设计分布式消息队列的考虑因素
了解影响消息队列设计的因素。
在设计分布式消息队列之前,让我们讨论一些可能会对设计产生重大影响的主要因素。这些因素包括消息的顺序,排序对性能的影响以及对队列的并发访问的管理。我们在下面详细讨论每个因素。
消息排序
消息队列用于接收来自生产者的消息。这些消息按照消费者自己的节奏被消费。有些操作非常关键,因为它们需要严格按照队列中的消息执行任务的顺序。例如,在使用聊天应用程序与朋友聊天时,消息应该按顺序传递;否则,这种通信可能会令人困惑。同样,来自不同用户的用户收到的电子邮件可能不需要严格排序。因此,在某些情况下,队列中传入消息的严格顺序是必要的,而许多用例可以容忍一些重新排序。
让我们讨论队列中消息排序的以下两类:
- 最佳尝试排序
- 严格排序
在队列中,消息的顺序与接收到的消息隐式关联。一旦消息放入队列中,在消耗和处理这些消息时会遵循相同的顺序。
对于并发的生产者将消息放在同一个队列中,除非生产者提供顺序信息(例如时间戳或序列号),否则顺序未被明确定义。如果没有任何排序信息,队列将以任何顺序将消息放在服务中到达的队列中。
对于从同一队列中提取消息的并发消费者,排序可能会变成一个复杂的问题。虽然队列可以按照它们进入队列的顺序依次交出消息,但是几乎同时处理两个消息的两个消费者可能需要一个特定于应用程序的排序机制。当队列从队列中提取消息时,队列可能会通过标记消息的排序信息,序列号或时间戳来提供帮助。
最优排序
使用最优排序方法,系统会按照收到消息的顺序将消息放入指定的队列中。
例如,如下图所示,生产者按照示例中显示的顺序发送四条消息A、B、C和D。由于网络拥塞或其他问题,消息B在消息D之后接收。因此,在接收端的消息顺序为A、C、D和B。因此,在这种方法中,消息将按照它们接收到的顺序而不是在客户端上生产它们的顺序将被放入队列中。
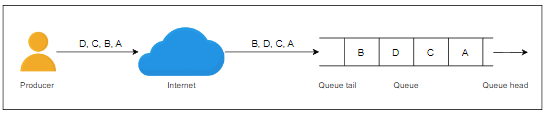
严格排序
严格排序技术更严格地保存消息的顺序。通过这种方法,消息按它们被产生的顺序放在队列中。
在正确的顺序将消息放入队列之前,有必要有一个机制来标识客户端上生产消息的顺序。通常,当产生消息时,使用唯一标识符或时间戳来标记一条消息。
警告
问题
谁将负责提供顺序号?
答案
系统提供基本库或API向客户端提供为消息生成序列号的方法。
可以使用以下三种方法之一来对传入消息进行排序:
- 单调递增的数字: 一种对传入消息进行排序的方法是在服务器端为消息分配单调递增的数字。当第一条消息到达时,系统会为其分配一个数字,例如1。然后为第二条消息分配数字2,以此类推。但是,这种方法存在潜在的缺点。首先,当接收到一连串请求时,它会影响系统的性能,因为系统必须按照特定的顺序为消息分配一个ID,而其他消息则需要等待它们的轮流。其次,它仍然无法解决当在客户端先生成的消息之前接收到消息时所引发的问题。因此,它无法保证会为在客户端生成的消息生成正确的顺序。
- 服务器端基于因果关系的排序: 鉴于使用单调递增的数字存在的缺点,可用于时间戳和排序传入消息的另一种方法是基于因果关系的排序。在这种方法中,根据在客户端生成的时间戳对消息进行排序,并相应地将它们放入队列中。这种方法的主要缺点是对于多个客户会话,服务不能确定以壁钟时间为标准的顺序。
- 使用基于同步时钟的时间戳: 为了解决上述两种方法可能出现的问题,我们可以使用基于同步时钟的适当方法为消息分配时间戳。在这种方法中,通过同步时钟为每条消息提供的时间戳(ID)是唯一的,并且按照消息的正确生成顺序。我们可以将一个唯一的进程标识符与时间戳进行标记,以使整个消息标识符唯一,并解决两个并发会话同时请求时间戳的情况。此外,使用这种方法,服务器可以根据时间戳轻松识别延迟的消息,并等待延迟的消息。正如我们在建立块中描述的
排序器中所讨论的,我们可以获取既充当序列号又充当全局同步壁钟时间戳的序列号。使用这种方法,我们的服务可以在客户会话之间全局排序消息。
总之,从上述三种方法中提供唯一ID或时间戳的最合适机制是使用同步时钟。
排序
一旦消息在服务器端接收,我们需要根据它们的时间戳对它们进行排序。因此,我们使用适当的在线排序算法来完成此任务。
警告
问题:
假设由于网络延迟,先前发送的消息到达时间较晚。在这种情况下,应该采取什么样的适当方法来处理?
