确保可扩展性和复制
了解一致性哈希如何实现可扩展性以及如何复制分区数据。
增加可扩展性
让我们从其中一个核心设计要求开始:可扩展性。我们将键-值数据存储在存储节点中。随着需求的变化,我们可能需要添加或删除存储节点。这意味着我们需要将数据分区到系统中的节点上,以便将负载分布到所有节点上。
例如,假设我们有四个节点,我们希望将25%的请求发送到每个节点以平衡负载。传统的解决方法是使用取模运算符。当收到请求时,我们分配一个请求ID,计算其哈希值,并通过将其取模节点数得到余数。余数值就是节点编号,我们将请求发送到该节点以处理它。
以下幻灯片解释了这个过程:
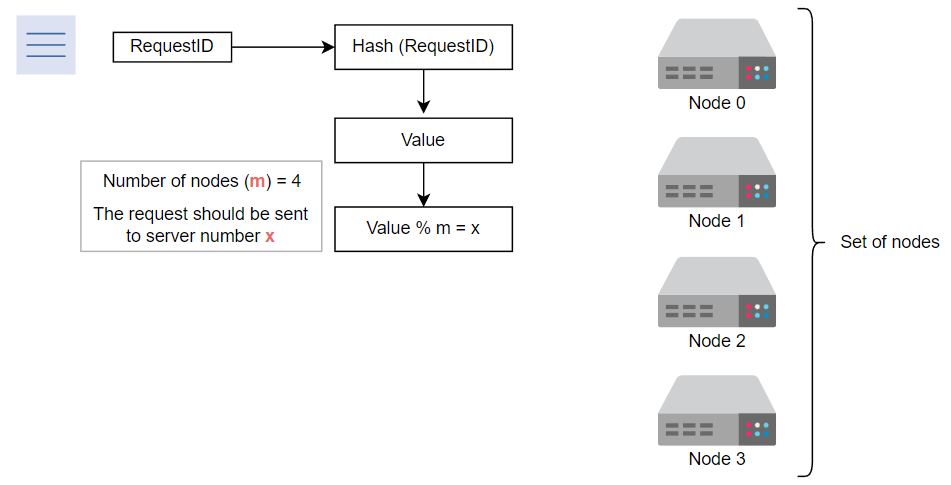
我们获取请求ID的哈希值,并取模以查找应处理请求的节点
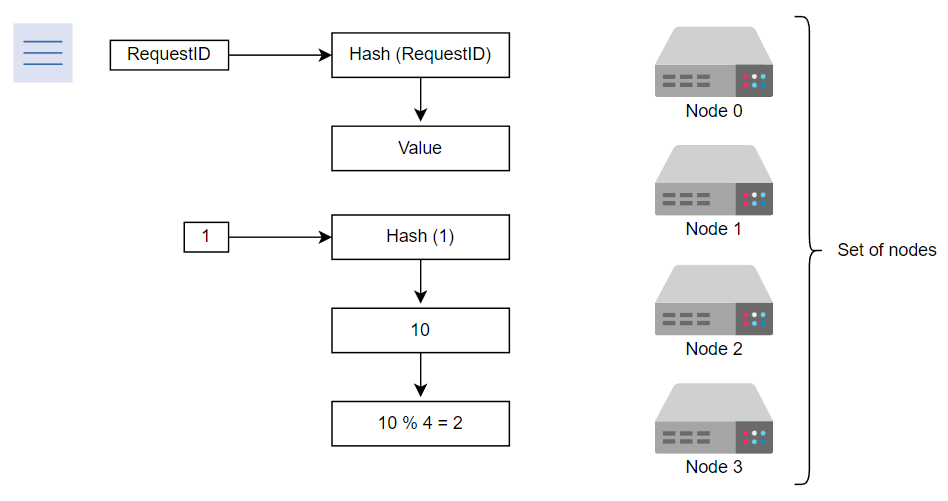
我们对请求ID执行所需的操作以获取节点
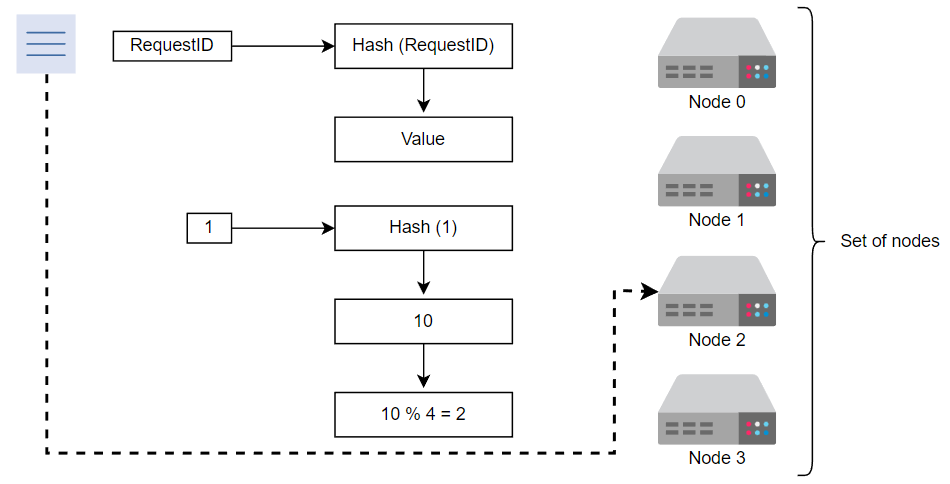
节点2将处理请求
我们希望在最小更改基础架构的情况下添加和删除节点。
但是在这种方法中,当我们添加或删除节点时,我们需要移动大量的键。
这是低效的。
例如,我们移除节点2,并假设对于相同的请求ID,新服务器要处理请求的节点将是节点1,因为10%3=110%3=1。
节点在它们的本地缓存中保存信息,如键和它们的值。
因此,我们需要将该请求的数据移动到下一个要处理请求的节点。
但是这种复制可能是昂贵的,并且可能导致高延迟。
接下来,我们将学习如何高效地复制数据。
相关信息
问题
为什么我们没有使用负载均衡器将请求分发到所有节点?
