数据分片
了解数据分片模型以及它们的优缺点。
为什么要进行数据分片?
数据是任何组织的资产。
增加数据和并发读写流量会给传统数据库带来可扩展性压力,从而影响延迟和吞吐量。
传统数据库由于其具有范围查询、二级索引和满足 ACID 特性的事务等特点而受到青睐。
但是,单节点数据库在某些时候已经无法满足负载需求。
我们可能需要将数据分布在许多节点上,但仍要保留关系型数据库的所有优点。
在实践中,为分布式数据库提供单节点数据库类似的属性证明是具有挑战性的。
一种解决方案是将数据移动到类似 NoSQL 的系统中。
但是,历史代码库及其与传统数据库的紧密联系使得解决此问题变得昂贵。
组织可以通过使用第三方解决方案来扩展传统数据库。
但是,集成第三方解决方案通常会带来其复杂性。
更重要的是,有大量机会针对具体问题进行优化,并获得比通用解决方案更好的性能。
数据分片(或分区)使我们能够使用多个节点,每个节点管理整个数据的一部分。为了处理不断增长的查询率和数据量,我们努力实现平衡分区和平衡读写负载。
本课程中我们将讨论不同的数据分片方法、相关挑战以及它们的解决方案。
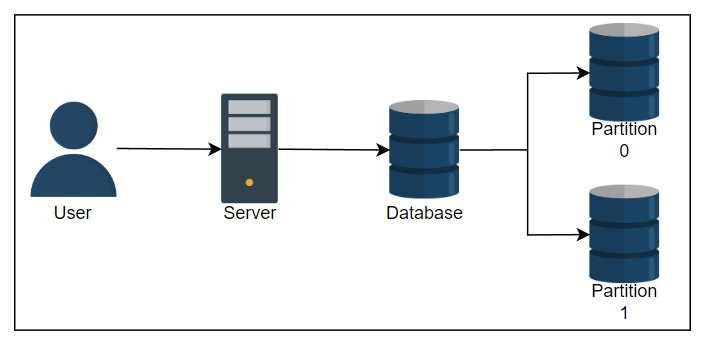
分片
为了将负载分配给多个节点,我们需要通过称为 分片 的现象将数据进行分区。
在这种方法中,我们将一个大数据集拆分成存储在网络上不同节点上的较小数据块。
分片必须平衡,以使每个分片接收大约相同数量的数据。
如果分片不平衡,则大部分查询将落入少数分片中。负载较重的分片将创建系统瓶颈。分片的效果将受到损害,因为大部分数据检索查询将被发送到携带高度拥挤的分片的节点。
这些分片称为热点。通常,我们使用以下两种方式来对数据进行分片:
- 垂直分片
- 水平分片
垂直分片
我们可以将不同的表放在各种数据库实例中,这些实例可能在不同物理服务器上运行。
