数据库中的权衡
学习何时使用水平分片而不是垂直分片,反之亦然。
哪种数据库分片方法最好?
水平和垂直分片都涉及向我们的计算基础设施添加资源。
我们的业务利益相关者必须决定哪种适合我们的组织。
我们必须根据我们的组织和业务的增长,防止停机时间并减少延迟来相应地扩展我们的资源。
我们可以通过对 CPU、物理内存需求、硬盘调整和网络带宽的组合进行调整来扩展这些资源。
以下部分解释了不分片与分片的利弊。
集中式数据库的优缺点
优点
- 对集中式数据库进行数据维护,如更新和备份,很容易。
- 集中式数据库比分布式数据库提供更强的一致性和 ACID 事务。
- 对于最终程序员来说,集中式数据库提供了更简单的编程模型。
- 对于业务而言,拥有较少的数据可存储在单个节点上更为高效。
缺点
- 当每秒访问集中式数据库的查询数量接近单节点极限时,集中式数据库会变慢,导致终端用户延迟较高。
- 集中式数据库具有单点故障。因此,其无法访问的概率要高得多。
分布式数据库的优缺点
优点
- 从分布式数据库检索数据很快很容易,因为数据是从最近的数据库分片或经常使用的数据库分片中检索的。
- 不同的分布透明级别的数据可以存储在不同的地方。
- 由查询组成的密集事务可以分成多个优化的子查询,这些子查询可以以并行方式处理。
缺点
- 有时需要从多个站点获取数据,这需要比预期更长的时间。
- 关系在不同节点之间垂直或水平分割。因此,如联接等操作需要仔细提取数据以重建完整的关系。这些操作可能变得更加昂贵和复杂。
- 在分布式数据库中维护数据的一致性很难,并且需要额外的措施。
- 分布式数据库中的更新和备份需要时间来同步数据。
分布式数据库中的查询优化和处理速度
分布式数据库中的事务取决于查询类型、涉及的站点(分片)数量、通信速度和其他因素,如底层硬件和使用的数据库类型。
然而,作为一个例子,假设一个查询访问三个表,Store、Product和Sales,这些表存储在不同的站点上。
每个表中的属性数量如下图所示:
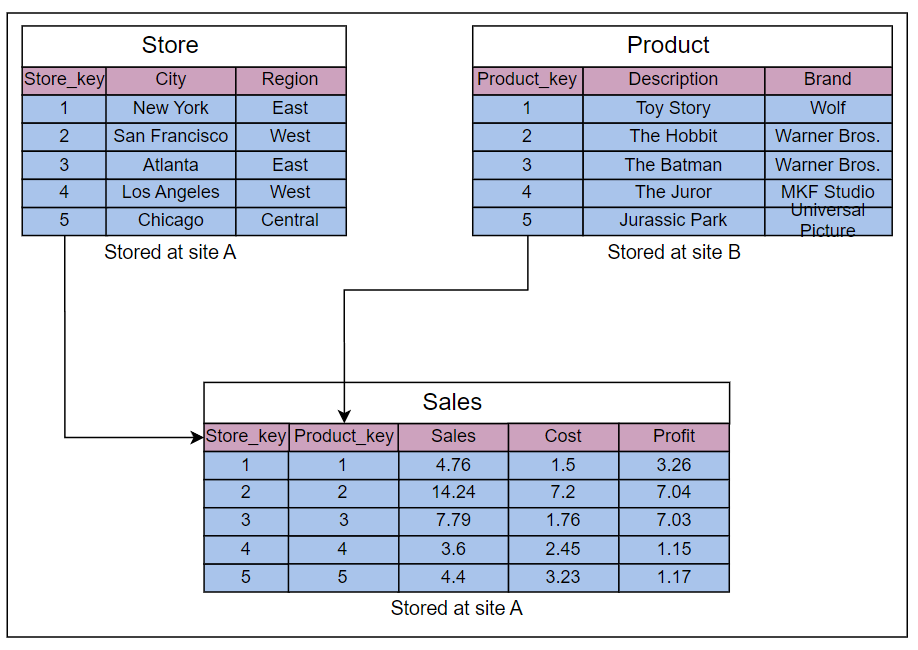
由三个表组成的数据库模式:Store、Product和Sales
假设这两个表在不同的站点上的分布如下:
Store表在A站点上存储了10,000个元组。Product表在B站点上存储了100,000个元组。Sales表在A站点上存储了一百万个元组。
现在,假设我们需要处理以下查询:
Select Store_key from (Store JOIN Sales JOIN Product)
where Region= 'East' AND Brand='Wolf';
上面的查询在Store、Sales和Product表上执行联接操作,并从联接操作结果生成的表中检索Store_key值。
接下来,假设每个存储的元组长度为200位,即25字节。此外,某些中间结果的估计基数如下:
Wolf品牌的数量为10。East地区的商店数量为100,000。
通信假设如下:
- 数据速率== 50M位/秒
- 访问延迟== 0.1秒
参数假设
在使用不同的方法处理查询之前,让我们定义一些参数:
a = 总访问延迟
b = 数据速率
v = 总数据量
现在,根据以下公式计算总通信时间:
让我们尝试以下可能的方法来执行查询。
可能的方法
- 将Product表移动到A站点并在A站点上处理查询。
这里,0.1是A站点上表的访问延迟,100,000是Product表中的元组 数量。对于所有以下计算,200和50,000,000的数字是相同的。
- 将Store和Sales移动到B站点并在B站点上处理查询:
这里,0.2是Store和Product表的访问延迟。10,000和1,000,000是Store和Product表中的元组数量。
- 将Brand在B站点限制为Wolf(称为选择),并将结果移动到A站点:
这里,0.1是Product表的访问延迟。Wolf品牌的数量为10,因此是元组数。
当我们比较这三种方法时,第三种方法提供了最小的延迟(0.1秒)。该示例显示,仔细的查询优化在分布式数据库中也至关重要。
结论
数据分布(垂直和水平分片)跨多个节点旨在改善以下功能,考虑到查询已经优化:
- 可靠性(容错)
- 性能
- 平衡的存储容量和成本
集中式和分布式数据库都有其优缺点。我们应该根据应用程序的需求选择它们。