答案
负载均衡器根据算法分发客户端请求。
该算法可以像上面解释的那样简单,也可以是一些详细的算法,如下一节所述的详细描述。
我们将讨论的下一种方法可能是负载均衡器将请求平衡在节点之间的方法之一。
一致性哈希
一致性哈希是一种有效的管理节点集合负载的方式。
在一致性哈希中,我们考虑一个哈希环,从0到n−1都是哈希值,其中n是可用的哈希值数量。
我们使用每个节点的ID,计算其哈希值,并将其映射到环上。我们对请求应用相同的过程。
每个请求按顺时针方向在环上移动,由它找到的下一个节点完成。
每当向环添加新节点时,立即下一个节点就会受到影响。
它必须与新添加的节点共享其数据,而其他节点则不受影响。它很容易扩展,因为我们能够使节点更改最小化。
这是因为只有少量的关键字需要移动。
哈希是随机分布的,因此我们期望请求负载在平均情况下随机分布并平均分布在环上。
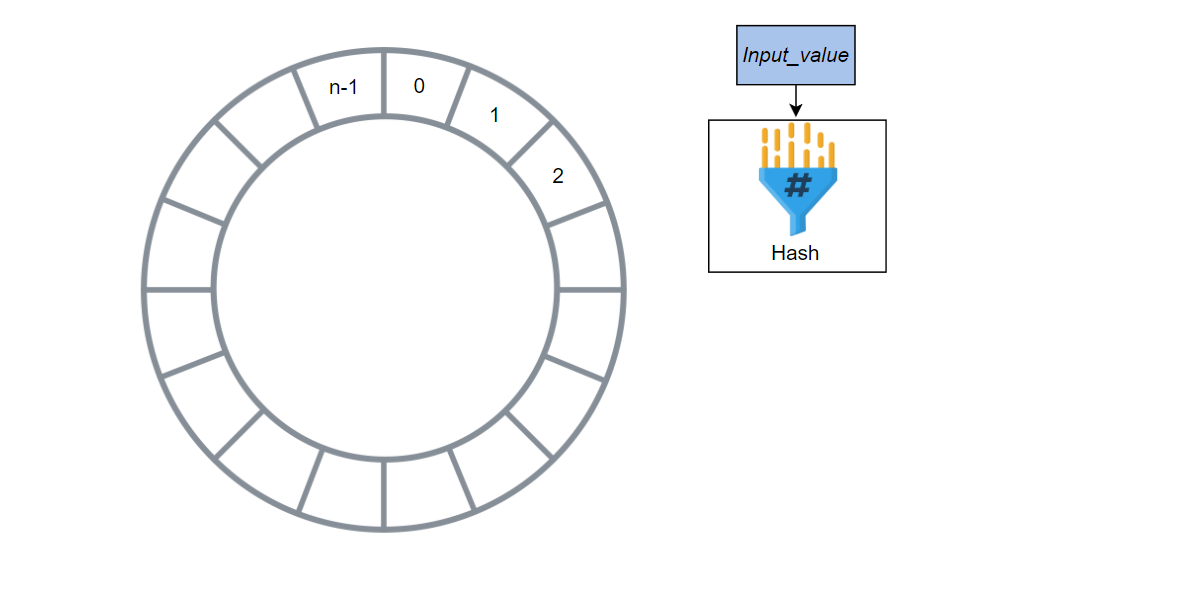
考虑我们有一个哈希环,从0到n-1都是哈希值,其中n是环中可用的哈希值总数。
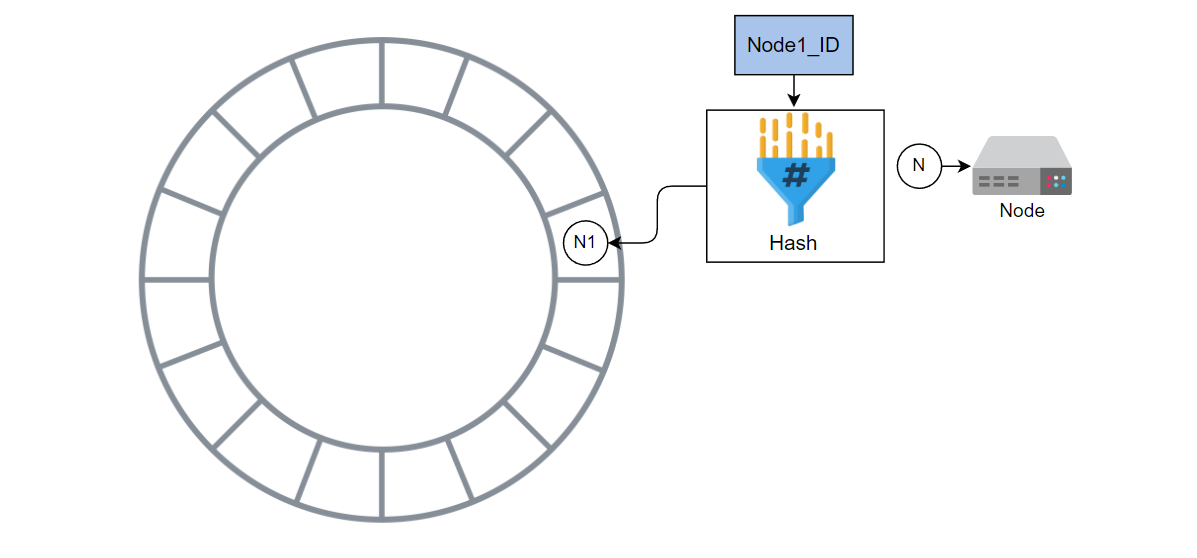
计算 Node1 的哈希值并将 Node1 添加到环中。
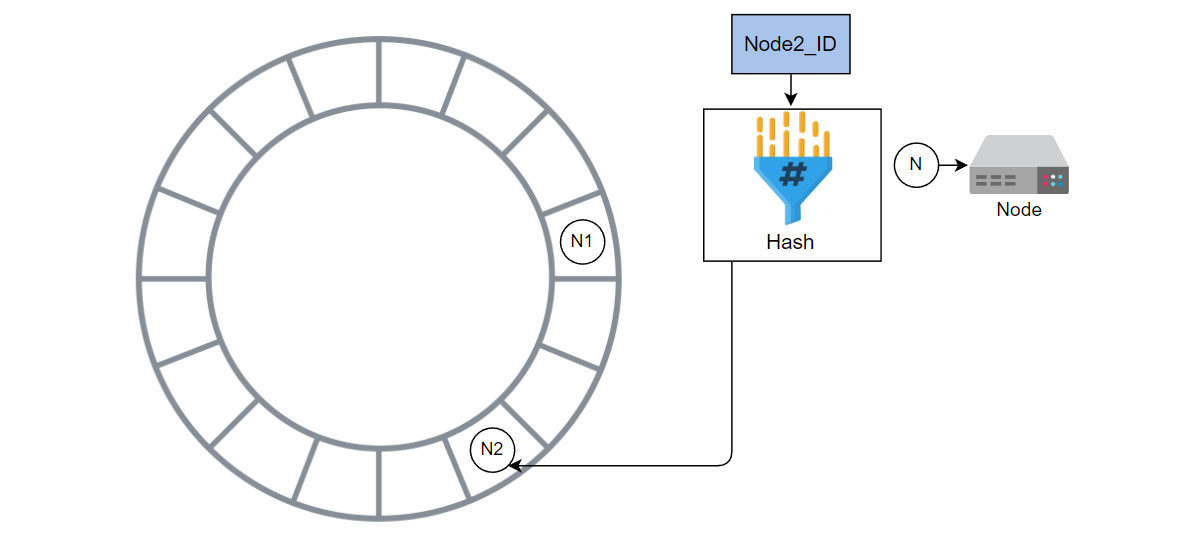
