分片计数器的详细设计
学习关于分片计数器的详细设计。
详细设计
现在我们将详细讨论分片计数器的三个主要功能——创建、写入和读取。我们将使用 Twitter 作为例子来回答许多重要的问题,其中包括:
- 对于每个新推文,应创建多少个分片?
- 如何为特定的推文递增分片值?
- 当来自终端用户的读取请求到达系统时,系统会发生什么?
分片计数器的创建
正如我们之前所讨论的那样,当用户在 Twitter 上发布推文时,会调用 \createCounter API。系统会为每篇新建的帖子创建多个计数器。以下是针对每个新推文创建的主要计数器列表:
- 推文喜欢计数器
- 推文回复计数器
- 推文转发计数器
- 如果推文包含视频,则为推文视图计数器
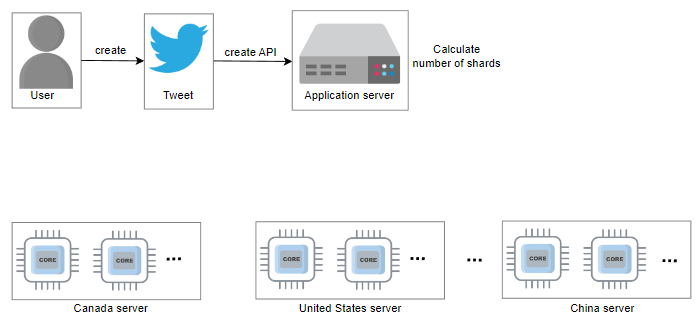
现在,问题是系统如何决定每个计数器中的分片数?分片数对于良好的性能至关重要。如果特定写入工作负载的分片数较少,我们会遇到高写入争用,从而导致写入缓慢。另一方面,如果特定写入负载的分片数过高,我们将在读取操作上遇到更高的开销。读取缓慢的原因是因为从可能驻留在不同地理分布式数据中心内的不同节点上收集值的所有分片的值都会被添加。计数器值的读取成本随着分片数的增加而线性上升,因为所有相应计数器的分片的值都会被添加。随着添加新分片的请求数的增加,写入按比例增长。因此,在快速编写与读取性能之间需要进行权衡。我们稍后将讨论如何提高读取性能。
关于分片数的决策取决于许多因素,其中共同尝试在短期内预测特定计数器上的写入负载。对于推文,这些因素包括关注者数量。 Twitter 上拥有数百万关注者的用户的推文比 Twitter 上关注者较少的用户的推文更可能获得许多(通常是百万级别的)喜欢。有时,名人推文包含一个或多个标签。系统还为此标签创建分片计数器,因为它有很高的可能性被标记为趋势。
许多以人为中心的活动常常具有长尾活动模式,在这种模式下,许多人集中在一个相对较小的活动集上。也许缩短的注意力可能正在发挥作用。这意味着在一段时间之后,喜欢的狂潮将消失,现在可能不需要像之前那样多的分片来处理计数器。同样,对于未来写入的初始预测可能会出错,我们可能需要更多的分片来处理写入请求。我们要求我们的系统可以根据当前需求动态扩展或缩小分片的数量。
我们需要监视所有分片的写入负载,以适当地将请求路由到特定的分片,可能使用负载均衡器。这样的反馈机制还可以帮助我们决定何时关闭某些计数器的分片以及何时添加额外的分片。此过程不仅为最终用户提供良好的性能,而且可以在近乎最优的水平上利用我们的资源。
问题:当拥有少数关注者的用户在 Twitter 上发布病毒视频时会发生什么?
