分布式任务调度器的设计考虑因素
了解分布式任务调度器的设计考虑因素。
队列
分布式队列是调度器使用的一个重要组成部分。最简单的调度方法是按先进先出原则将任务推入队列中。
如果在集群(云)中有10,000个节点(资源),任务调度器会快速从队列中提取任务并将其调度到节点上。
但是,如果所有资源都在忙于处理其他任务,则任务将需要等待在队列中,小型任务可能需要等待更长时间。
这种调度机制会影响系统的可靠性、可用性和任务的优先级。有些情况下,我们需要紧急执行任务,例如通知用户他们的账户被从未识别的设备访问了的任务。
因此,我们不能仅依赖先进先出来调度任务。相反,我们将任务分类并设置适当的优先级。我们有以下三种任务类别:
- 不能延迟的任务。
- 可以延迟的任务。
- 需要定期执行的任务(例如,每5分钟,每小时,或每天执行一次)。
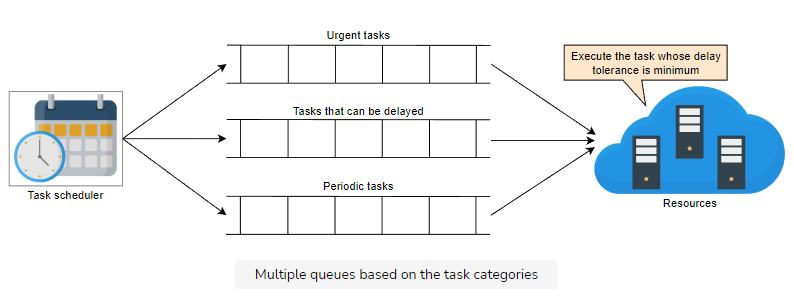
我们的系统确保非紧急任务队列中的任务不会被饥饿。一旦某个任务的延迟极限即将到达,它就会被移动到紧急任务队列中,以便得到服务。
我们将在本课程后面看到任务调度器如何实现优先级。
让我们探讨一些参数,这些参数有助于调度器高效地利用资源并为用户提供可靠的服务。
执行限制
有些任务需要执行很长时间,占用资源并阻塞其他任务。
执行限制是在调度任务时需要考虑的重要参数。如果我们将整个资源完全分配给单个任务,并等待该任务完成,那么某些任务可能无法停止,因为任务脚本中的一个错误不允许其完成执行。
我们让客户端为其任务设置执行限制。在指定的时间后,我们应该停止任务的执行,释放资源,并将其分配给队列中的下一个任务。
如果任务执行因执行限制而停止,我们的系统会通知相关的客户端。客户端需要为这种情况采取适当的补救措施。
如果客户端未设置执行限制,则调度程序使用默认的最大允许时间上限来终止任务。
假设任务实际上需要更长时间(例如,如果我们正在训练一个机器学习模型),那么调度程序可能需要多次暂停和恢复任务,以容纳其他任务。
对于必须等待两天才能使用资源两秒钟的短任务而言,这是不公平的。
云服务提供商不能让任务在基本(免费)帐户中无限期执行,因为使用其资源对提供商来说是一定的费用。
为了处理这种情况,客户端被告知最大使用限制,以便他们可以处理长时间执行的任务。
例如,客户端可以设计任务,在一段时间后进行检查点,并从该状态加载以便在资源因使用限制而被客户端取走时恢复进度。
相关信息
问题
如果一个长任务已经执行了90%,但在完成之前,执行该任务的机器出现故障怎么办?
答案
任务调度程序将在其他机器上重新执行该任务。任务需要具有幂等性,这将在本课程的后面进行讨论,或者它们应该能够从以前的检查点恢复其状态。
一旦状态被保存,我们可以在任何其他机器上恢复该任务的执行。这使我们的系统具有容错性并节省了我们的资源。
优先级
有些任务需要紧急执行。
例如,在像Facebook这样的社交应用中,用户可以在紧急情况(如地震)下标记自己的安全状态。
执行此操作的任务应及时执行,否则该功能对Facebook用户没有用。
向客户发送一封电子邮件通知他们的帐户被扣除了一定金额是另一个需要紧急执行的任务的例子。
为了确定任务的优先级,任务调度程序为每个任务维护一个延迟容限参数,并在接近其延迟容限的时间执行该任务。
延迟容限是任务执行可能被延迟的最长时间。具有最短延迟容限时间的任务首先被执行。
通过使用延迟容限参数,我们可以推迟具有更长延迟容限值的任务,以便在高峰期为紧急任务腾出空间。
相关信息
问题
我们如何确定延迟容限的值?