计算Node2的哈希值并将Node2添加到环中。
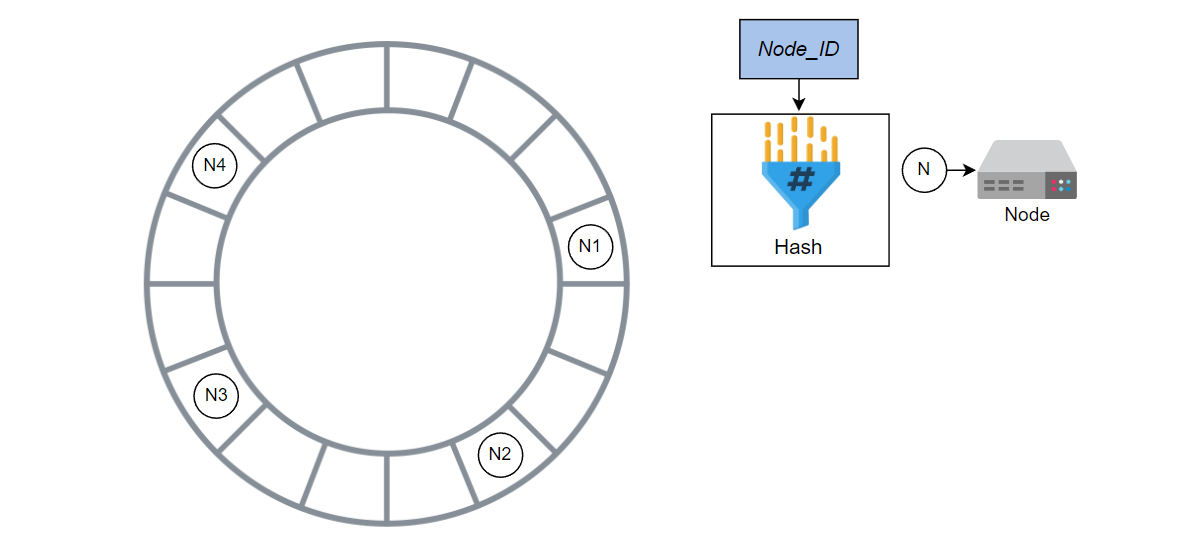
计算其他节点的哈希值并将其添加到环中。
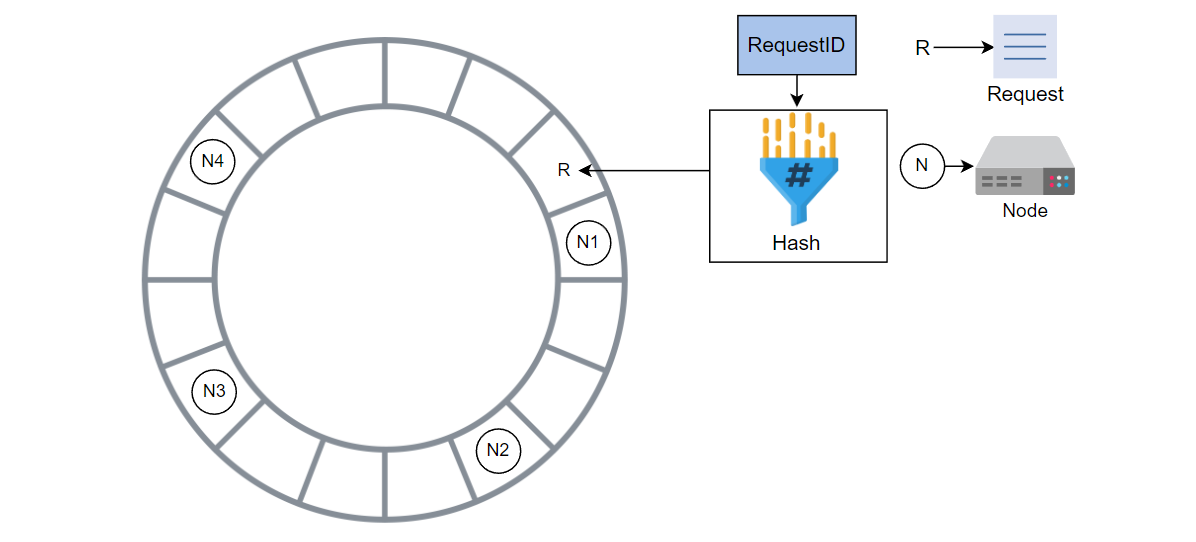
同样,计算请求的哈希值并将请求添加到环中。
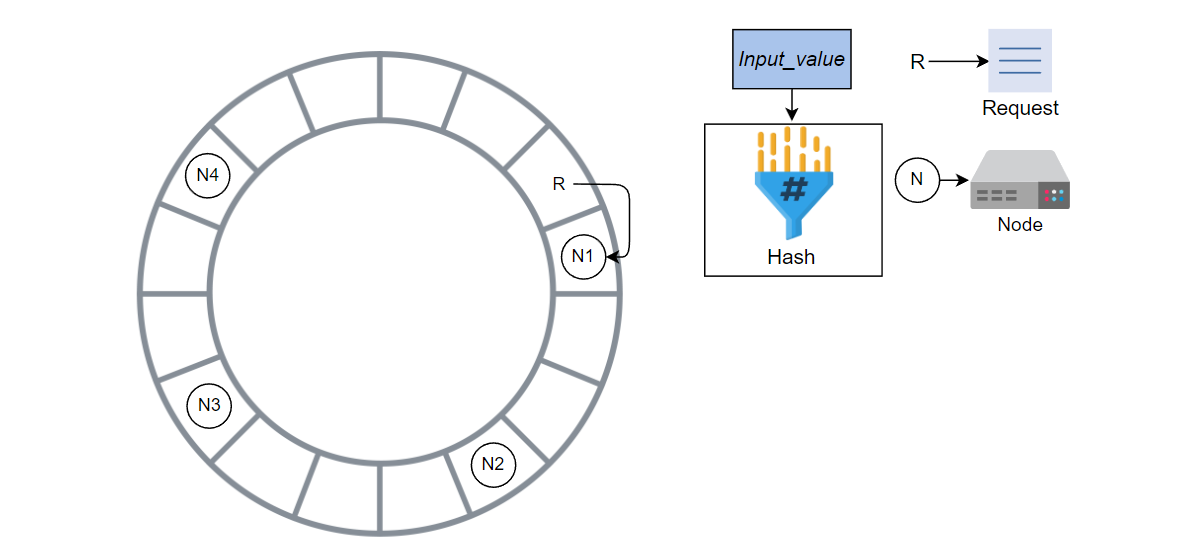
请求按顺时针方向移动到找到的下一个节点处完成。
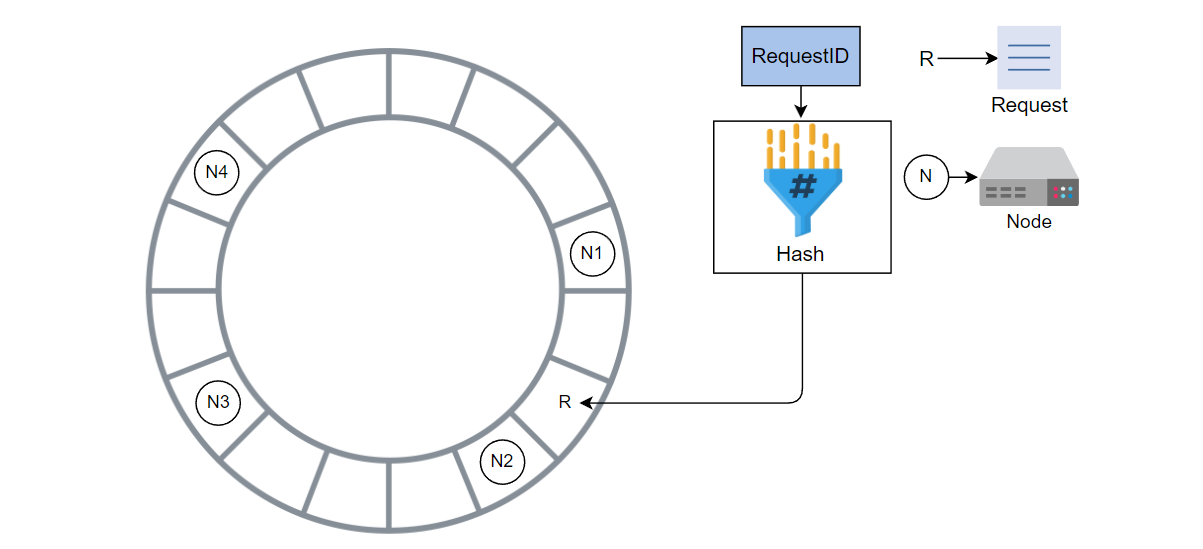
计算下一个请求的哈希值并将请求添加到环中。
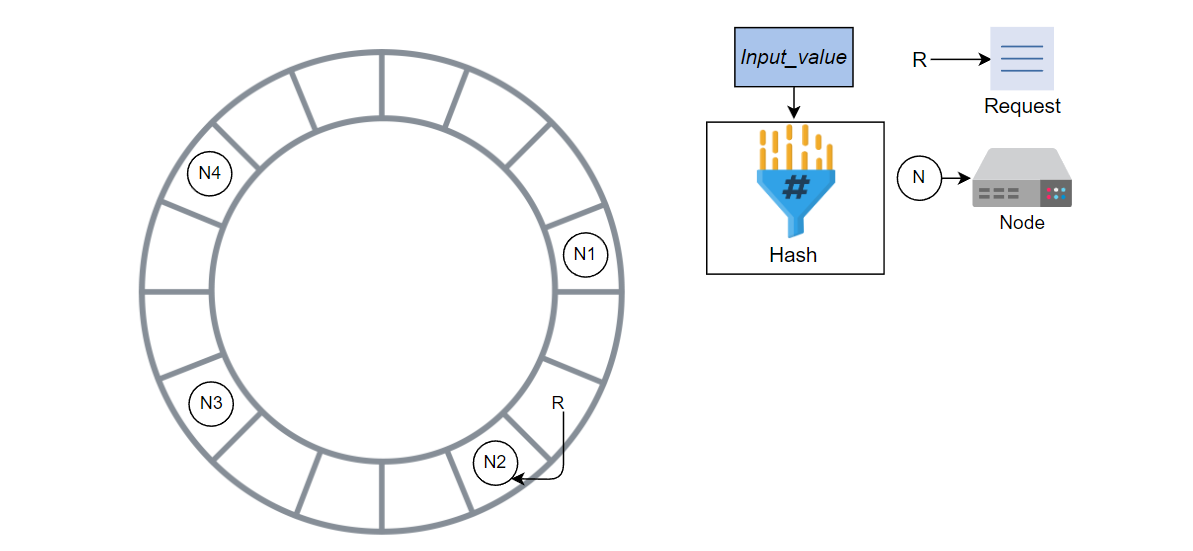
请求由N2完成,因为它是顺时针方向的下一个节点。
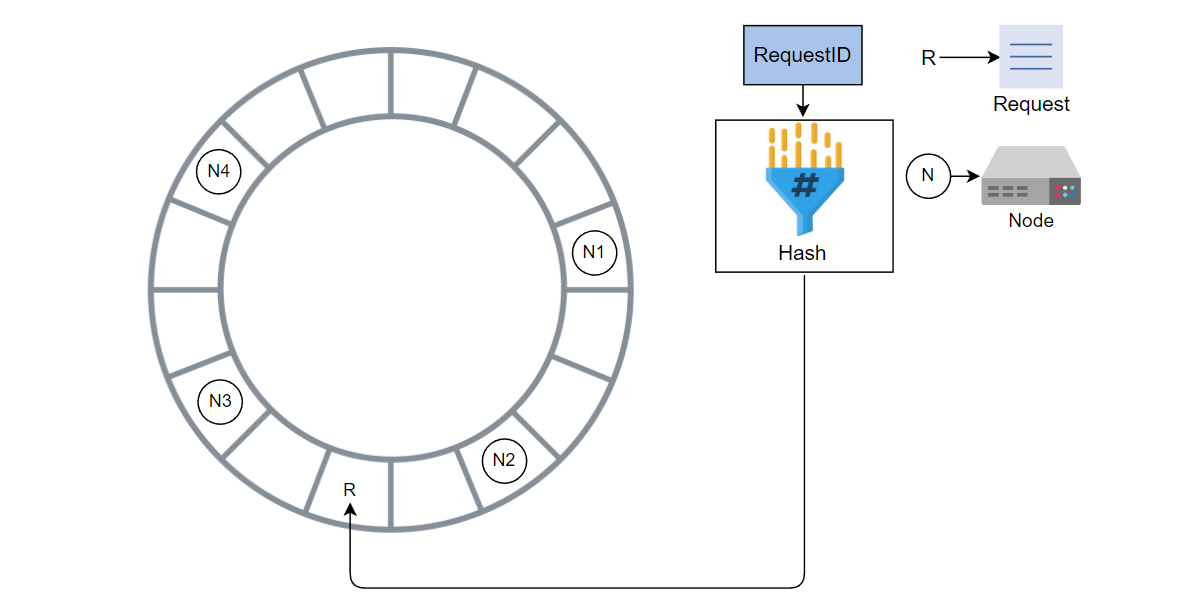
计算请求的哈希值并将请求添加到环中。
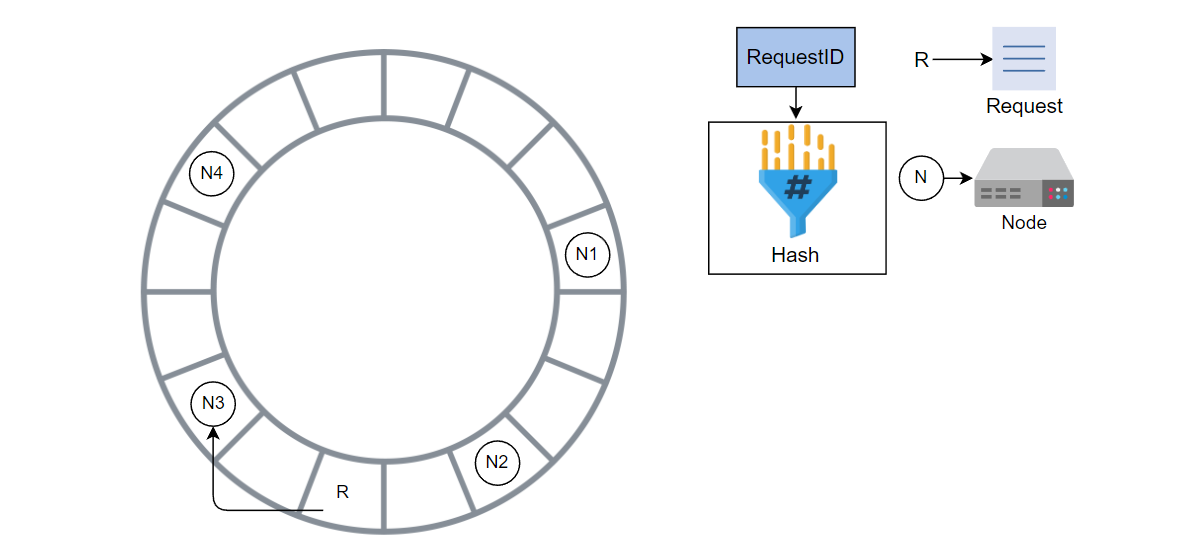
请求被 N3 处理,因为它是顺时针方向上的下一个节点。
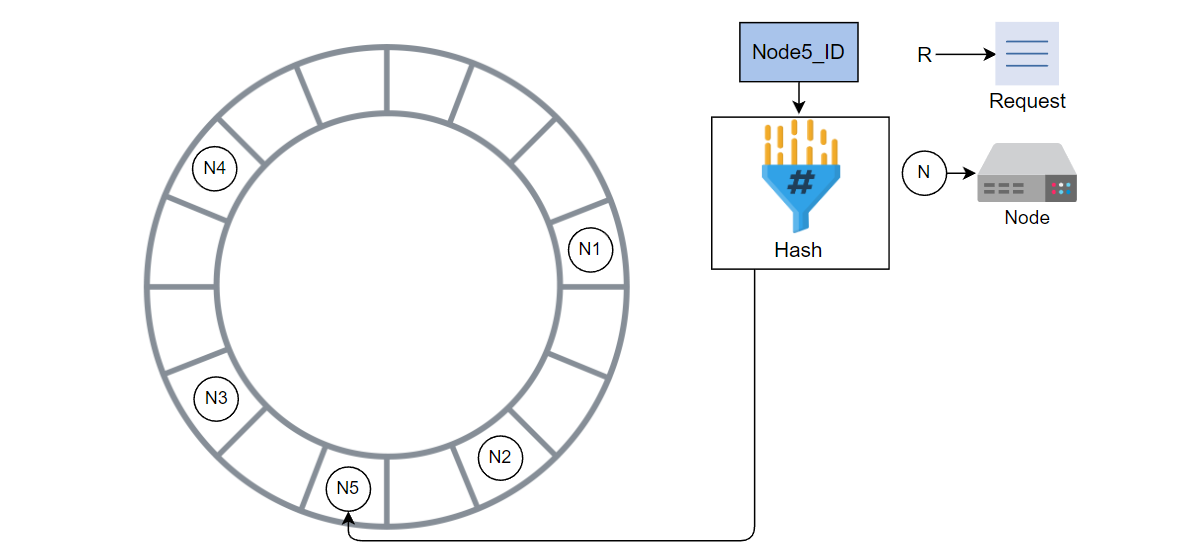
对于新节点 Node5,计算哈希值后将其添加到环中。
