一个速率限制器的设计
学习如何设计速率限制器,以帮助衡量和限制系统中使用的资源。
高级设计
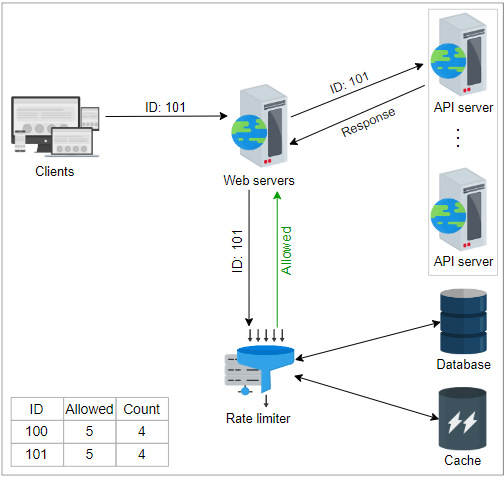
速率限制器可以部署为一个单独的服务,将与Web服务器进行交互,如下图所示。当接收到请求时,速率限制器建议是否将请求转发到服务器。速率限制器由应遵循每个传入请求的规则组成。这些规则定义了每个操作的节流限制。让我们看看来自 Lyft 的速率限制规则:
yaml
domain: messaging
descriptors:
- key: message_type
value: marketing
rate_limit:
unit: day
requests_per_unit: 5
在上述速率限制规则中,unit 被设置为 day,requests_per_unit 被设置为 5。这些参数定义了系统每天可以允许五个营销邮件。
详细设计
上述高级设计不能回答以下问题:
- 规则存储在哪里?
- 如何处理受速率限制的请求?
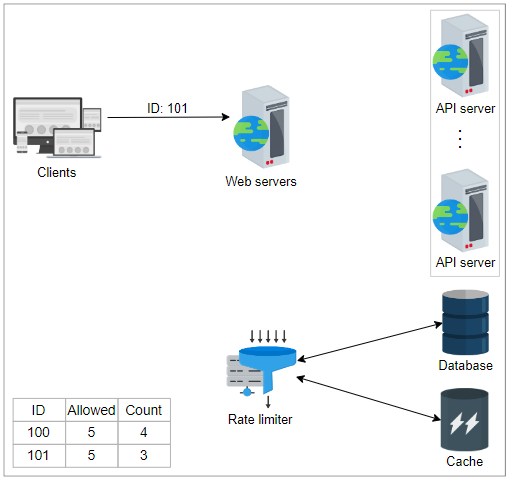
在本节中,我们首先将高级架构扩展为其他几个必要的组件。我们还将详细解释每个组件,如下图所示。
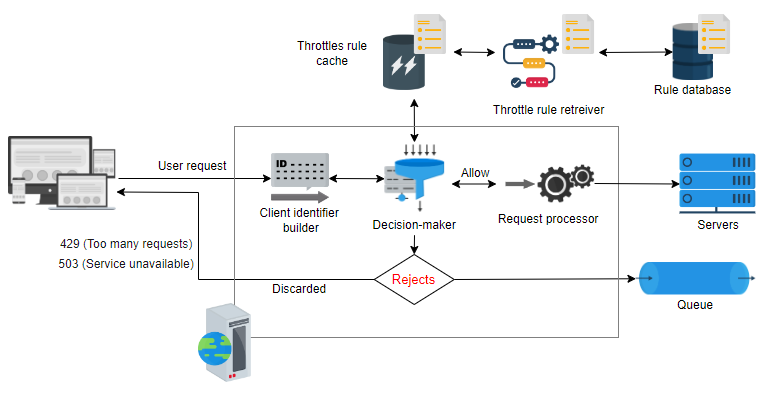
让我们讨论速率限制器详细设计中存在的每个组件。
规则数据库:这是由服务所有者定义的规则组成的数据库。每个规则指定了每个客户端在某个时间段内允许的请求数量。
规则检索器:这是定期检查数据库中规则修改的后台处理过程。如果对现有规则进行任何修改,则规则缓存将进行更新。
节流规则缓存:缓存包含从规则数据库检索的规则。相对于持久存储,缓存可以更快地为速率限制器请求提供服务。因此,当速率限制器收到针对某个 ID(键)的请求时,它会检查缓存中的规则。
决策者:此组件负责根据缓存中的规则做出决定。该组件基于下一课中讨论的一种速率限制算法工作。
客户端标识符生成器:此组件为从客户端接收的请求生成唯一ID。这可以是远程IP地址、登录ID或几个其他属性的组合,因此无法在这里使用序列号。该ID被视为将用户数据存储在键值数据库中的键。因此,该键将传递给决策者以进行进一步的服务决策。
如果超过预定义的限制,API将返回HTTP响应代码429 Too Many Requests,并应用以下策略之一来处理请求:
- 抛弃该请求并向客户端返回具有特定响应的信息,例如“请求太多”或“服务不可用”。
- 如果系统负载过高,一些请求受到速率限制,则可以将这些请求保留在队列中以便后处理。
请求处理
当收到请求时,客户端标识符构建器会识别请求并将其转发给决策者。决策者确定请求所需的服务,然后根据服务所有者提供的规则,检查缓存是否超过允许的请求数量。如果请求未超过计数限制,则将其转发给请求处理器,该处理器负责为请求提供服务。
决策者根据限流算法做出决策。限流可以是硬限流、软限流或弹性限流。根据软限流或弹性限流,请求可以超过定义的限制。这些请求要么被服务,要么被保留在队列中,稍后在资源可用时再提供服务。同样,如果使用了硬限流,则请求将被拒绝,并向客户端发送响应错误。
警告
问题: 如果速率限制器无法执行调整任务,则是否应接受或拒绝请求?