回答:
在这种情况下,简单的解决方案是重新排序队列。这会出现两种情况。第一种情况,重新排序将消息放在正确的顺序中。第二种情况,我们已经将较新的消息分发给消费者。
如果在我们已经分发了较新消息的情况下出现了旧消息,则将其放在特殊队列中,由客户端处理该情况。如果是最佳努力排序队列,则可以将这样的消息放在队列的头部。
对性能的影响
首先,队列被设计用于先进先出(FIFO)操作;先进先出操作意味着进入队列的第一个消息总是最先被处理。然而,在分布式系统中很难保持这种严格的顺序。因为消息A在消息B之前产生,并不能确定消息A在消息B之前被消费。使用单调递增的消息标识符或带因果关系的标识符可在将消息放入队列的同时提高吞吐量。虽然在线排序需要一些时间才能使消息准备好进行提取,但以此来提供严格的顺序是值得的。为了尽量减少在线排序引起的延迟,我们采用时间窗口方法。
同样,在接收端要想实现严格的排序,我们需要对所有请求进行串行化,以逐个输出消息。如果不需要严格的排序,则在接收端可以获得更好的吞吐量和更低的延迟。
由于上述原因,许多分布式消息队列解决方案要么不能保证严格的顺序,要么在吞吐量方面存在限制。正如我们之前所看到的,队列必须执行许多额外的验证和协调操作以维护顺序。
管理并发性
并发队列访问需要适当的管理。并发可以发生在以下阶段:
- 当多个消息同时到达时。
- 当多个消费者同时请求一条消息时。
第一种解决方案是使用锁定机制。当进程或线程请求消息时,应获取锁以从队列中放置或消费消息。然而,正如之前讨论的,这种方法有几个缺点。它既不可扩展也不高效。
另一种解决方案是在队列的两端使用系统缓冲区对请求进行序列化,以便将传入的消息按顺序放置,并使消费进程也按其到达顺序接收消息。通过序列化请求,我们的意思是,来到服务器的请求(无论是放置数据还是提取数据),都将由操作系统排队,并且一个单独的应用程序线程将它们放入队列中(我们可以假设两种请求,放置和提取,都来到了同一个端口),而不需要任何锁定。这将是一种可能的无锁解决方案,提供高吞吐量。这是一种更可行的解决方案,因为它可以帮助我们避免竞争条件的发生。
应用程序可以使用具有专用生产者和消费者的多个队列,以使每个队列的排序成本保持在可控范围内,尽管这将以更复杂的应用程序逻辑为代价。
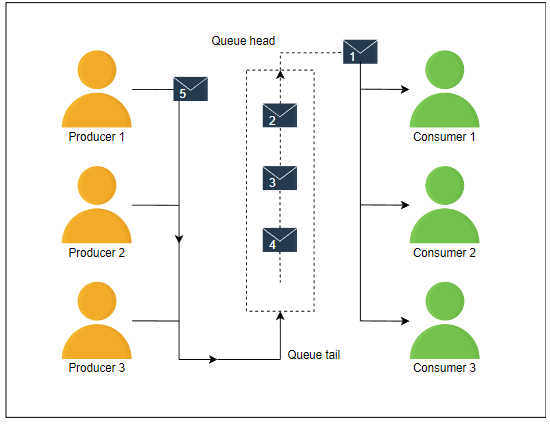
在本课程中,我们讨论了消息队列设计过程中的一些关键考虑因素和挑战,并回答了以下问题:
为什么消息的顺序很重要,我们如何强制执行顺序?
顺序如何影响性能?我们如何在访问队列时处理并发?
现在,我们准备开始设计分布式消息队列。