答案:系统需要检测到这种情况,其中计数器意外开始获得非常高的写入流量。我们将动态增加受影响计数器的分片数量以减轻情况。
大量写入请求
正如我们之前提到的,数百万用户与我们示例名人的推文进行交互,最终向系统发送一连串的写请求。系统将每个写请求分配到特定推文的指定计数器的可用分片上。系统如何选择在不同计算单元(节点)上运行的这些分片来分配写请求呢?我们可以使用三种方法来解决这个问题:
轮询选择
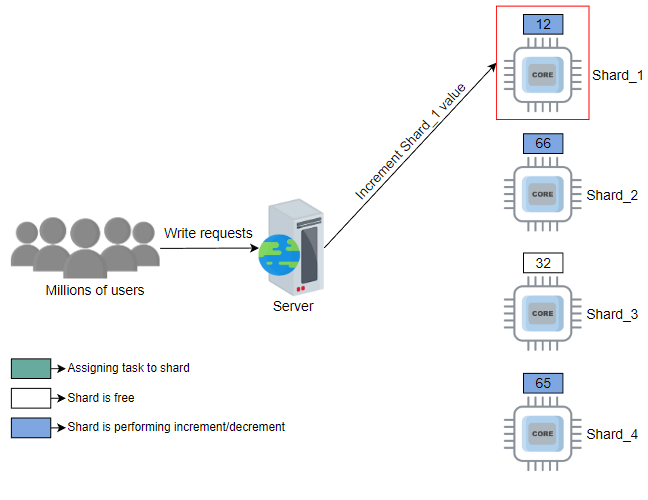
解决上述问题的一种方法是使用分片的轮询选择。例如,假设分片数为100。系统从shard_1开始,然后是shard_2,一直到shard_100。通常,轮询工作分配会在不考虑当前负载状态的情况下过载或未充分利用资源。但是,如果每个请求都相似(且大致需要相同的服务时间),则可以使用轮询方法,并且其简单性很有吸引力。
在下面的示例中,我们假设用户请求首先由负载均衡器分配至适当的服务器。然后,每个这样的服务器使用自己的轮询调度来使用分片:
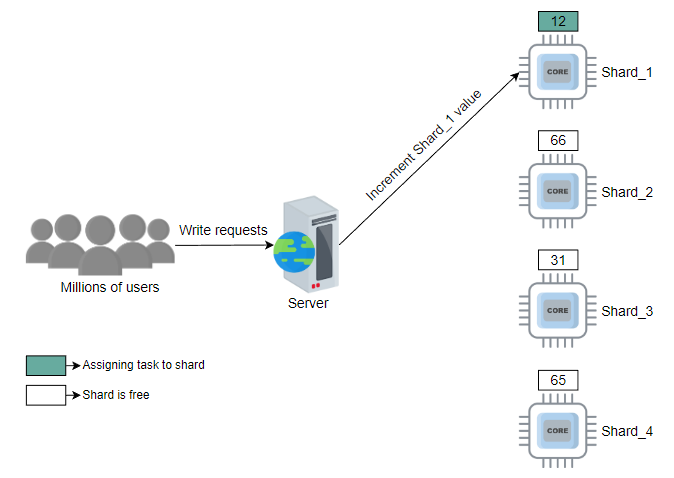
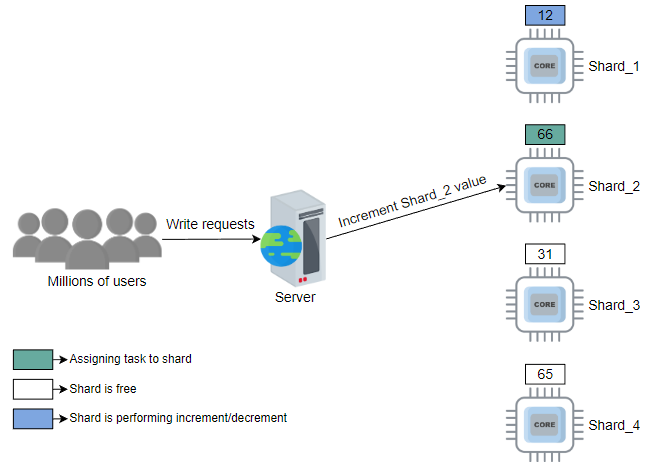
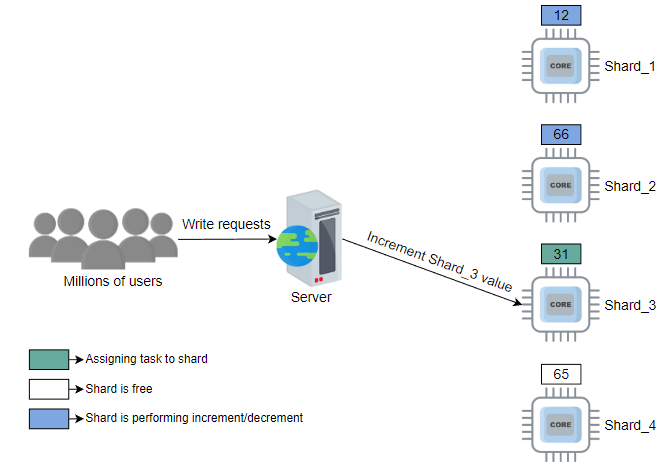
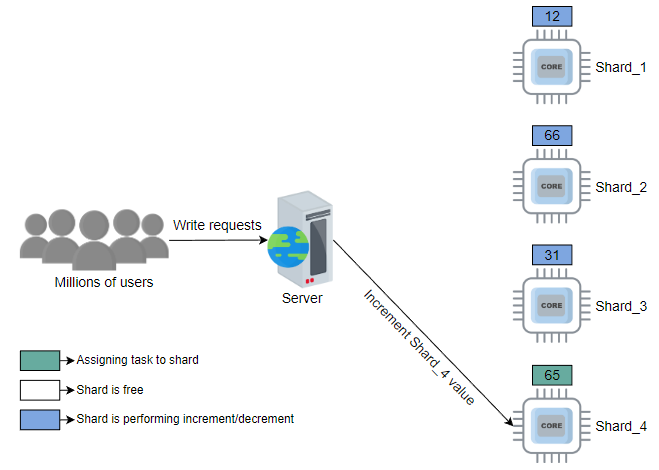
随机选择
另一种简单的方法是均匀随机地选择要写入的分片。轮询选择和随机选择的问题在于节点(其中分片被托管)上的负载变化不确定。要适当地分配可用的分片负载很困难。节点上的负载变化很常见,因为物理节点通常被用于多种目的。
基于指标的选择
第三种方法是基于特定指标进行分片选择。例如,专用节点(负载均衡器)通过读取分片的状态来管理分片的选择。下面的幻灯片将介绍如何创建分片的计数器:
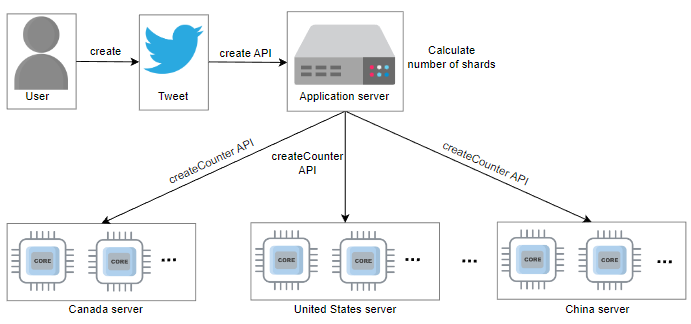
管理读取请求
当用户发送读取请求时,系统将汇总指定计数器的所有分片的值以返回该特性的总计数(如点赞或回复)。对于每个读取请求,从所有分片累积值将导致低读取吞吐量和高读取延迟。