答案: 在这种情况下,建议的系统应遵守非功能性要求,包括可用性和容错性。因此,在失败的情况下,速率限制器将无法执行调整。但是,默认决策将是不调整任何请求。原因是我们将在不同服务级别上拥有许多速率限制器。即使没有其他速率限制器,负载均衡器也会在一定级别上执行此任务,如前面所述。
竞态条件
在高并发请求模式下,存在竞争条件的可能性。当采用“get-then-set”方法时,此情况发生,其中检索当前计数器、将其增加,然后将其推回到数据库。在遵循此方法时,可以通过其他请求来留下增加的计数器无效。这使得客户端可以发送非常高速率的请求,绕过速率限制控制。为了避免此问题,可以使用锁定机制。其中一个进程可以一次更新一次计数器,而其他进程则等待锁定被释放。由于这种方法可能导致潜在的瓶颈,因此它会显着降低性能并且不能很好地扩展。 可以使用另一种方法,即“set-then-get”方法,在非常高效的方式下增加值,从而避免锁定方法。如果存在最少争用,则此方法有效。但是,可以使用其他方法将允许的配额分成多个位置并将其分配给它们,或者使用分片计数器来扩展方法。
相关信息
我们可以在高度并发的流量下使用分片计数器来进行速率限制。通过增加片数,我们减少了写入争用。由于我们必须从所有分片收集计数器,因此我们的读取可能会变慢。
速率限制器不应在客户端的关键路径上
假设有数百万个请求发送到前端服务器的实时场景。每个请求都会检索、更新并将计数推回到相应的缓存中。完成所有这些操作后,请求被转发以进行服务。如果请求数量很大,这种方法可能会导致延迟。为避免在客户端的关键路径上进行大量计算,我们应该将工作分成离线和在线两个部分。
最初,当收到客户端请求时,系统只会检查相应的计数。如果它小于最大限制,则系统会允许客户端请求。在第二阶段,系统会离线更新相应的计数和缓存。对于一些请求,这对性能没有任何影响,但对于数百万个请求,这种方法显著提高了性能。
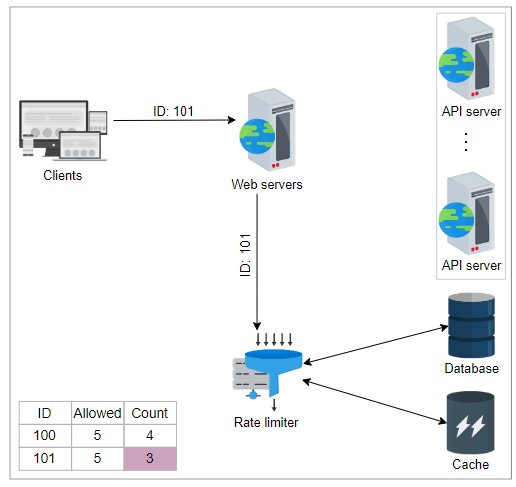
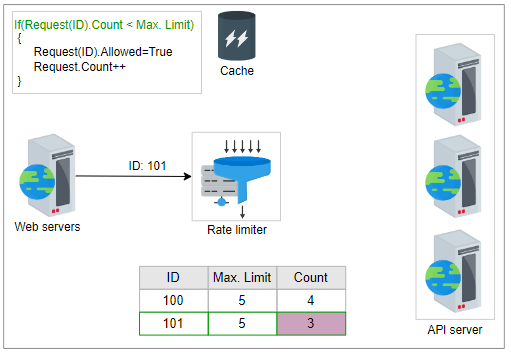
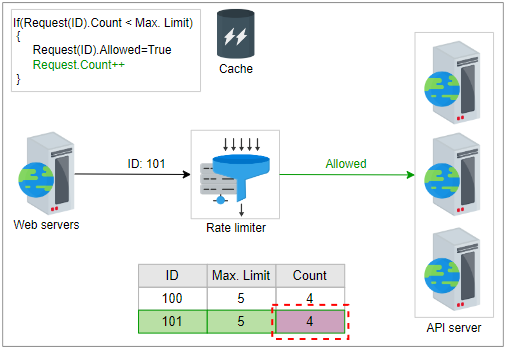
