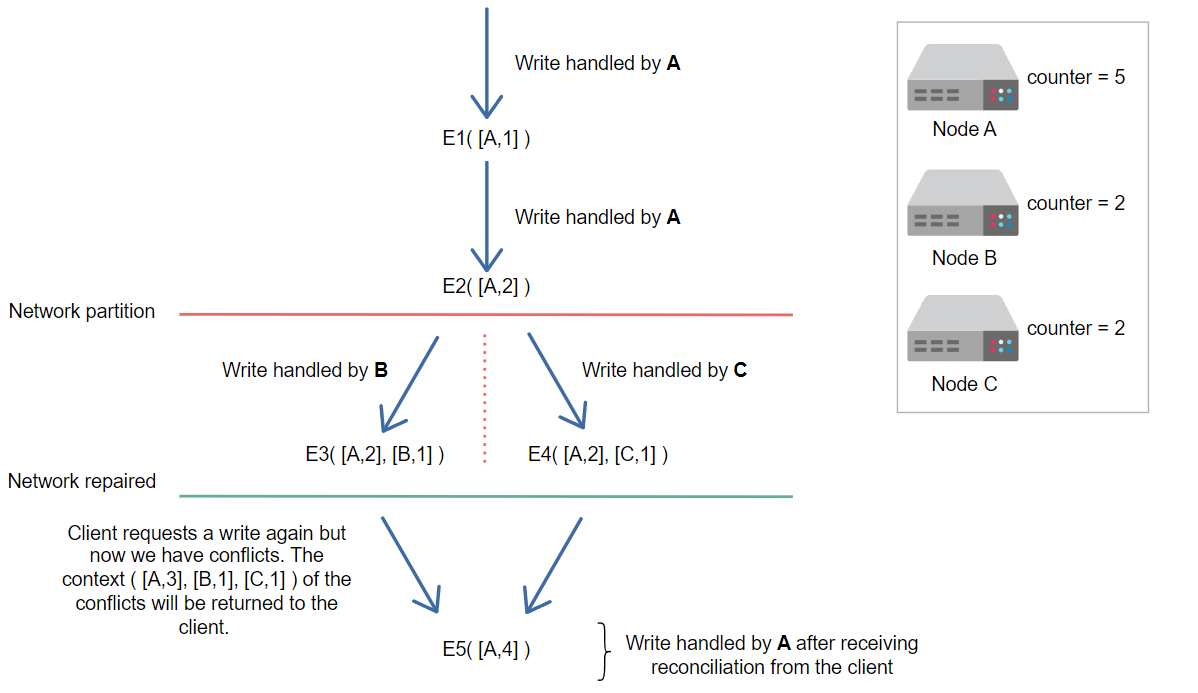
经过调和后,请求被更新
向量时钟限制的妥协
如果多个服务器同时写入同一对象,则向量时钟的大小可能会增加。
在实践中很少发生,因为写入通常由偏好列表中的前n个节点之一处理。
例如,如果存在网络分区或多个服务器故障,则写请求可能由偏好列表中未在前n个节点中的节点处理。
因此,我们可以得到这样一个长版本:([A,10],[B,4],[C,1],[D,2],[E,1],[F,3],[G,5],[H,7],[I,2],[J,2],[K,1],[L,1])。
存储和维护这样长的版本历史记录非常麻烦。
在这些情况下,我们可以限制向量时钟的大小。
我们采用时钟截断策略,为每个(节点, 计数器)对存储一个时间戳,以显示最后一次由节点更新数据项的时间。
当 (节点, 计数器) 对的数量超过预定阈值 (比如10) 时,向量时钟对将被清除。由于无法精确计算后代链接,这种截断方法可能会导致调和缺乏效率。
get 和 put 操作
我们的一个功能要求是系统应该是可配置的。
我们希望控制可用性、一致性、成本效益和性能之间的权衡。
因此,让我们通过实现键值存储的基本 get 和 put 函数来实现可配置性。
在我们的系统中,每个节点都可以处理 get(读取)和 put(写入)操作。
处理读取或写入操作的节点称为 协调者。
在偏好列表中,协调者是前 n 个节点中的第一个节点。
客户端可以选择两种方法之一:
- 将请求路由到通用负载均衡器。
- 使用分区感知的客户端库,直接将请求路由到相应的协调节点。
这两种方法都有其优点。