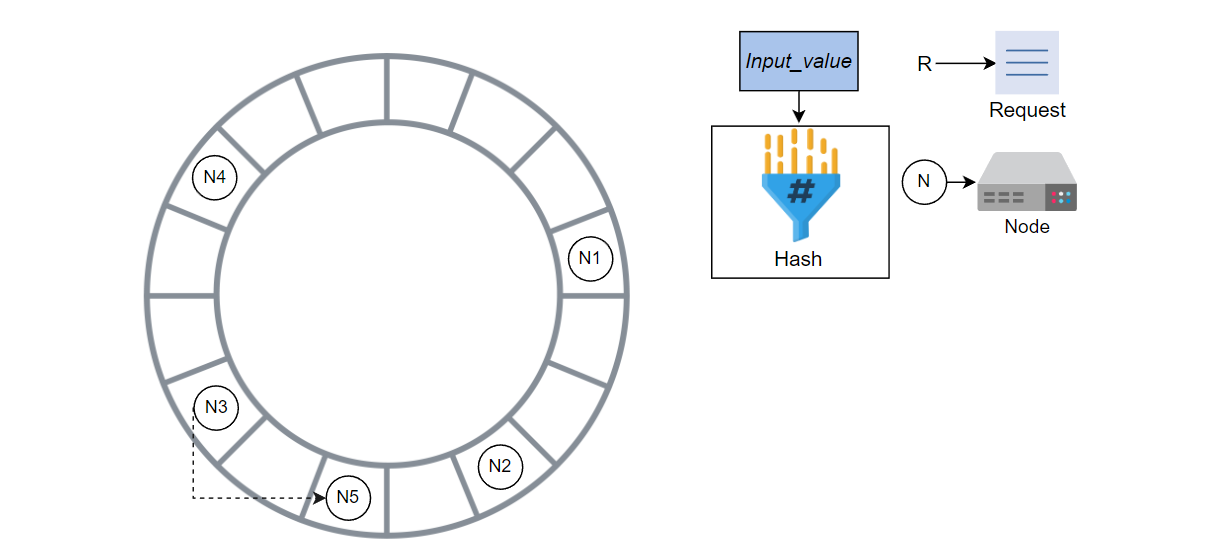
N3 将从 N2 到 N5 的键与 N5 共享。
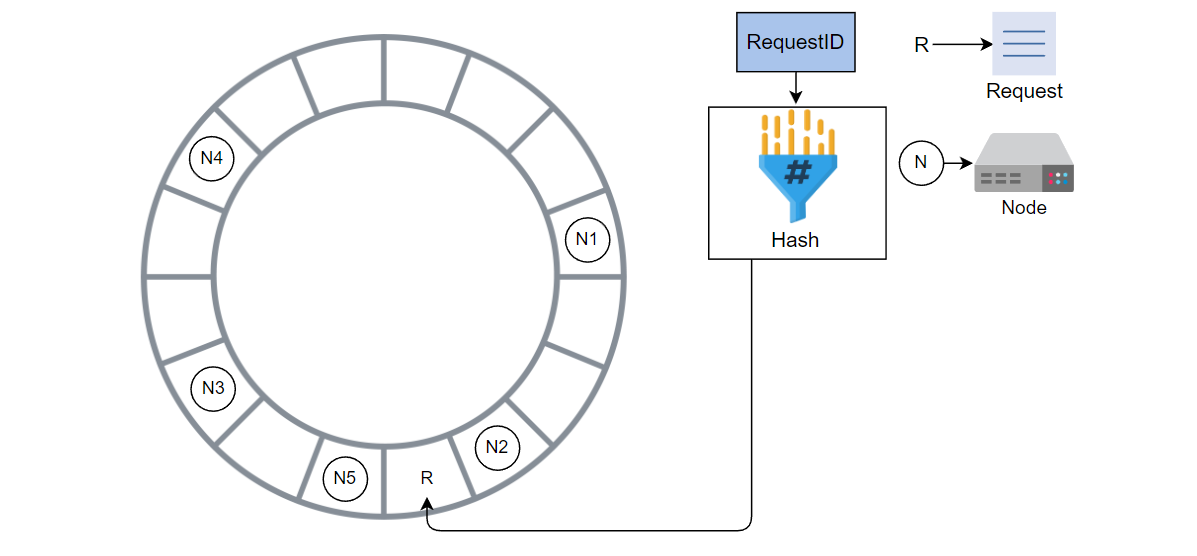
计算新请求的哈希值并将其添加到环中。
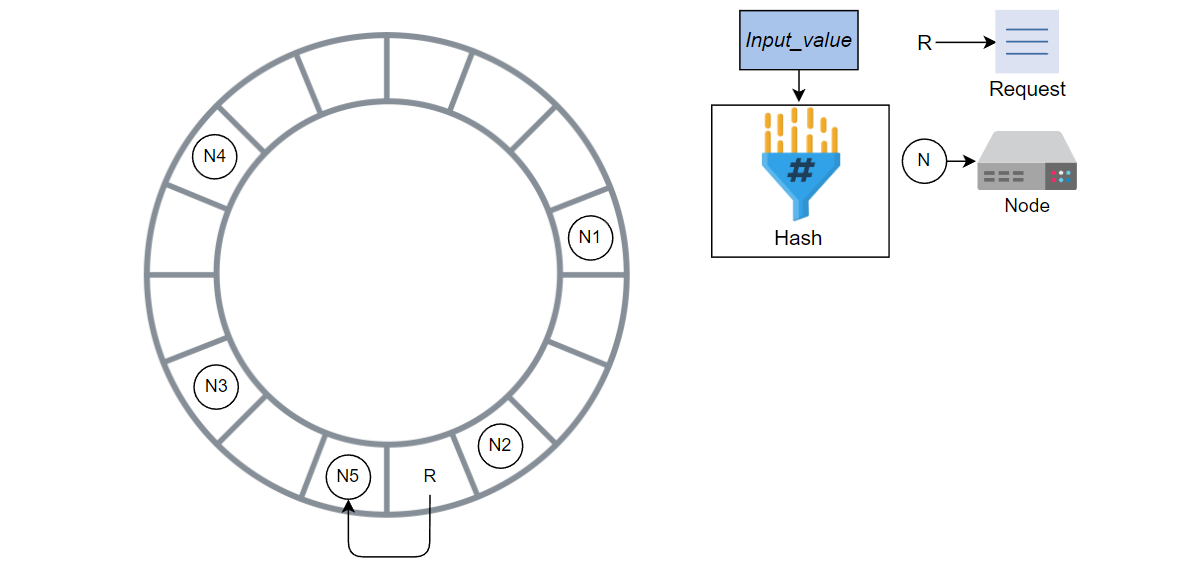
请求被 N5 处理,而不是 N3,因为 N5 是顺时针方向上的下一个节点。
一致性哈希的主要优点是,随着节点加入或离开,它确保最少数量的键需要移动。
然而,在实践中,请求负载并不均衡。任何处理大量数据的服务器都可能成为分布式系统中的瓶颈。
该节点将接收到不成比例的大量数据存储和检索请求,降低整个系统的性能。因此,这些节点被称为热点。
如下图所示,大多数请求在 N4 和 N1 之间。
现在,与其他节点相比,N1 必须处理大部分请求,它已成为一个热点。
这意味着非均匀的负载分布增加了单个服务器的负载。
警告
注意: 在继续阅读之前,思考一下非均匀负载分布的可能解决方案是一种很好的练习。
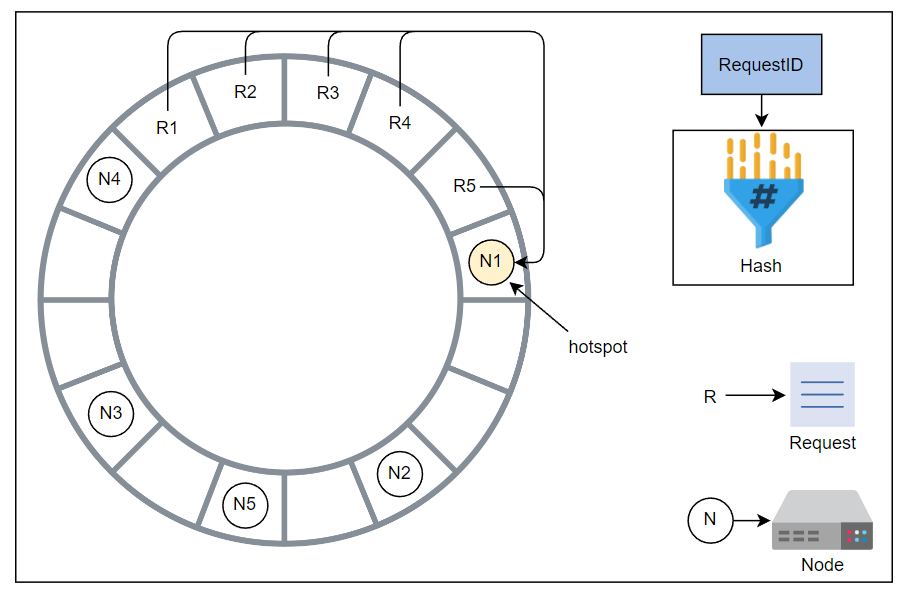
环中的非均匀请求分布
使用虚拟节点