让我们通过一个例子来理解在线和离线更新方法。在以下一组插图中,当收到请求时,它的ID将被转发给速率限制器,后者将检查条件 if(request(ID).Count <= Max. Limit,通过从缓存中检索数据来实现。为简单起见,假设其中一个请求的ID为101,即request(ID) = 101。下表显示了每个客户端发出的请求数量以及每个单位时间内客户端可以发出的最大请求数量。
| Request ID | Maximum Limit | Count |
|---|---|---|
| 100 | 5 | 4 |
| 101 | 5 | 3 |
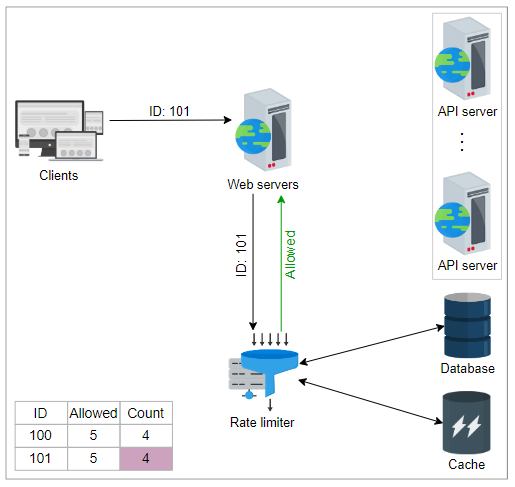
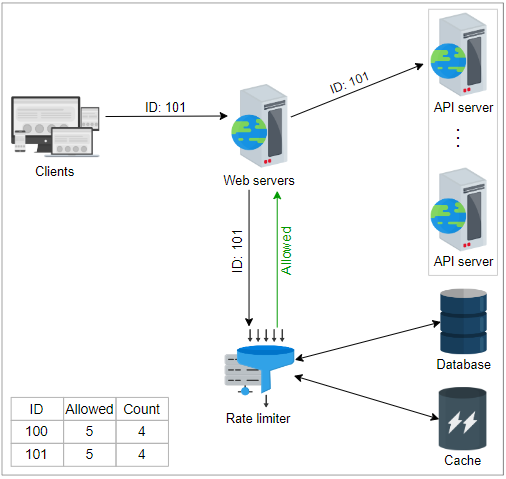
如果条件为真,则速率限制器将首先向前端服务器回复“允许”。相应的“计数”和其他相关信息在下一步中离线更新。速率限制器在缓存中写回更新的数据。通过这种方法减少了延迟,避免了到来的请求可能引起的争用。
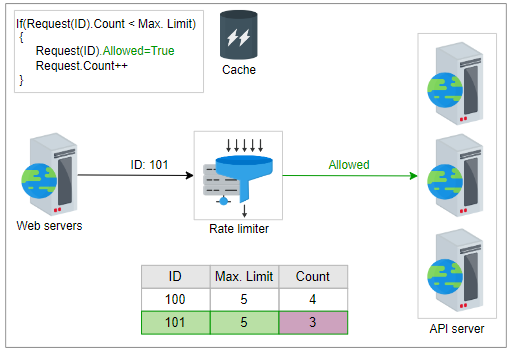
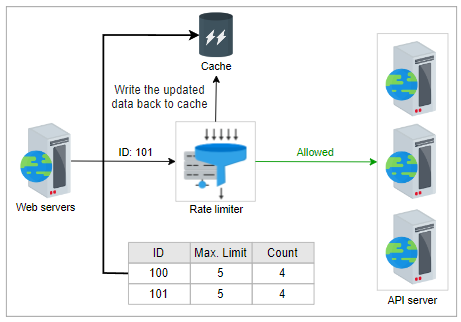
相关信息
我们已经看到了TCP网络协议中的一种速率限制形式,其中接收者可以通过广告窗口的大小(接收者愿意接收的未完成数据)来限制发送者。发送者发送拥塞窗口或广告窗口的最小值。许多网络流量整形器使用类似的机制为不同的网络流提供优先处理。
结论
在本课程中,我们讨论了分布式系统中速率限制器的设计。让我们分析前一课中承诺的非功能性要求。
- 可用性: 如果速率限制器失败,多个速率限制器将可用于处理传入的请求。因此,消除了单个故障点。
- 低延迟: 我们的系统从缓存而不是数据库中检索和更新每个传入请求的数据。首先,如果传入请求未超过速率限制,则将其转发,然后更新缓存和数据库。
- 可扩展性: 可以根据定义的限制内传入请求的数量增加或减少速率限制器的数量。
现在,我们的系统在上述讨论的情况下提供高可用性,低延迟和可扩展性。