答案
由于不同应用程序中有不同类别的任务,应用程序所有者或客户端可以根据任务类别自行设置或自动化值。
例如,在像Facebook这样的社交媒体应用中,我们可以生成新闻动态,推荐朋友,允许用户在灾难后标记自己的安全状态,发送关于直播活动的通知等等。
在列出的任务中,标记人在地震期间的安全和发送有关直播活动的通知应是优先级任务。
客户端可以将这些任务的延迟容限值缩小到毫秒或几秒钟,而像推荐朋友这样的任务可以推迟几天。
任务调度系统本身可以根据任务类别及其严重程度设置延迟容限值。
对于不同的优先级,有不同的成本(例如,高优先级任务通常有更高的成本),因此客户可以仔细分类其任务。
资源容量优化
有时候资源可能接近超载阈值(例如,利用率高于80%),这被称为高峰时间。同一资源在低峰时间可能处于空闲状态。
因此,我们必须考虑如何在低峰时间更好地利用资源,并在高峰时间保持资源可用。
有些任务不需要紧急执行。
例如,在类似 Facebook 的社交应用程序中,推荐好友并不是紧急任务。
我们可以为此类任务建立单独的队列,并在低峰时间执行它们。
如果我们的工作量始终超过可用资源,那么可能存在容量问题,为了解决这个问题,我们应该增加更多资源。
云服务提供商需要有一个目标的资源需求比。当需求开始增加时,这个比例将向0移动。
如果这个比例随着时间的推移而改变,服务提供商可能会决定增加或减少资源。
任务幂等性
如果任务成功执行,但由于某种原因,机器未能发送确认消息,则调度程序将再次安排任务。任务再次执行,我们就会得到错误的结果,这意味着任务是非幂等的。以下是一个非幂等性的示例:
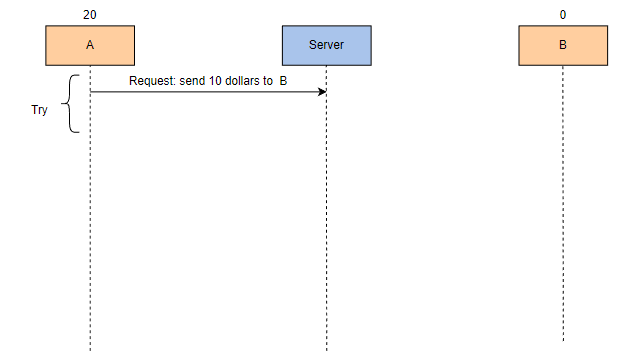
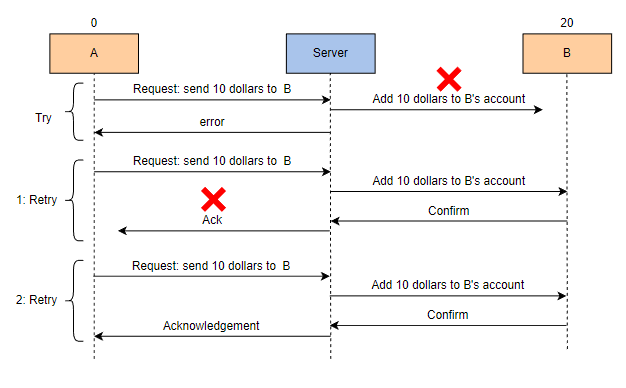
A 有 20 美元. 它请求将 10 美元发送到 B,B 的余额为 0。A 是发送者,B 是接收者。
服务器开始将 10 美元添加到 B 的账户中,但未能成功执行。
服务器向 A 发送错误消息。
A 重试事务。
服务器开始将 10 美元添加到 B 的账户中。
这次服务器能够成功执行将 10 美元添加到 B 的账户的操作,B 的余额更新。
服务器向 A 发送确认消息,但由于某些错误,未能成功。
A 再次重试事务。
服务器再次开始将 10 美元添加到 B 的账户中。
将 10 美元添加到 B 的账户的操作成功执行,B 的余额再次增加了 10 美元。
客户端已接收到确认消息,但我们得到了错误的输出。B 的账户增加了 20 美元,而不是 10 美元,A 的账户扣除了额外的 10 美元。
我们不希望在再次执行任务时更改最终结果。这在金融应用程序中转账时非常关键。
我们要求任务是幂等的。幂等任务产生相同的结果,无论我们执行多少次。以下是幂等任务的执行示例:
(幂等性:幂等性是数学和计算机科学中某些操作的特性,允许它们被多次应用而不影响结果。)
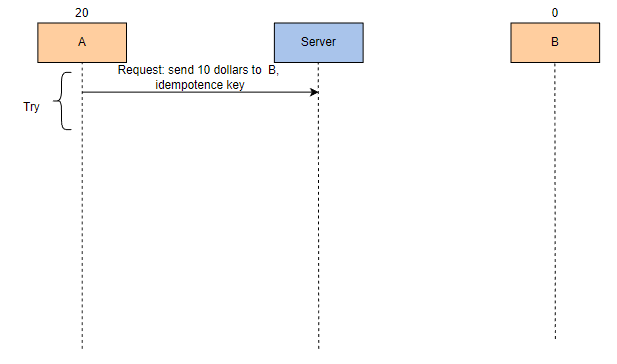
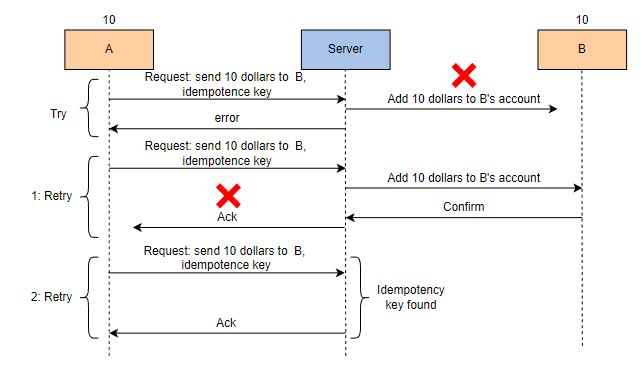
A 请求使用应用程序添加幂等键将 10 美元发送到 B。
服务器开始将 10 美元添加到 B 的账户中,但未能成功执行。
服务器向 A 发送错误消息。
A 重试事务,并附加相同的幂等键。
服务器开始将 10 美元添加到 B 的账户中。
这次服务器能够成功执行将 10 美元添加到 B 的账户的操作。
服务器向 A 发送确认消息,但由于某些错误,确认消息丢失。
A 再次重试事务,并附加相同的幂等键。
服务器发现了幂等键,因此不会再次将 10 美元添加到 B 的账户中。
客户端收到确认消息,我们得到了正确的输出。A 有 10 美元,B 也有 10 美元。
让我们将上传视频到数据库的任务变成幂等操作。
我们不希望在上传者未收到确认的情况下在数据库中重复存储视频。
幂等性确保视频不会被重复存储。开发人员通过识别视频的某个属性(例如名称)并覆盖旧视频的方式,在实现中添加了这个特性。
这样,无论有多少次上传,最终结果都是相同的。幂等性使我们能够简单地重新执行失败的任务。
相关信息
问题
如果任务负载中有一个无限循环,导致任务永远无法完成,我们该如何处理?
答案
我们需要标记并终止这些任务。为此,我们可以设置时间限制。
如果执行时间超过指定的时间限制,我们可以终止任务。
但是,区分有缺陷的任务和长时间运行的任务很具挑战性。
我们可以在应用程序级别上处理,让客户端在不同时间保存状态,以处理长时间运行的任务。
如果任务调度器终止了任务,客户端还可以从该状态恢复,前提是任务包含一个无限循环。
安排和执行不受信任的任务
在继续之前,让我们问一个问题:
什么是不受信任的任务,我们应该如何管理它们?
相关信息
不受信任的任务是指任务脚本中可能存在恶意指令的任务。这些指令可能会对其他任务的执行产生负面影响,也可能会损害操作系统或执行它们的资源。
程序具有潜在的错误,并且可能有恶意意图。在使用任务调度程序时,我们应该小心,确保一个任务不会对其他任务产生负面影响。
如果我们提供基础设施作为服务,安全性是至关重要的。这是因为租户通过在共享环境中执行恶意代码来轻松地损害彼此的任务。
执行恶意代码还可能损害我们的基础设施。因此,我们需要记住以下考虑因素:
- 使用适当的身份验证和资源授权。
- 考虑使用 Docker 或虚拟机进行代码隔离。
- 通过监视任务的资源利用率和限制(或终止)表现不良的任务之间的性能隔离。
值得思考的问题
相关信息
问题
当同一任务多次失败时会发生什么?
答案
我们可以使用死信队列机制来隔离重复失败的任务。
现在,让我们在下一课中评估我们的分布式任务调度程序的设计。