我们可能将一个表拆分为多个表,以便某些列在一个表中,而其余列在另一个表中。
如果多个表之间存在连接,我们应该小心。我们可能希望将这些表保留在一个分片上。
通常,垂直分片用于提高从包含非常宽的文本或二进制大对象(blob)列的表中检索数据的速度。
在这种情况下,具有大文本或 blob 的列被拆分为不同的表。
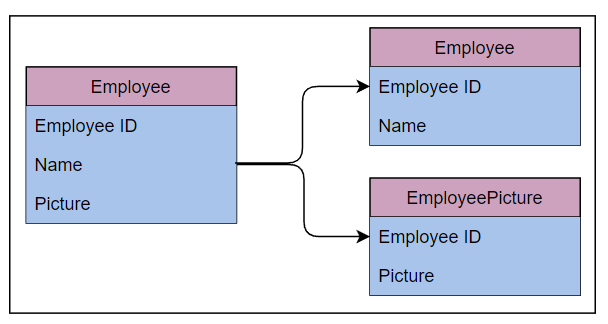
如下图所示,Employee 表被分成了两个表:一个简化的 Employee 表和一个 EmployeePicture 表。
EmployePicture 表只有两列,EmployeID 和 Picture,与原始表分开。
此外,在分区表中添加了 Employee 表的主键 EmpoloyeeID。这使得数据读写更容易,表的重构效率也很高。
垂直分片具有其复杂性,并更适合手动分区,其中利益相关者会仔细决定如何分区数据。相比之下,水平分片适合在动态条件下自动化。
水平分片
有时,数据库中的某些表变得过大并影响读写延迟。水平分片或分区用于通过按行拆分数据将表分成多个表,如下一节中的图所示。原始表的每个分区分布在数据库服务器上,称为分片。通常有两种可用的策略:
- 基于键范围的分片
- 基于哈希的分片
基于键范围的分片
在基于键范围的分片中,将为每个分区分配一组连续的键。
在下图中,使用Customer_Id作为分区键,在Invoice表上执行基于键范围的水平分区。两个不同颜色的表表示分区。
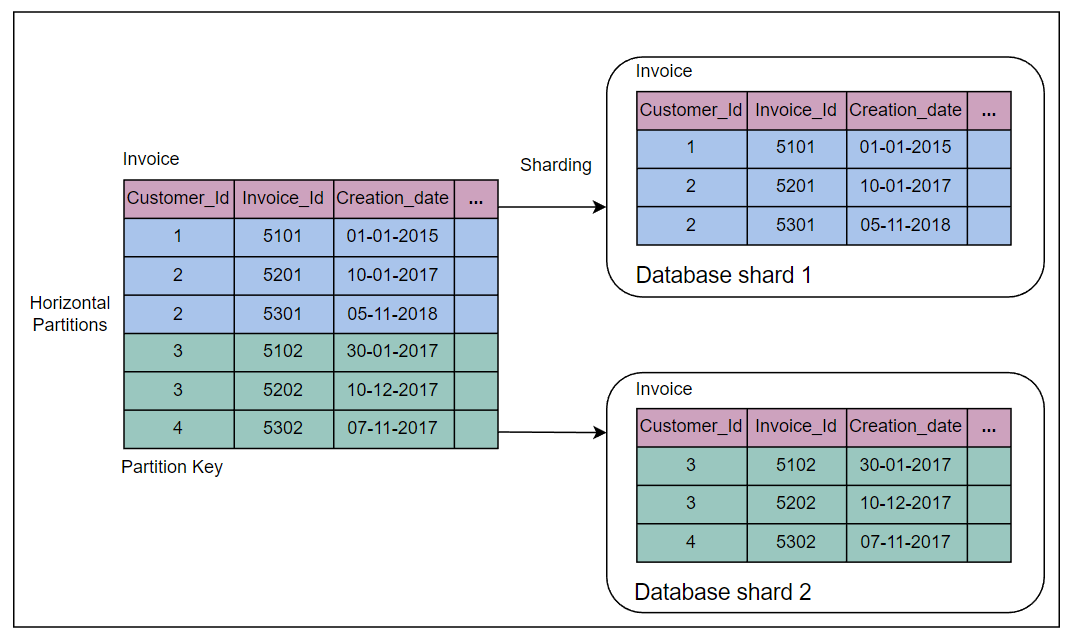
水平分区
有时,一个数据库由多个由外键关系绑定的表组成。
在这种情况下,使用相同的分区键在所有表中执行水平分区。
属于同一分区键的表(或子表)分布在一个数据库分片中。