我们将使用虚拟节点来确保负载在节点之间更均匀地分布。不再仅仅应用一个哈希函数,而是将多个哈希函数应用于同一个键。
让我们来举个例子。假设我们有三个哈希函数。
对于每个节点,我们计算三个哈希值并将它们放入环中。
对于请求,我们只使用一个哈希函数。
不管请求落在环的哪个位置,它都将被顺时针方向上的下一个节点处理。
每个服务器都有三个位置,因此请求的负载更加均匀。
此外,如果一个节点比其他节点有更多的硬件容量,我们可以通过使用更多的哈希函数添加更多的虚拟节点。
这样,它在环中会有更多的位置,并为更多的请求提供服务。
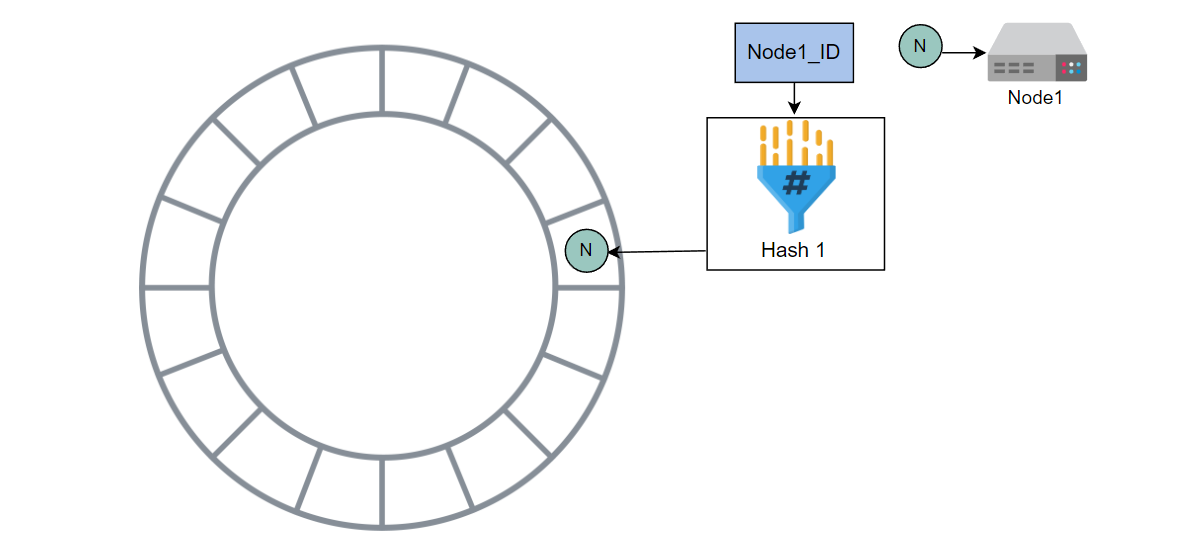
使用哈希 1 计算 Node1 的哈希值,并将其放入环中
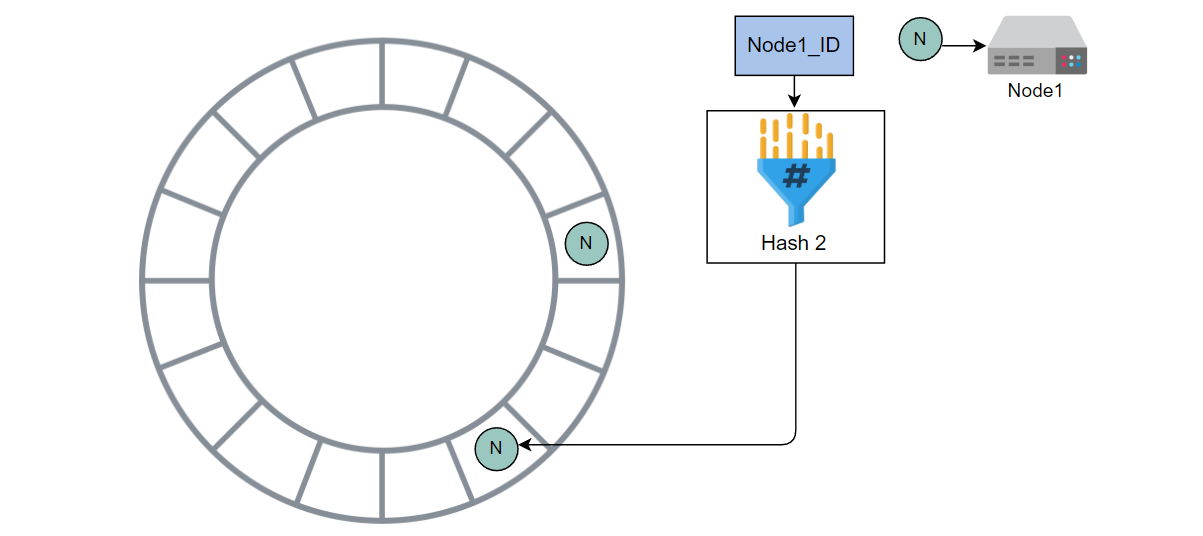
使用哈希 2 计算 Node1 的哈希值,并将其放入环中
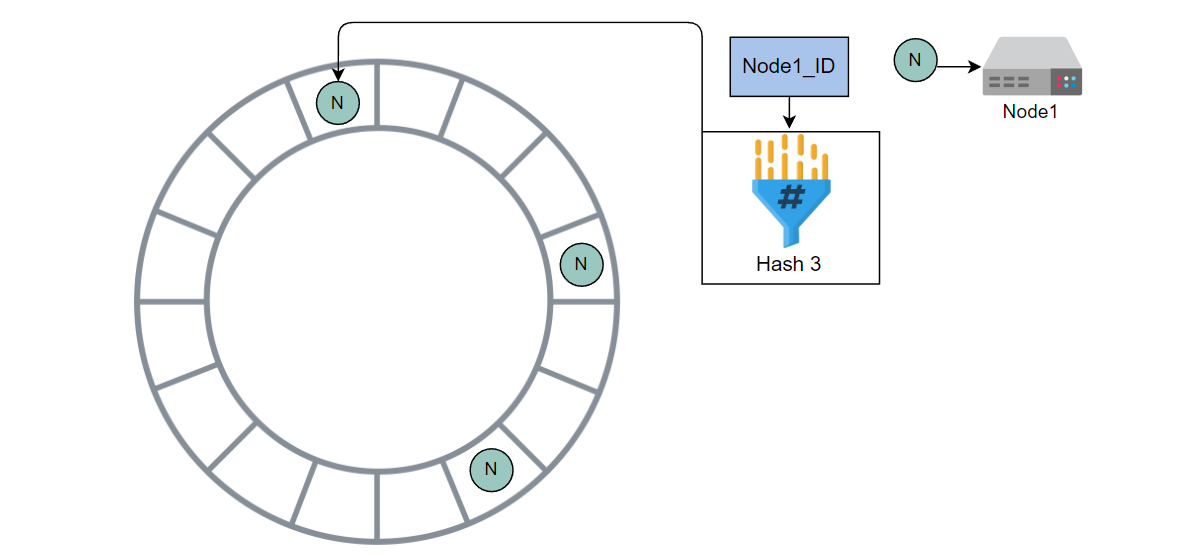
使用哈希 3 计算 Node1 的哈希值,并将其放入环中
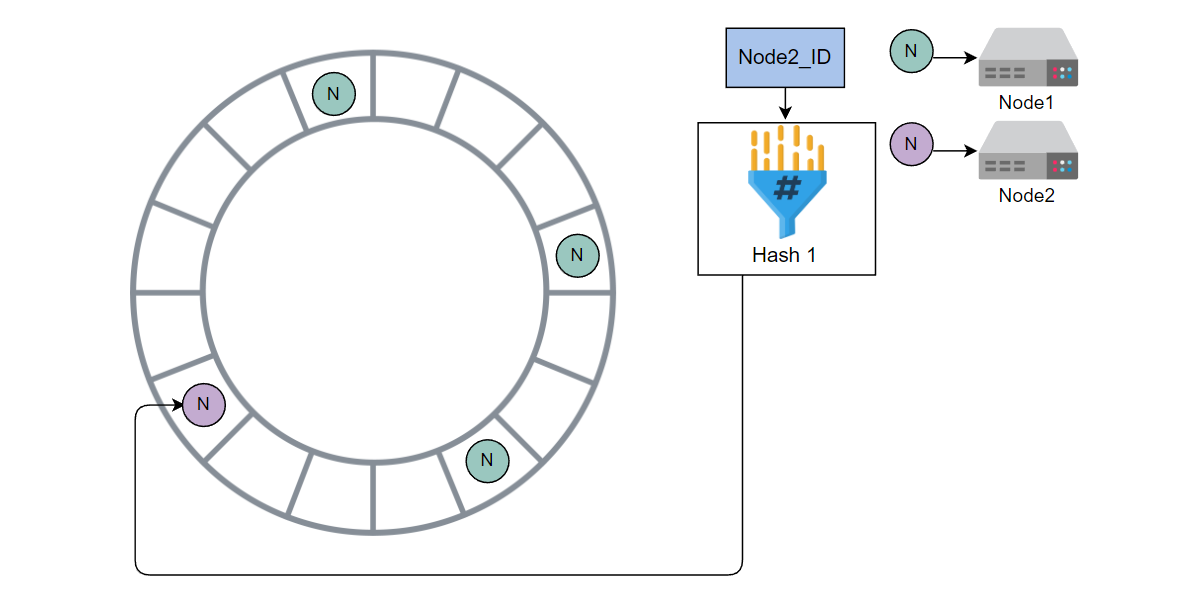
使用哈希 1 计算 Node2 的哈希值,并将其放入环中
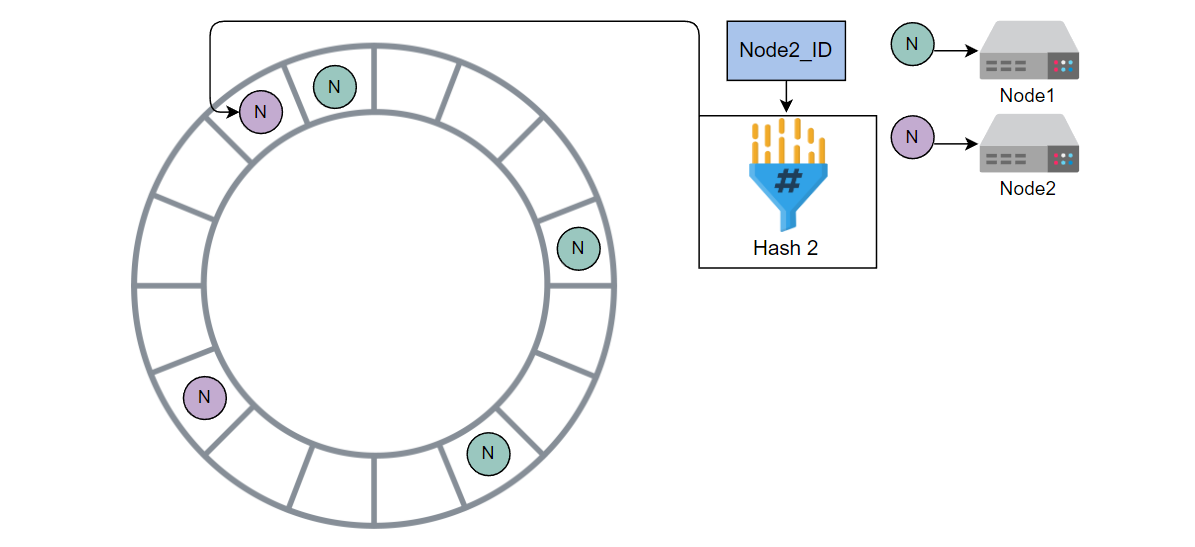
