一个Blob存储的设计考虑
了解关于Blob存储不同设计方面的详细信息。
引言
即使我们在上一节中详细讨论了Blob存储系统及其主要组成部分的设计,仍有许多有趣的问题需要回答。例如,我们如何存储大的Blob?我们将它们存储在同一硬盘中,同一台机器中,还是将这些Blob分成块?应该制作多少个Blob的副本以确保可靠性和可用性?如何快速搜索和检索Blob?这些只是可能出现的一些问题。
本课程解决这些重要的设计问题。下表总结了本课程的目标。
| 部分 | 目的 |
|---|---|
| Blob元数据 | 这是为了确保Blob的高效存储和检索而维护的元数据。 |
| 分区 | 这决定了Blob如何在不同的数据节点之间进行分区。 |
| Blob索引 | 这向我们展示了如何高效地搜索Blob。 |
| 分页 | 这教我们如何设计检索有限数量的Blob的方法,以确保提高可读性和加载时间。 |
| 复制 | 这教我们如何复制Blob,并告诉我们应该维护多少份副本以提高可用性。 |
| 垃圾回收 | 这教我们如何删除Blob,而不牺牲性能。 |
| 流式传输 | 这教我们如何以分块的方式流式传输大文件,以便为用户提供互动性。 |
| 缓存 | 这向我们展示了如何提高响应时间和吞吐量。 |
在回答上述问题之前,让我们看看如何为用户创建一些抽象层,以隐藏Blob存储的内部复杂性。这些抽象层帮助我们做出与设计相关的决策。
有三个抽象层:
- 用户账户:用户通过其
account_ID在此层上唯一标识。用户上传的Blob存储在其容器中。 - 容器:每个用户都有一组容器,这些容器都通过一个
container_ID唯一标识。这些容器包含Blob。 - Blob:此层包含有关Blob的信息,这些信息通过其
blob_ID唯一标识。此层维护的关于Blob元数据的信息对于实现系统的可用性和可靠性至关重要。
我们可以基于这些层次制定路由、存储和分片决策。下表总结了这些层次。
| 级别 | 唯一标识符 | 信息 | 分片方式 | 映射 |
|---|---|---|---|---|
| 用户的Blob存储账户层次 | account_ID | container_ID值的列表 | account_ID | 账户->容器列表 |
| 容器层次 | container_ID | blob_ID值的列表 | container_ID | 容器->Blob列表 |
| Blob层次 | blob_ID | {块的列表,块信息:数据节点ID ..} | blob_ID | Blob->块的列表 |
提示
我们使用唯一ID生成器为用户帐户、容器和Blob生成唯一的ID。
除了存储实际的Blob数据之外,我们还需要维护一些元数据来管理Blob存储。让我们看看那些数据。
Blob元数据
当用户上传Blob时,它会被分成小块(块:写入和读取的最小数据单元),以便支持无法在单个连续位置、单个数据节点或与该数据节点相关联的磁盘块中存储的大文件的存储。单个Blob的块随后存储在具有足够存储空间来存储这些块的不同数据节点上。有数十亿个Blob保存在存储中。主节点必须存储有关Blob块及其存储位置的所有信息,以便在读取时检索它们。主节点为每个块分配一个ID。
有关Blob的信息包括每个块的ID以及分配给每个块的数据节点的名称。我们将Blob分成大小相等的块。为了使它们能够处理数据节点故障,我们将块复制。因此,我们还为每个块存储副本ID。我们可以访问与每个Blob相关的所有这些信息。
假设我们有一个128 MB的Blob,并将其分成两个大小为64 MB的块。该Blob的元数据如下表所示:
| 块 | 数据节点ID | 副本1 ID | 副本2 ID | 副本3 ID |
|---|---|---|---|---|
| 1 | d1b1 | r1b1 | r2b1 | r3b1 |
| 2 | d1b2 | r1b2 | r2b2 | r3b2 |
提示
为了避免复杂性,块存储中所有Blob的块大小都是固定的。块大小取决于Blob存储的性能要求。我们希望使用较大的块大小来维护主节点上的小元数据,因为较大的块大小会导致更高的磁盘延迟,从而导致较慢的性能。有趣的是,磁盘在读取和写入一定范围内的数据时的延迟几乎相同。例如,一个磁盘在写入位于4-8范围内的MB时,可以具有类似的延迟。此外,它们可以在写入9-20 MB范围内的数据时具有类似的延迟。这是由于磁盘上的连续扇区以及由其操作系统的磁盘和服务器进行的缓存造成的。
我们为每个块维护三个副本。在编写Blob时,主节点使用其自由空间管理系统标识数据和副本节点。除了处理数据节点故障之外,还使用副本节点来处理读/写请求,以便不会过载主节点。
在上面的示例中,Blob大小是块大小的倍数,因此主节点可以确定要读取每个块的字节数。
问题:如果Blob大小不是我们配置的块大小的倍数,主节点如何知道读取最后一个块的字节数?