下图显示了具有相同分区键的多个表放置在单个数据库分片中:
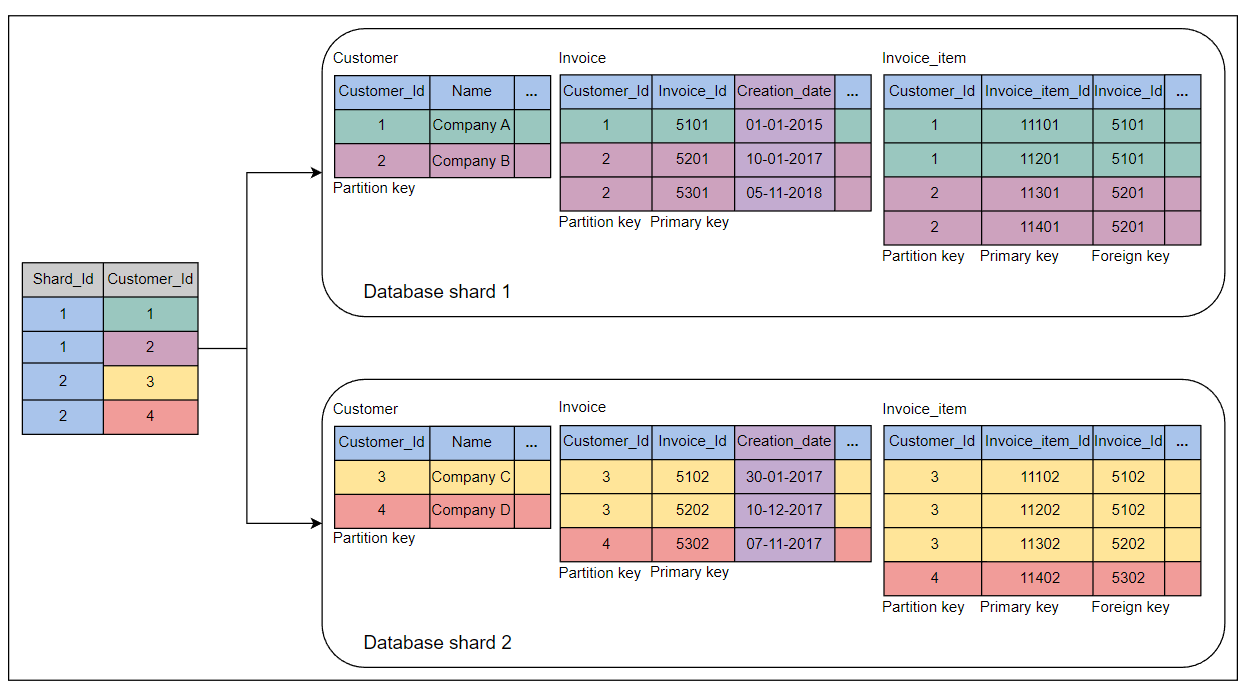
一组表的水平分区
在多表分片中使用的基本设计技术如下:
- 在
Customer映射表中有一个分区键。此表驻留在每个分片上,并存储在分片中使用的分区键。应用程序通过从所有分片读取此表来创建分区键和数据库分片之间的映射逻辑,使映射变得高效。有时,应用程序使用高级算法来确定特定分片所属的分区键的位置。 - 在所有其他表中,将分区键列
Customer_Id作为数据隔离点进行复制。它在增加存储量和有效地定位所需的分片之间有一个权衡。除此之外,它对不同数据库分片的数据和工作负载分配有帮助。数据路由逻辑在应用程序层使用分区键将查询映射到特定的数据库分片。 - 主键在所有数据库分片中都是唯一的,以避免在数据迁移和在线分析处理(OLAP)环境中合并数据时发生键冲突。
- 列
Creation_date作为数据一致性点,假定所有节点的时钟已同步。当必要时,此列用作从所有数据库分片合并数据以形成全局视图的标准。
优点
使用此方法,基于范围查询的方案易于实现。
可以使用分区键执行范围查询,并且这些查询可以按照排序顺序保留在分区中。
缺点
- 无法使用分区键以外的键执行范围查询。
- 如果未正确选择键,则某些节点可能需要存储更多数据,因为流量分布不均匀。
基于哈希的分片
基于哈希的分片使用一个类似哈希的函数对属性进行哈希,它根据进行分区的属性生成不同的值。
主要的概念是在键上使用哈希函数以获取哈希值,然后对分区数取模。
一旦我们找到了适合键的哈希函数,我们可以为每个分区分配一系列哈希值(而不是一系列键)。
哈希值位于该范围内的任何键都将保留在该分区中。
在下图中,我们使用哈希函数 Value mod = n. 其中 n 是节点数量, 即4.