使用哈希 2 计算 Node2 的哈希值,并将其放入环中
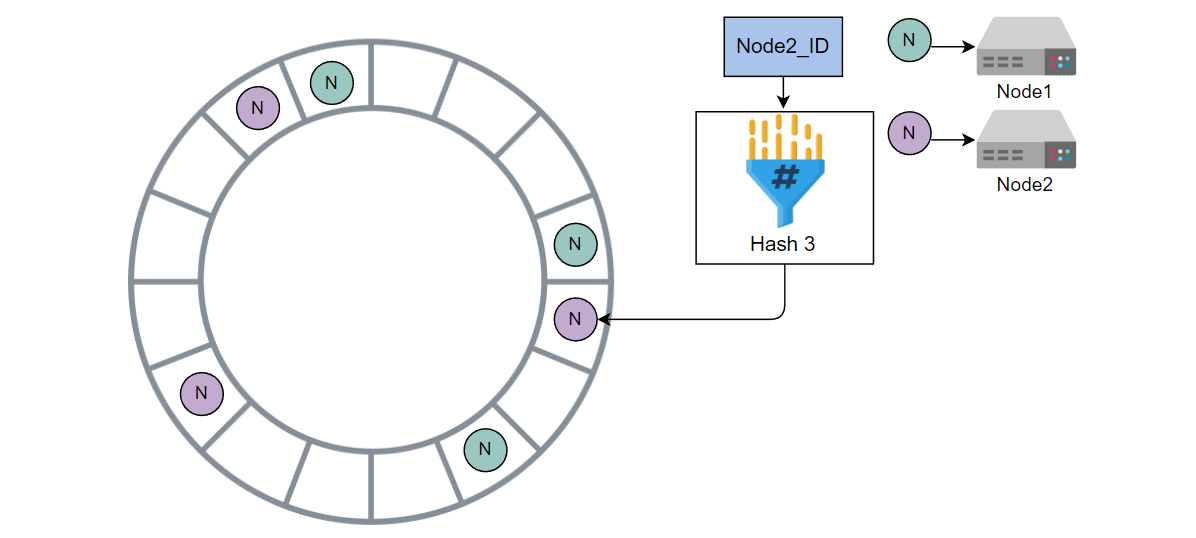
使用哈希 3 计算 Node2 的哈希值,并将其放入环中
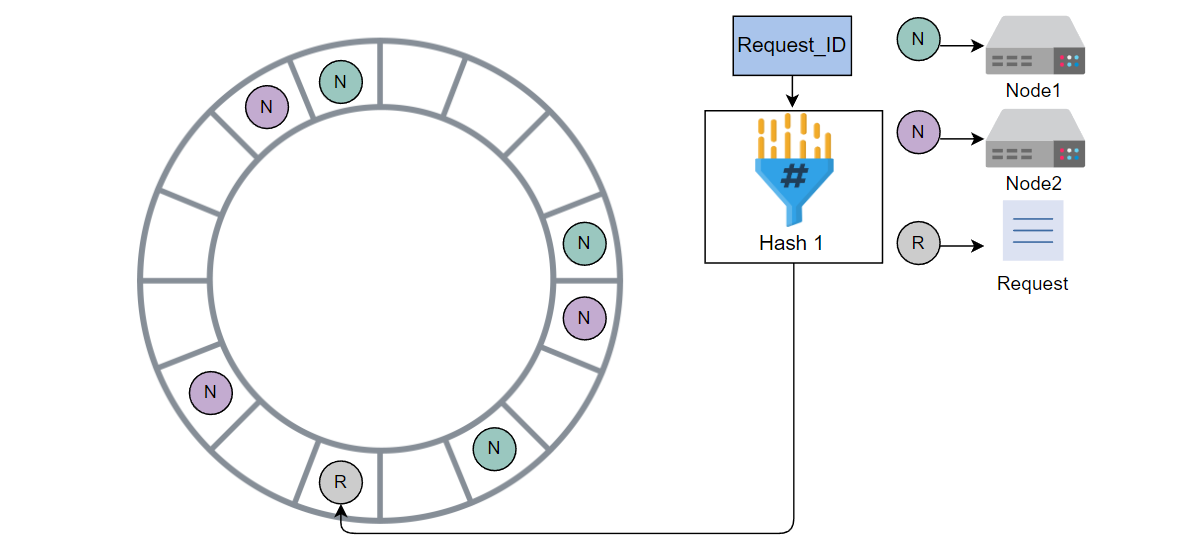
使用哈希 1 计算请求的哈希值,并将请求放入环中
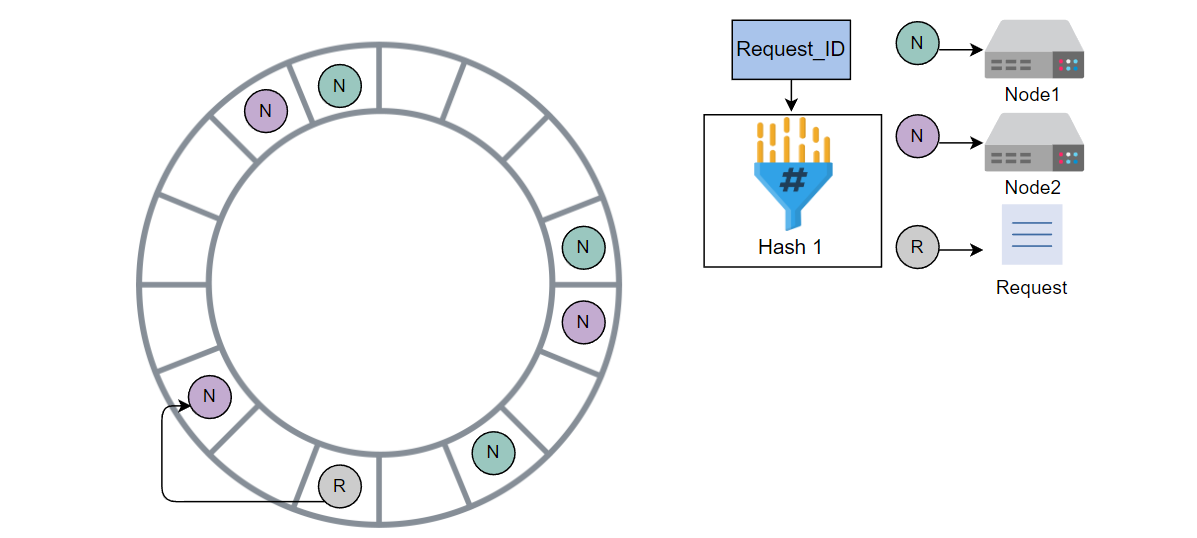
请求将由 Node2 的虚拟节点处理
使用虚拟节点的优点
使用虚拟节点有以下一些优点:
- 如果一个节点失败或需要例行维护,工作负载会均匀地分布到其他节点上。对于每个新可访问的节点,当它重新上线或添加到系统中时,其他节点接收到的负载几乎是相等的。
- 每个节点可以决定它需要负责多少个虚拟节点,考虑到物理基础设施的异构性。例如,如果一个节点的计算能力比其他节点大约多一倍,它可以承担更多的负载。
我们已经使所提出的键值存储设计具有可扩展性。下一个任务是使我们的系统高度可用。
数据复制
我们有各种方法来复制存储。可以是主次关系或对等关系。
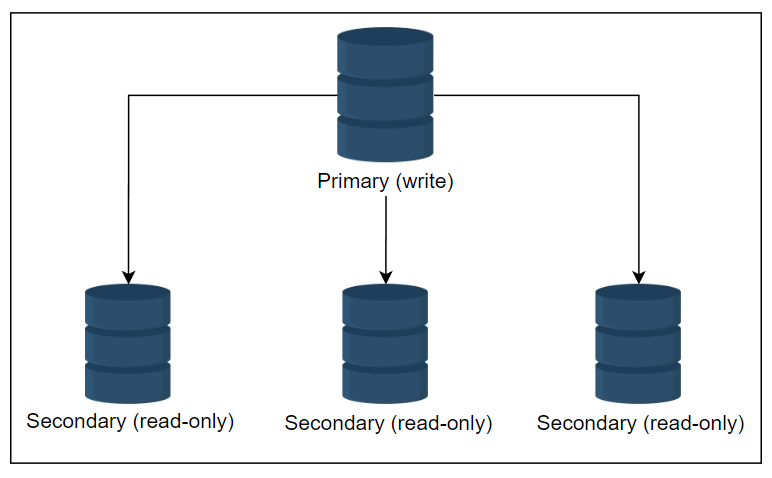
主次关系
在主次关系中,一个存储区是主要的,其他存储区是次要的。