答案:如果Blob大小不是块大小的倍数,则最后一个块将不是完整块。主节点还保留每个Blob的大小,以确定读取最后一个块的字节数。
分区数据
我们已经讨论了块存储中的不同抽象级别--帐户层,容器层和Blob层。我们存储和读取了数十亿个Blob。我们有大量数据节点来存储这些Blob。如果我们要在所有数据节点中查找包含特定Blob的数据节点,这将是一个非常缓慢的过程。相反,我们可以将数据节点分组,称每个组为分区。我们维护一个分区映射表,其中包含每个分区中所有Blob的列表。如果我们独立于它们的容器ID和帐户ID将Blob分布在不同的分区,就会遇到问题,如下图所示:
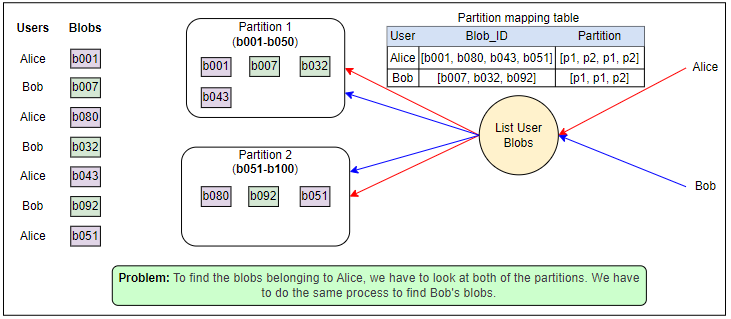
基于blob ID的分区会导致一些问题。例如,特定容器或账户下的blob可能分布在不同的分区中,这会在读取或列出与特定账户或特定容器相关联的blob时增加额外的负载。
为了解决上述问题,我们可以基于blob的完整路径对blob进行分区。这里的分区键是账户ID、容器ID和blob ID的组合。这有助于将单个用户的blob放置在同一分区服务器上,从而增强性能。
提示
分区映射由主节点维护,并且这些映射存储在分布式元数据存储中。
Blob索引
随着上传到存储中的blob数量增加,找到特定的blob变得更加困难和耗时。Blob索引解决了blob管理和查询问题。
为了填充blob索引,我们在上传blob时定义了键值标签属性。我们使用多个标签,例如容器名称、blob名称、上传日期和时间以及一些其他类别(如图像或视频blob等)。
如下图所示,blob索引引擎读取新标签,对其进行索引,并将其公开到可搜索的blob索引中。
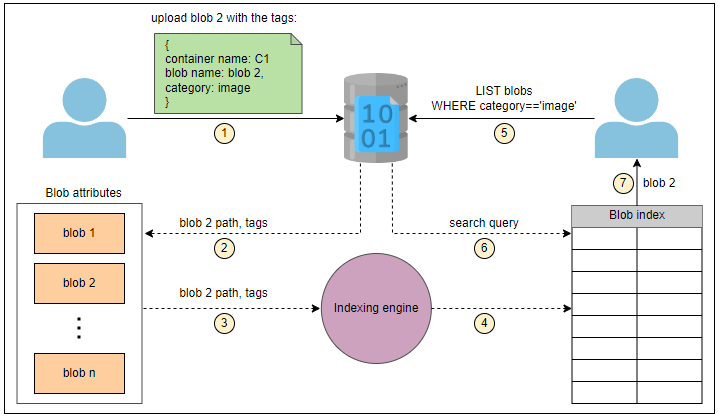
我们可以使用索引对blob进行分类和排序。让我们看看如何在分页中使用索引。
分页列表
列表是返回与用户输入的前缀相匹配的blob列表。前缀是字符或字符串,返回名称以该特定字符或字符串开头的blob。
用户可能想要列出与特定账户关联的所有blob、特定容器内存在的所有blob,或者基于前缀列出一些公共blob。问题在于这个列表可能非常长。我们不能一次性将整个列表返回给用户。因此,我们必须分批返回blob列表。
假设用户想要列出与其帐户关联的blob列表,并且与该帐户关联的总共有2000个blob。一次性搜索、返回和加载太多的blob会影响性能。这就是分页变得重要的地方。我们可以返回前五个结果并给用户一个“下一页”按钮。每次点击“下一页”按钮,它都会返回下面的五个结果。这称为分页。
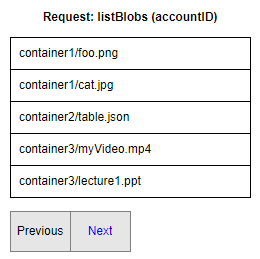
应用程序所有者根据以下因素设置要返回的结果数量:
- 他们认为用户等待查询响应的时间有多长。
- 在该时间内他们能够返回多少结果。我们显示了每页返回五个结果,这是一个非常小的数字。我们仅使用此数字进行可视化目的。
问题:我们如何决定首先返回哪五个blob作为总共2000个blob中的第一批返回结果?