我们通过检查每个键的模来将键分配给节点。具有模值为2的键分配给节点2。
具有模值为1的键分配给节点1。具有模值为3的键分配给节点3。
由于没有具有模值为0的键,因此节点0为空置。
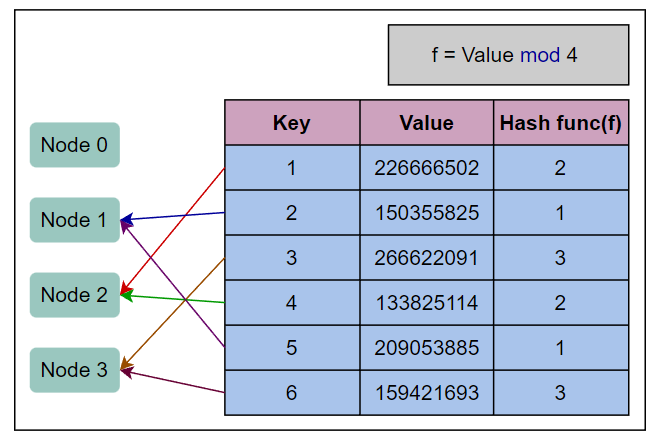
基于哈希的分片
优点
- 键在节点之间均匀分布。
缺点
- 无法使用此技术执行范围查询。键将分布在所有分区中。
相关信息
注意: 每个数据库应有多少个分片?
从经验上来看,我们可以确定每个节点可以提供什么程度的可接受性能。这有助于我们找出希望在任何一个节点上保留的最大数据量。例如,如果我们发现一个节点最多可以放置50 GB的数据,则有以下内容:
数据库大小 == 10 TB
单个分片的大小 == 50 GB
数据库应分布在多少个分片中 == 10 TB / 50 GB == 200个分片
一致性哈希
一致性哈希为分布式哈希表中的每个服务器或项分配一个抽象环上的位置,称为环,而不考虑表中的服务器数量。这允许服务器和对象进行扩展,而不会影响系统的整体性能。
一致性哈希的优点
- 它很容易进行水平扩展。
- 它增加了应用程序的吞吐量并改善了延迟。
一致性哈希的缺点
- 在环中随机分配节点可能导致分布不均。
重新平衡分区
由于许多原因,包括以下原因,查询负载可能在节点之间不平衡:
- 数据的分布不均匀。
- 单个分区负载过重。
- 查询流量增加,我们需要添加更多节点以跟上。
我们可以采用以下策略来重新平衡分区。
避免哈希模n
通常,我们避免使用键的哈希值进行分区(我们之前使用这种方案来简单说明哈希的概念)。在 hashmod n 的情况下,添加或删除节点的问题在于每个节点的分区编号都会更改,导致大量数据移动。
例如,假设 hash(key)=1235
如果一开始有五个节点,则该键将从节点1开始(1235 mod 5 = 0).
现在,如果添加了一个新节点,则该键必须移动到节点6(1235 mod 6 = 5)等。
这将导致键从一个节点移动到另一个节点,使重新平衡成本高昂。
固定数量的分区
在这种方法中,在设置数据库时,分区数量是固定的。
我们创建比节点更多的分区,并将这些分区分配给节点。
因此,当向系统添加新节点时,它可以从现有节点中获取一些分区,直到分区平均分配。
这种方法存在一个缺点。
随着群集中总数据量的增加,每个分区的大小也会增加,因为所有分区都包含总数据的一小部分。
如果一个分区非常小,那么将导致太多的开销,因为我们可能需要创建大量小的分区,每个分区都会给我们带来一些开销。
如果分区非常大,则重新平衡节点和从节点故障中恢复的成本将很高。
选择正确的分区数量非常重要。
固定数量的分区用于Elasticsearch、Riak等等。
动态分区
在这种方法中,当分区的大小达到阈值时,它会被平均分成两个分区。
其中一个分裂分区被分配给一个节点,另一个分裂分区被分配给另一个节点。
这样,负载就平均分配了。分区数量根据总数据量自适应,这是动态分区的一个优点。
但是,这种方法存在一个缺点。在提供读写服务时很难应用动态重平衡。
HBase和MongoDB中使用了这种方法。
按节点比例分区
在这种方法中,分区数量与节点数量成比例,这意味着每个节点具有固定分区。
在之前的方法中,分区数量取决于数据集的大小。这里并不是这样。当节点数量保持不变时,每个分区的大小随着数据集的大小而增加。但是,随着节点数量的增加,分区会缩小。
当新节点进入网络时,它会随机分割一定数量的当前分区,然后将拆分的一半分配给自己,另一半则保持不变。
这可能导致不公平的分配。Cassandra和Ketama使用了这种方法。
提示
问题
谁执行重平衡?它是自动还是手动的?