在第一种方法中,客户端不与代码关联,而在第二种方法中,由于客户端可以直接进入特定服务器,因此可以实现更低的延迟。
让我们通过使用类似于分区系统中使用的一致性协议来使我们的服务可配置。
假设在偏好列表的前 n 个节点中,n=33。
这意味着需要维护三个数据副本。我们假设节点位于一个环上。
假设 A、B、C、D 和 E 是该环中节点的顺时针顺序。
如果写操作在节点 A 上执行,则该数据的副本将放置在 B 和 C 上。
这是因为在环的顺时针方向移动时,B 和 C 是我们找到的下一个节点。
r 和 w 的使用
现在,考虑两个变量,r 和 w。r 表示在成功的读取操作中必须包含的最小节点数,而 w 是在成功的写入操作中涉及的最小节点数。
因此,如果 r=2,则表示当我们有存储在三个节点中的数据时,我们的系统将从两个节点读取。
我们需要选择 r 和 w 的值,使它们之间至少有一个节点是公共的。这可以确保读者可以获取最新的写入值。
为此,我们将使用类似于分区的系统的一致性协议,设置 r+w> n。
下表概述了 n、r 和 w 的值如何影响读取和写入速度:
读写操作对值的影响
| n | r | w | 描述 |
|---|---|---|---|
| 3 | 2 | 1 | 不允许,因为违反了 r + w > n 的限制。 |
| 3 | 2 | 2 | 允许,因为满足了限制条件。 |
| 3 | 3 | 1 | 会提供快速的写操作但是较慢的读操作,因为读者需要访问所有 n 个副本来获取一个值。 |
| 3 | 1 | 3 | 会提供快速的读操作,但是写操作较慢,因为我们现在需要同步地向所有 n 个节点写入。 |