答案:在此,我们利用索引来对blob进行排序和分类。我们应该在存储blob时先进行这些操作。否则,在返回列表时排序会变得很困难。可能会有数百万或数十亿的blob,当收到列表请求时,我们无法快速对其进行排序。思考题
对于分页,我们需要一个续订标记作为接下来返回的列表部分的起点。续订标记是一个包含在查询响应中的字符串标记,如果查询结果的总数超过我们一次最多可以返回的结果数,则会包含该标记。因此,它充当指针,允许重新查询从上一次停止的地方继续。
复制
复制在两个层面上进行以支持可用性和强一致性。为了保持数据强一致,我们在写操作后立即在用于提供读请求的节点之间同步复制数据。为了实现可用性,我们可以在写操作后将数据复制到不同的区域或数据中心。在数据还没有被复制到那里之前,我们不会从其他数据中心或区域提供读请求。这是复制的两个层面:
- 在存储集群内部的同步复制。
- 跨数据中心和区域的异步复制。
存储集群内部的同步复制
一个存储集群由N个存储节点架构组成,每个节点配置为带有冗余网络和电源的故障域。
我们确保每个写入存储集群的数据在该存储集群内部保持持久。主节点在不同故障域的节点上维护足够的数据副本,以确保在发生磁盘、节点或机架故障时仍能保证集群内部的数据持久性。
提示
这种集群内部的复制是客户端写请求的关键路径上完成的。
一旦一个写操作在存储集群内部同步复制完成,便可以将成功的结果返回给客户端。这允许进行快速写,因为:
- 我们在存储集群内部复制数据,所有节点都在附近,因此可以减少延迟。
- 我们使用内联数据复制,使用冗余的网络路径并行地将数据复制到所有副本中。
这种复制技术有助于在存储集群内部维护数据的一致性和可用性。
跨数据中心和区域的异步复制