答案
执行重平衡有两种方式:自动和手动。
在自动重平衡中,没有管理员。系统确定何时执行分区以及何时将数据从一个节点移动到另一个节点。
在手动重平衡中,管理员确定何时以及如何执行分区。
组织根据其需求进行重平衡。有些使用自动重平衡,有些使用手动重平衡。
分区和二级索引
我们已经讨论了基于键值数据模型的分区方案,在这些方案中,记录是通过主键检索的。但是,如果我们必须通过二级索引访问记录怎么办?二级索引是不通过主键识别记录,而只是搜索某个值的一种方法。例如,上面的 水平分区的图示 包含客户表,搜索所有创建年份相同的客户。
我们可以按以下方式对二级索引进行分区。
按文档对二级索引进行分区
在这种索引方法中,每个分区都是完全独立的。
每个分区都有自己的二级索引,仅覆盖该分区中的文档。它不涉及其他分区中保存的数据。
如果我们想要将任何内容写入我们的数据库,我们只需处理包含我们正在写入的文档ID的分区。
它也被称为本地索引。在下面的图示中,有三个分区,每个分区都有自己的身份和数据。
如果我们想要获取所有名为John的客户ID,我们必须从所有分区请求。
但是,这种在二级索引上的查询可能很昂贵。
由于受到性能差的分区延迟的限制,读查询延迟可能会增加。
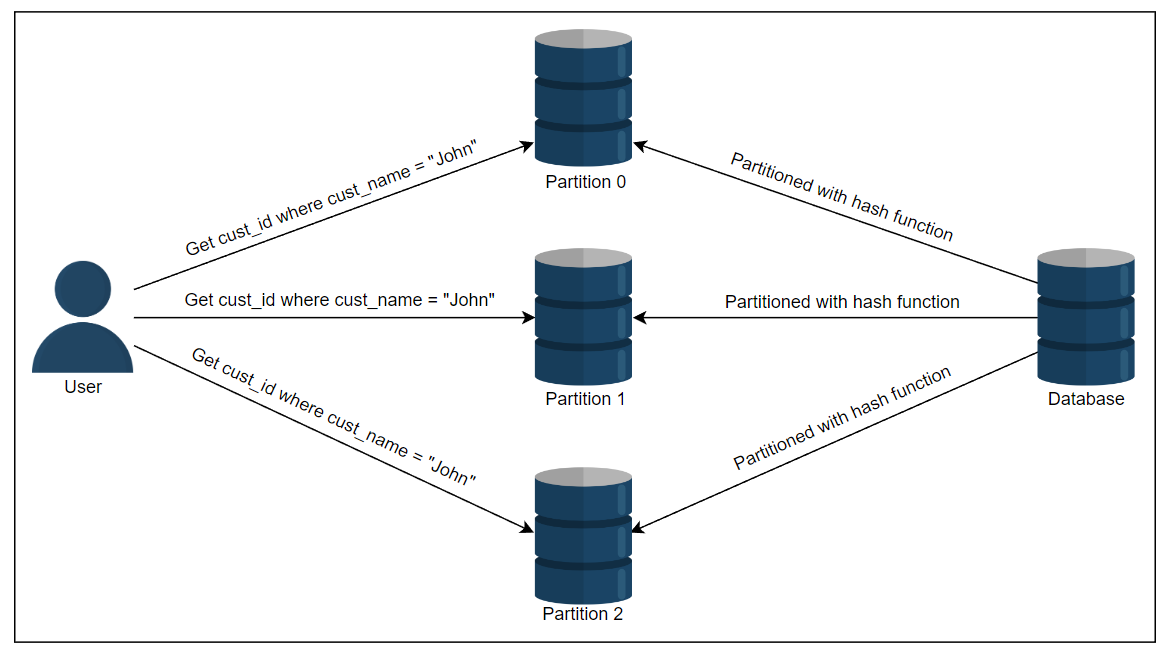
按词项对二级索引进行分区
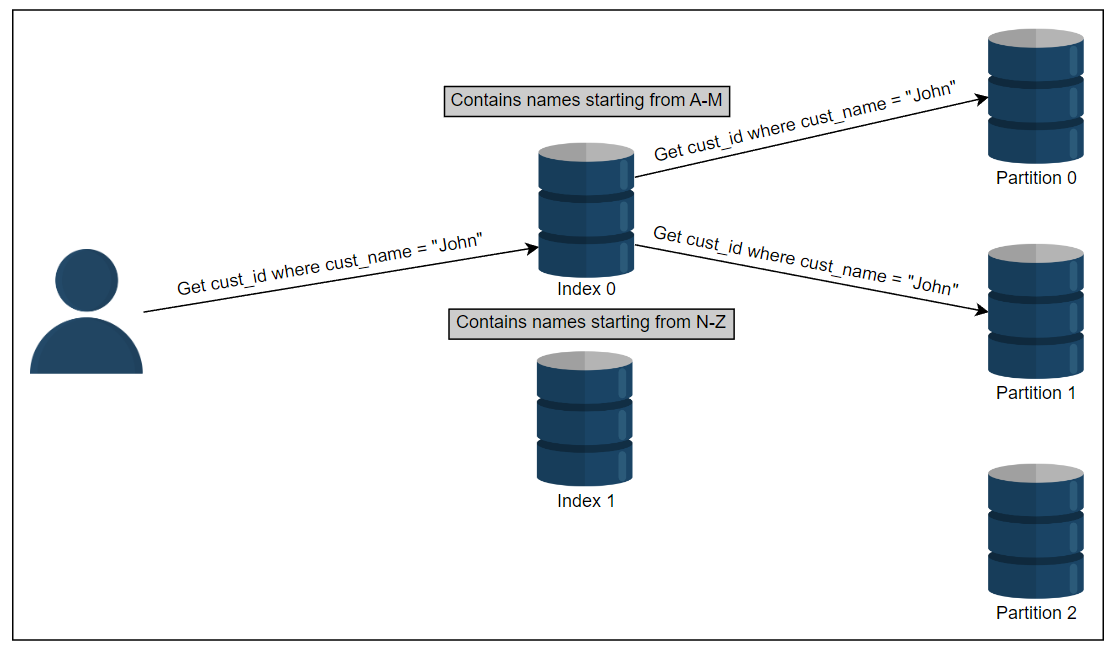
我们可以为二级词项创建一个全局索引,该索引包含来自所有分区的数据,而不是为每个分区创建二级索引(本地索引)。
在下面的图示中,我们对名称(我们进行分区的词项)创建索引,并将所有名称的索引存储在分离的节点上。
要获取所有名为John的客户的cust_id,我们必须确定我们的词项索引位于何处。
index 0包含所有以“A”到“M”开头的客户。