系统何时对所有分片的值进行求和的决定也非常关键。如果同时有高写入流量和读取请求,则几乎不可能获得实际的当前值,因为在将读取值报告给客户端时,它已经发生了更改。因此,定期读取计数器的所有分片并缓存它应该可以满足大多数用例。通过缩短累计周期,我们可以提高读取值的准确性。
问题:您能想到一个使用上述一致性模型的用例,可能不适合分片计数器吗?
答案:在需要强一致性的情况下,我们可能不会使用松散一致性模型的共享计数器。一个例子可以是读后写场景,其中我们需要在修改之前获取准确的值(实际上,这样的场景需要事务支持)。
使用分片计数器解决前 K 问题
本节将讨论如何使用分片计数器来解决一个名为 前 K 问题 的实际问题。我们将继续以实时应用程序 Twitter 为例,其中计算趋势是 Twitter 的前 K 问题之一。这里, 表示前 个趋势的数量。许多用户在他们的推文中使用各种标签。基于地区管理数百万个标签的计数,以在各个用户的趋势时间轴中显示它们,是一个巨大的挑战。
分片计数器是上述问题的关键。如前所述,在 Twitter 上,系统为每个标签创建计数器,并根据在推文中使用该标签的用户的关注者决定分片计数。当 Twitter 用户再次在他们的推文中使用相同的标签时,计数将保持最初创建的同一计数器。
Twitter 主要基于特定标签在用户地区的流行度来显示趋势。Twitter 将为每个讨论度量值维护一个单独的计数器和一个全局标签计数器。让我们讨论每个度量值的详细信息如下:
- 按地区分的标签计数 表示在特定地理区域内使用相同标签的推文数量。例如,来自纽约市的数千条具有相同标签的推文表明纽约地区的用户可能在他们的趋势时间轴中看到这个标签。
- 时间窗口 表示专门标记的推文被发布的时间段。
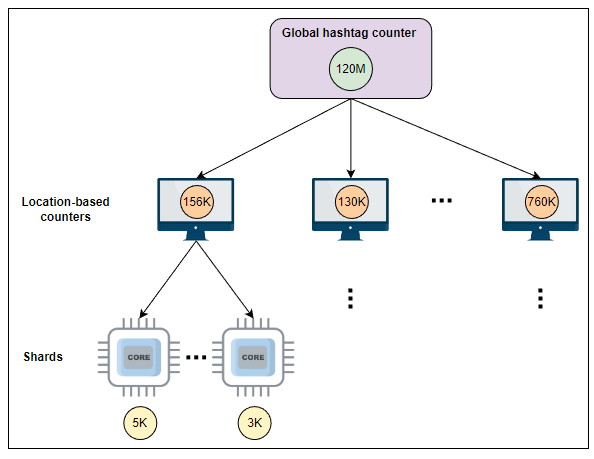
下面是上述示例的更多详细信息:
- 全局标签计数器 表示所有基于地理位置的计数器的总和。