次要存储从主要存储中复制其数据。主要存储提供写请求,而次要存储提供读请求。
写入后,存在一个复制延迟。此外,如果主要存储出现故障,我们无法写入存储,它将成为单点故障。
提示
问题
主次关系是否满足我们在系统设计:键值存储课程中定义的键值存储要求?
答案
我们的要求之一是需要始终具备写入能力。这种方法适用于始终读取选项。
然而,这种方法不包括始终写入的能力,因为它会过载主要存储。此外,如果一个主服务器故障,我们需要将次要存储升级为主要存储。
在切换期间,写入的可用性将会受到影响,因为我们不允许写入。
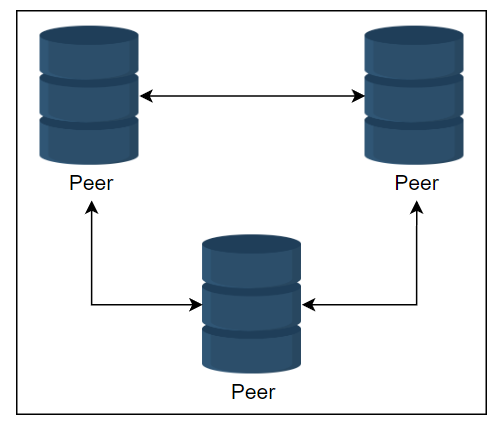
对等关系
在对等关系中,所有涉及的存储区都是主要的,它们复制数据以保持更新。
所有节点都允许读和写。通常,在所有 n 节点中复制是低效和昂贵的。
因此,选择三个或五个存储节点进行复制是常见的选择。
我们将使用对等关系进行复制。我们将在多个主机上复制数据以实现耐用性和高可用性。
每个数据项将在 n 个主机上复制,其中 n 是按键值存储实例配置的参数。例如,如果我们选择 n 为 55,则表示我们希望数据复制到五个节点。
每个节点都会将其数据复制到其他节点。我们将调用一个协调器节点来处理读或写操作。