假设 n=3,这意味着数据复制到了三个节点。
现在,对于 w=2,操作会确保在两个节点上写入以使该请求成功。
对于第三个节点,数据将异步更新。
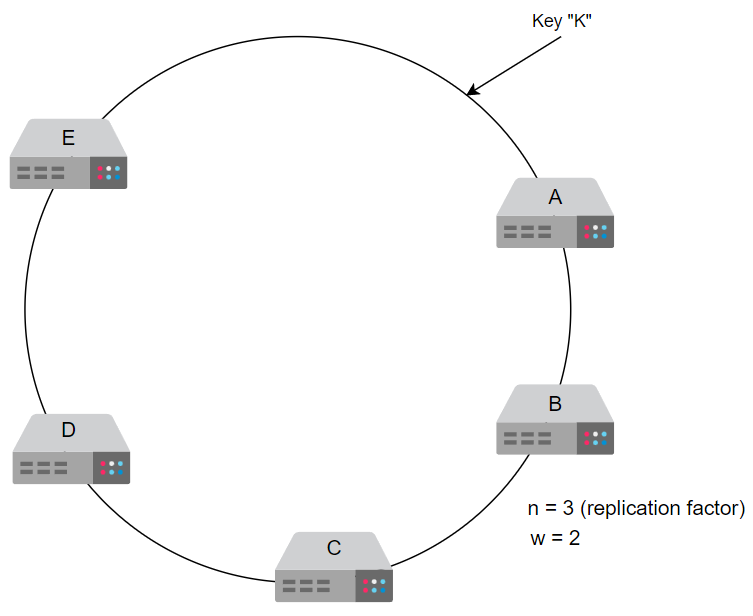
我们的复制因子为3,w为2。键 “K” 将被复制到A、B和C
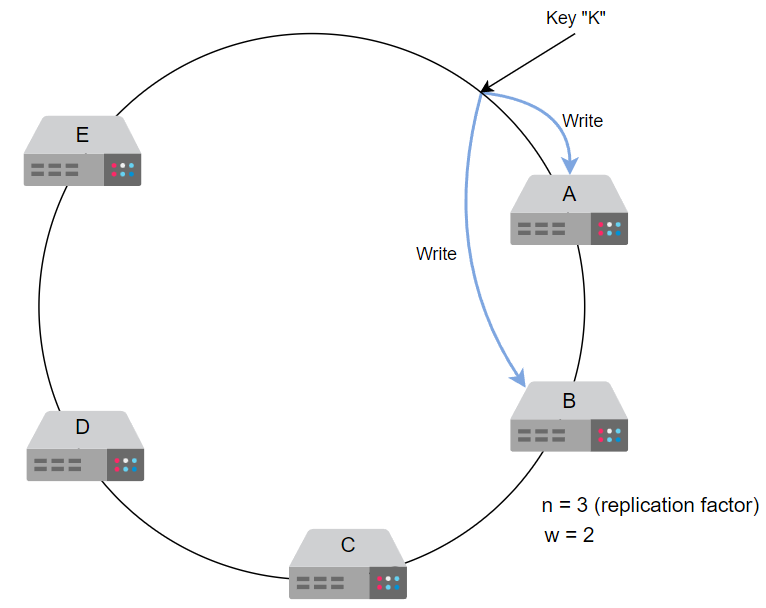
由于w=2,我们将在前两个节点上进行写入,然后向用户或客户端发送确认。
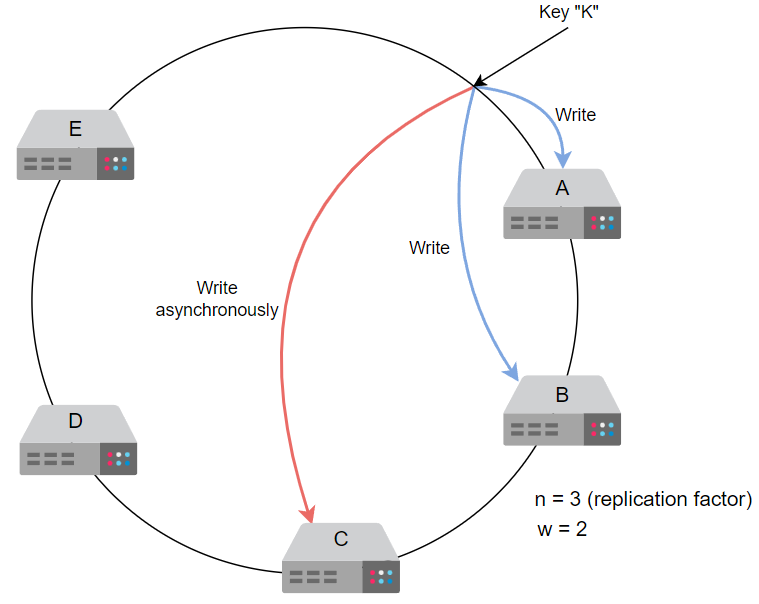
对于第三个节点,我们将异步地写入/复制数据。
在这个模型中,get操作的延迟由最慢的 r 个副本决定。
原因是对于更大的 r 值,我们更注重可用性,而不是一致性。
当接收到对键的 put() 请求时,协调者为新版本生成向量时钟并在本地写入新版本。
协调者向具有最高排名的 n 个节点发送更新的版本和新的向量时钟。
如果至少 w-1 个节点响应,则认为写入成功。
请记住,协调者首先在自己本地写入,所以我们总共得到 w 次写入。
对于 get() 操作的请求,将向一个键的首选列表中排名最高的 n 个可达节点发出。
他们等待 r 个答案才将结果返回给客户端。
如果他们从同一来源获得了多个数据集(需要协调的不同历史记录),则协调器将返回它们视为不相关的所有数据集版本。
然后将冲突版本合并,将结果键的值重写以覆盖之前的版本。
到目前为止,我们已经满足了可扩展性、可用性、冲突解决和可配置服务的要求。最后一个要求是拥有一个容错系统。下一课我们将讨论如何实现这一点。