- 基于位置的计数器 在系统在指定时间达到设定阈值并且标签成为某些用户的趋势时,代表它们当前的计数。例如,Twitter 将 10,000 设置为阈值。当基于位置的标签计数达到 10,000 时,Twitter 将在使用该标签的各个国家地区的用户的趋势时间轴中显示这些标签。如果所有国家的计数都增加,指定的标签可能在全球范围内显示。
接下来,我们将讨论显示在用户主页时间轴中的前 K 推文。前 K 推文包括用户正在关注的账户、用户已经点赞的推文以及用户正在关注的账户的转推。推文在前 K 问题中根据关注者数量和时间优先级获得优先权。根据推文的流行度和位置,Twitter 在用户的主页时间轴中还显示推广推文和用户未关注的某些推文。
提示
Twitter 还使用其他指标来优化前 K 选择,但我们在此讨论了主要指标。
分片计数器的放置
一个重要的问题是我们应该将共享计数器放置在哪里。它们应该驻留在应用服务器的同一节点上,还是在数据中心的单独节点上,还是在接近最终用户的网络边缘的 CDN 节点上?这个问题的确切答案取决于我们的具体用例。对于 Twitter,我们可以通过将分片计数器放置在用户附近来计算计数,这也有助于有效处理重量级和前 K 问题。
问题:是否应在累加值之前锁定计数器的所有分片?
答案:不需要跨分片锁定即可并发进行读写操作。如果使用跨分片锁定,将会破坏写入性能,这也是我们使用分片计数器的原因。在一个松散一致性模型下,计数器的值可能不会反映当前确切的值,因此不需要在所有分片上同时进行读锁定。但是,根据具体情况,如果读取频率非常低,则可能会使用这种机制。读取可以将计数器值存储在适当的数据存储中,并依赖于各自的数据存储进行读取可扩展性。
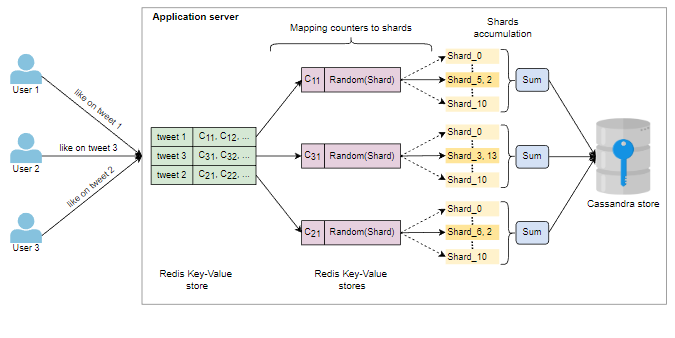
Cassandra存储可以用于维护特定区域用户的浏览量、点赞量、评论量和许多其他计数器。这些计数器代表了特定计数器的所有分片的最后计算总和。当用户生成时间线时,读请求被转发到最近的服务器,然后可以使用存储中持久化的值进行响应。这种存储还有助于显示区域性的前K趋势。本地前K趋势列表被发送到应用服务器,然后应用服务器对所有列表进行排序,以生成全局前K趋势列表。最终,应用服务器将所有计数器的详细信息发送到缓存中。
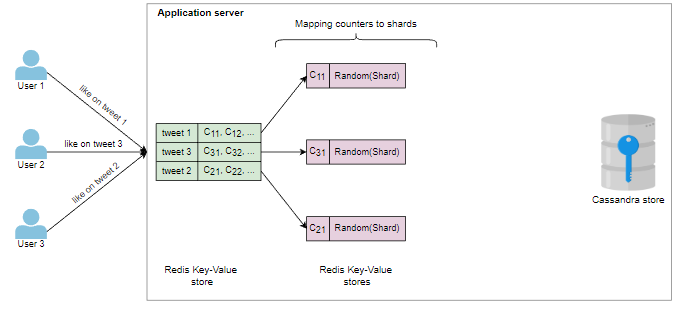