它直接负责键。协调器节点被分配了键“K”。它还负责将键复制到环上的 n−1 个继承者(顺时针)。
这些继承者虚拟节点列表称为首选项列表。
为了避免在同一物理节点上放置副本,首选项列表可以跳过已经在列表中的那些虚拟节点的物理节点。
让我们考虑下面所示的示例。我们将复制因子 n 设置为 3。对于键“K”,复制是在接下来的三个节点 B、C 和 D 上完成的。同样,对于键“L”,复制是在节点 C、D 和 E 上完成的。
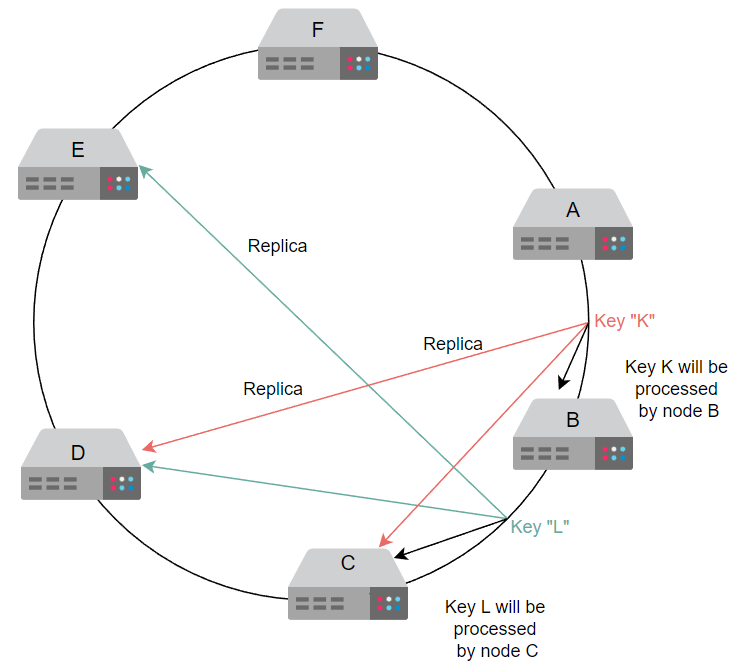
键值存储中的复制
相关信息
问题
同步或异步复制的影响是什么?
答案
在同步复制中,写入速度很慢,因为在向用户确认之前,数据必须复制到所有节点。
它会影响我们的可用性,因此我们不能采用它。当我们选择异步复制时,它允许我们向节点进行快速写入。
在 CAP 定理的上下文中,当存在网络分区时,键值存储可以是一致的或可用的。
对于键值存储,我们更喜欢可用性而不是一致性。这意味着如果两个存储节点失去复制连接,它们将继续处理发送到它们的请求,当连接恢复时,它们将进行同步。
在断开连接的阶段,节点不一致的可能性很高。因此,我们需要解决这些冲突。在下一课中,我们将学习一种使用数据版本控制来处理不一致的概念。