Blob存储的数据中心分布在不同的区域,例如亚太地区、欧洲、美国东部等。在每个区域中,我们有超过一个位于不同位置的数据中心,所以如果一个数据中心关闭,我们有其他数据中心在同一区域内接替并为用户请求提供服务。每个区域内至少有三个数据中心,每个中心之间相隔数英里,以保护免受局部事件如火灾、洪水等的影响。
一个Blob的副本数量称为复制因子。大多数情况下,复制因子为三就足够了。
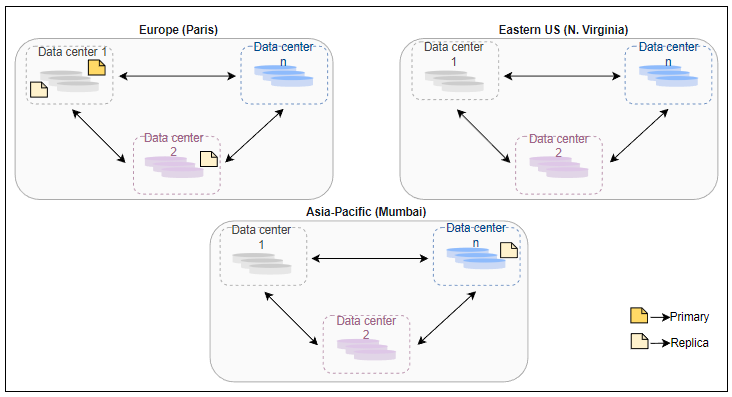
我们将一个Blob的四个副本。其中一个是在主区域的数据中心内的本地副本,以保护服务器机架和驱动器故障。对于这个Blob的第二个副本,我们将它放在同一区域内的另一个数据中心内,以防止数据中心发生火灾或洪水。第三个副本放在不同区域的数据中心以防止区域性灾害。
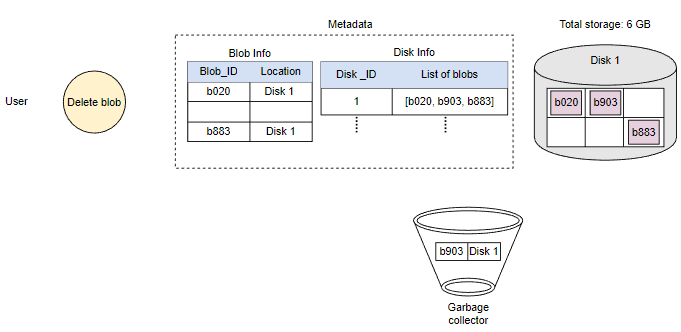
删除Blob时的垃圾回收
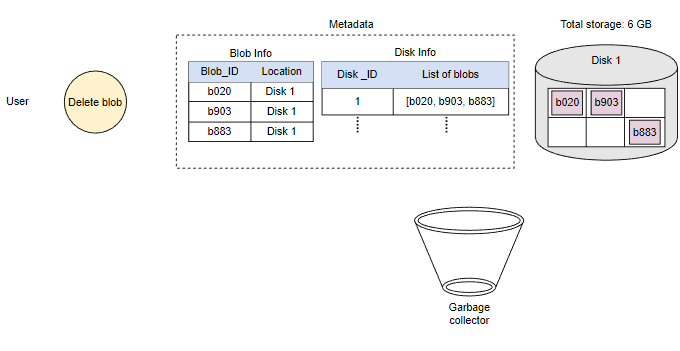
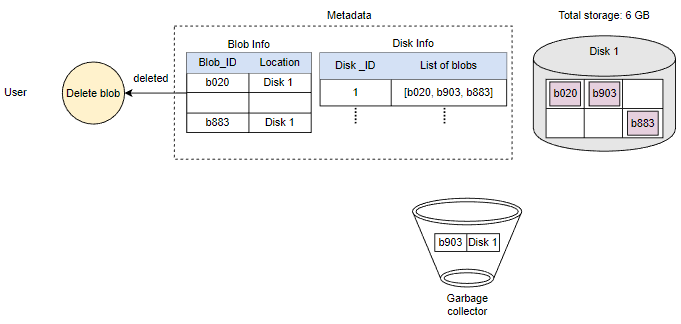
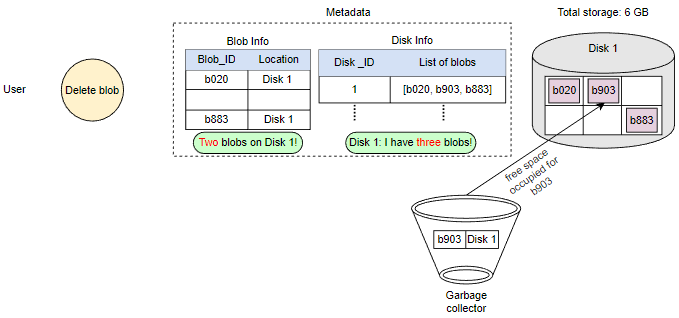
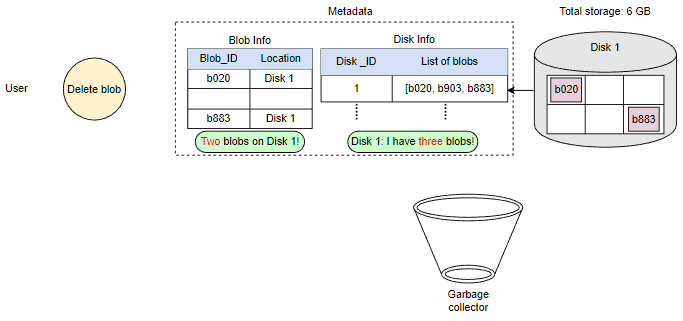
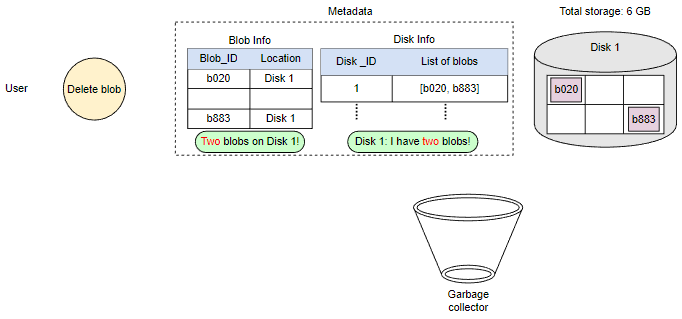
由于Blob块放置在多个数据节点上,从许多不同节点中删除需要时间,持有客户端直到完成不是一个可行的选项。由于实时延迟优化,我们实际上不会在删除请求中从Blob存储中删除Blob。相反,我们只是在元数据中将Blob标记为“DELETED”,使其对用户无法访问。
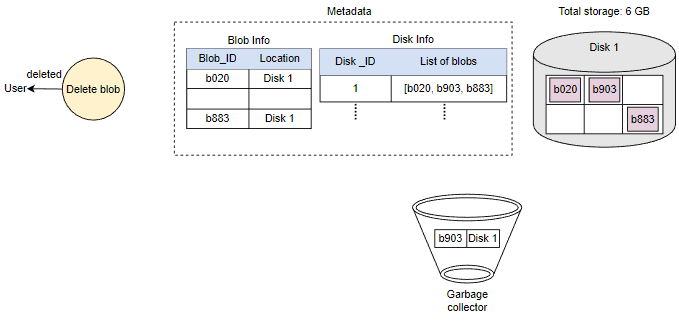
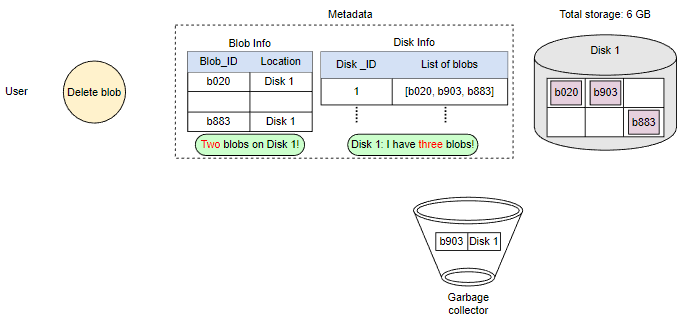