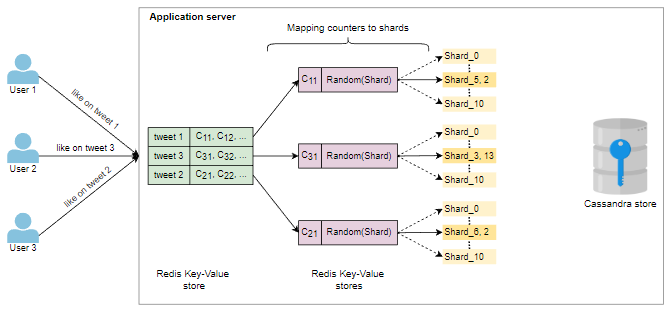
我们还需要存储分片计数器,其中包含有关它们及其元数据的所有信息。此处Redis或Memcache服务器可以发挥重要作用。例如,每个推文的唯一ID可以成为键,而此键的值可以是计数器ID或计数器ID列表(如计数器、回复计数器等)。此外,每个计数器ID都有其自己的键值存储,其中计数器ID(例如点赞计数器)是键,而值是分配分片的列表。
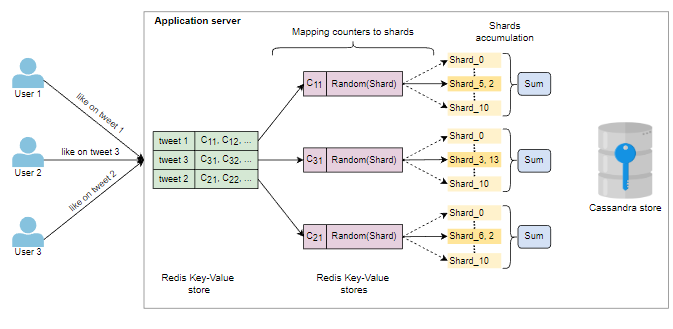
识别相关计数器并将所有写入请求映射到分片计数器的适当计数器的工作可以并行进行。我们将所有写请求映射到适当的计数器,然后每个计数器基于某些指标随机选择一个分片来进行增量和减量。相比之下,我们周期性地减少特定计数器的所有分片的值。然后,这些计数器值可以存储在Cassandra存储中。以下图片有助于说明这些要点:

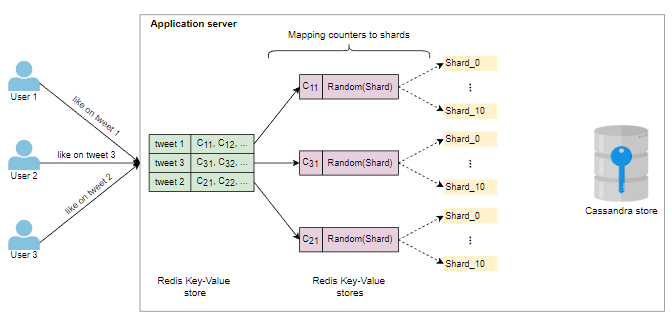
分片计数器的评估
本节将评估分片计数器,并解释如何通过提供高可用性和可扩展性来提高性能。
可用性
任何一个特性(例如点赞、浏览或回复)的单个计数器都有一个单点故障的高风险。通过运行特定计数器的许多分片,分片计数器消除了单点故障。即使某些分片崩溃或出现故障,系统仍然可用。这样,分片计数器就提供了高可用性。
可扩展性
分片计数器允许根据需要进行高水平扩展。可以轻松向系统中添加在其他节点上运行的分片,以扩展我们的操作能力。最终,这些额外的分片也会增加系统的性能。
可靠性
另一个分片计数器的主要目的是通过将每个写请求映射到特定的分片来减少大规模的写入请求。每个写请求在到来时都会被处理,没有请求在队列中等待。由于这一点,命中率提高了,系统的可靠性也增加了。此外,系统会定期将计算出的计数保存在稳定的存储中——在这种情况下是Cassandra。
结论
现在,分片计数器是提高巨大服务整体性能的关键因素。它们提供高可扩展性、可用性和可靠性。分片计数器解决了一些重要的问题,包括大规模应用程序中非常常见的重负载和Top K问题。