index 1 包括所有名称以“ N”至“ Z”开头的客户。
因为 John 在 index 0 中,我们从 index 0 获取具有名称 John 的 cust_id 列表。
按术语对次要索引进行分区比按文档进行次要索引的分区更具有读取效率。
这是因为它仅访问包含该术语的分区。但是,此方法中的单个写入影响多个分区,使方法变得写入密集和复杂。
请求路由
我们已经学习了如何对数据进行分区。
然而,这里有一个问题:客户端在发出请求时如何知道连接哪个节点?
在重新平衡之后,分区分配给节点会发生变化?
如果我们要读取特定的键,我们如何知道需要连接哪个IP地址才能进行读取?
这个问题也被称为服务发现。以下是解决这个问题的几种方法:
- 允许客户端请求网络中的任何节点。如果该节点不包含所请求的数据,则将该请求转发到包含相关数据的节点。
- 第二种方法包含一个路由层。所有请求都首先转发到路由层,然后它确定要连接哪个节点来满足请求。
- 客户端已经具有与分区相关的信息以及哪个分区连接到哪个节点的信息。因此,它们可以直接联系包含它们需要的数据的节点。
在所有这些方法中,主要的挑战是如何使这些组件知道节点分区的更新。
ZooKeeper
为了跟踪群集中的更改,许多分布式数据系统需要一个单独的管理服务器,例如ZooKeeper。
Zookeeper 跟踪网络中的所有映射,每个节点都连接到ZooKeeper以获取信息。
每当节点分区发生更改、添加或删除节点时,ZooKeeper会更新并通知路由层有关更改的信息
HBase、Kafka和SolrCloud使用ZooKeeper。
结论
对于所有当前的分布式系统,分区已成为标准协议。
由于系统包含的数据量不断增加,对数据进行分区是有意义的,因为它可以加快写入和读取速度。
它增加了系统的可用性、可扩展性和性能。