在响应用户的删除请求后,稍后删除Blob。将Blob标记为已删除,但暂时不实际删除它,会导致内部元数据不一致,意味着应该空闲的存储空间仍在被使用。这些元数据不一致对用户没有影响。例如,对于在元数据中标记为已删除的Blob,我们仍然有该Blob块的条目。数据节点仍然保留着该Blob块。因此,我们有一个名为垃圾回收器的服务,以后会清理元数据不一致。删除Blob会导致与该Blob相关的块被释放。但是,用户删除Blob请求和Blob存储中相应的空闲空间增加之间可能存在显着的时间延迟。我们可以忍受这种显着的时间延迟,因为作为回报,我们为用户的删除Blob请求提供了实时快速响应的好处。
整个删除过程如下图所示:
流式传输文件
要流式传输文件,我们需要定义每次允许读取多少字节。假设我们每次读取X个字节。第一次从第0个字节(0到X−1)开始读取第一个X个字节,下一次从下一个X个字节(X到2X−1)开始读取。
问题:我们如何知道我们首先读取了哪些字节,以及下一个要读取哪些字节?
答案:我们可以使用一个**偏移值**来跟踪我们需要从哪个字节再次开始阅读。
缓存Blob存储
缓存可以在多个级别进行。以下是一些示例:
在首次读取Blob块的元数据时,在客户端端缓存Blob块的元数据。客户端可以直接访问数据节点,而无需再次与主节点通信以读取相同的Blob块。
在前端服务器上,我们缓存分区映射并使用它确定要将每个请求转发到哪个分区服务器。
在主节点上缓存经常访问的块,这有助于我们高效地流式传输大型对象。它还可以减少磁盘I/O。
提示
Blob存储的缓存通常使用CDN。Azure Blob存储服务将公开访问的Blob缓存在Azure内容传递网络中,直到该Blob的TTL(生存时间)过期。源服务器定义TTL,CDN根据来自源服务器的HTTP响应中的Cache-Control头确定TTL。
我们已经涵盖了在设计Blob存储时应考虑的设计因素。现在,我们将评估我们所设计的内容。