介绍分布式监控
了解为什么在分布式系统中进行监控是至关重要的。
监控的需求
让我们了解一下单个服务的故障会如何影响相关系统的平稳运行。为了避免级联故障,监控可以通过提前发出警报或引导我们找到故障的根本原因来发挥至关重要的作用。
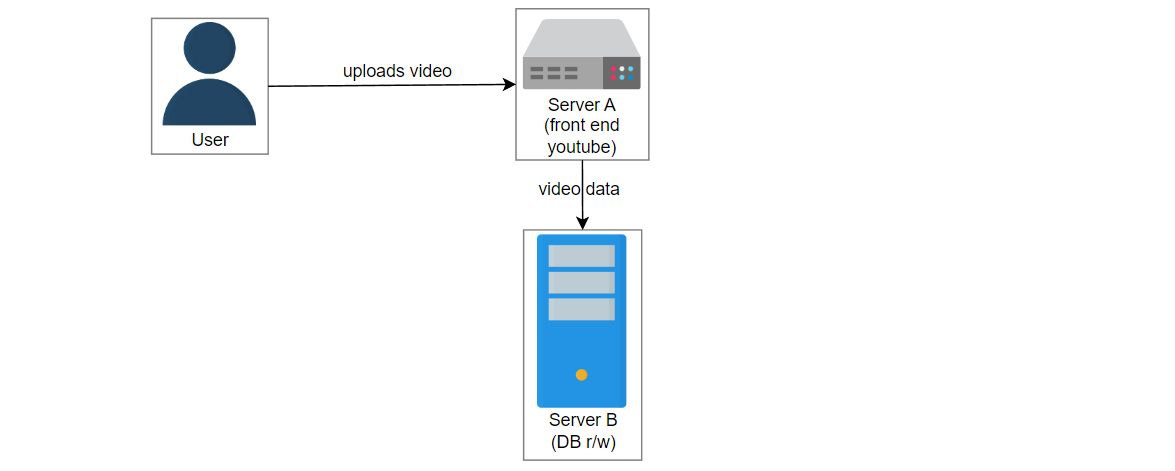
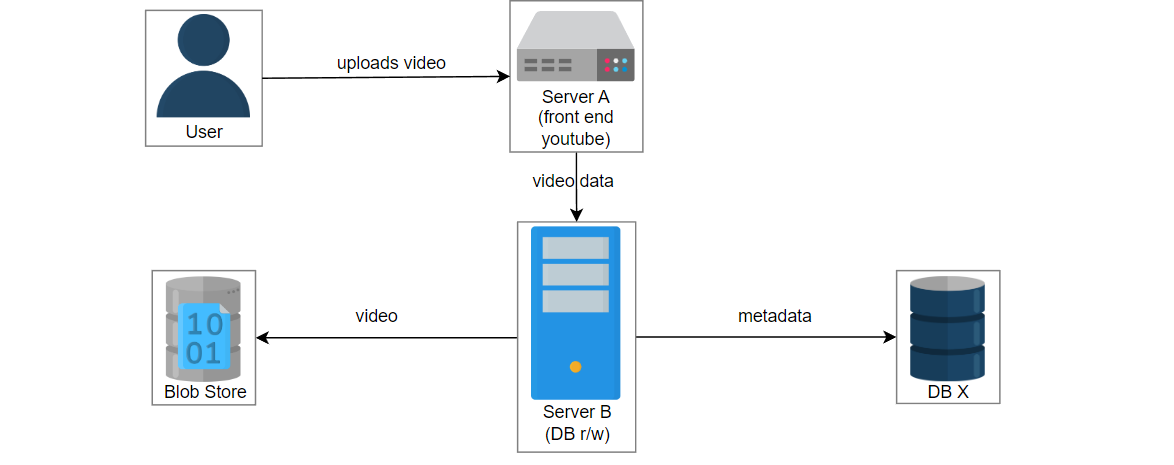
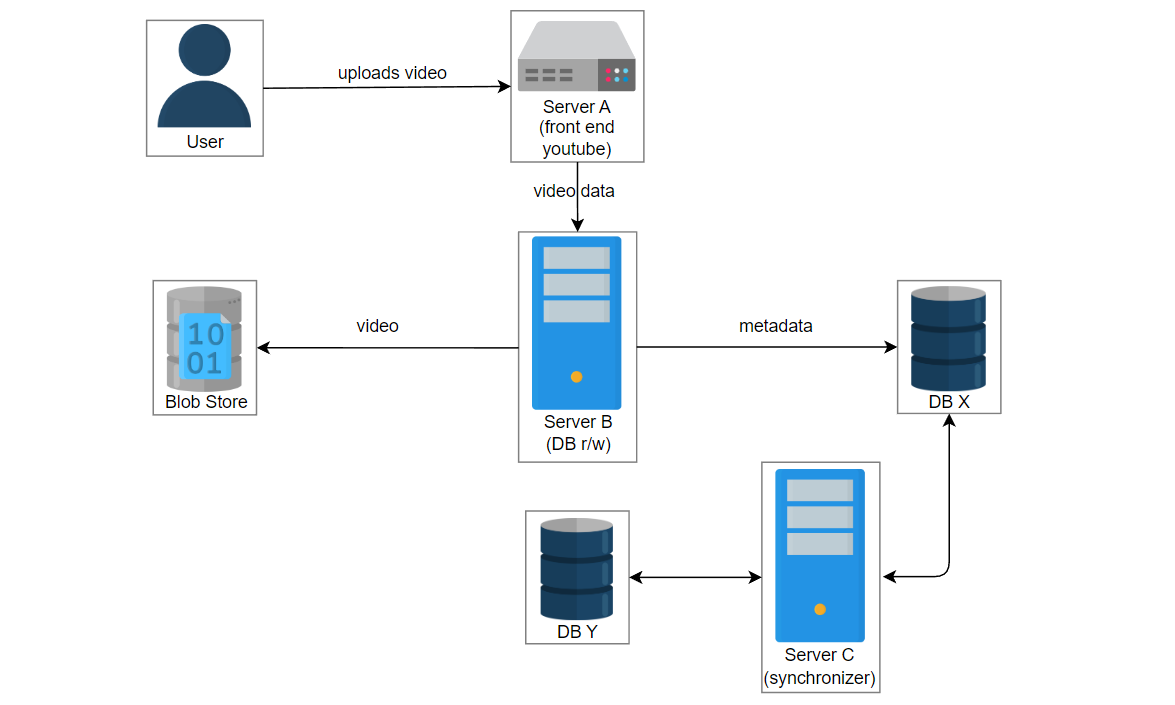
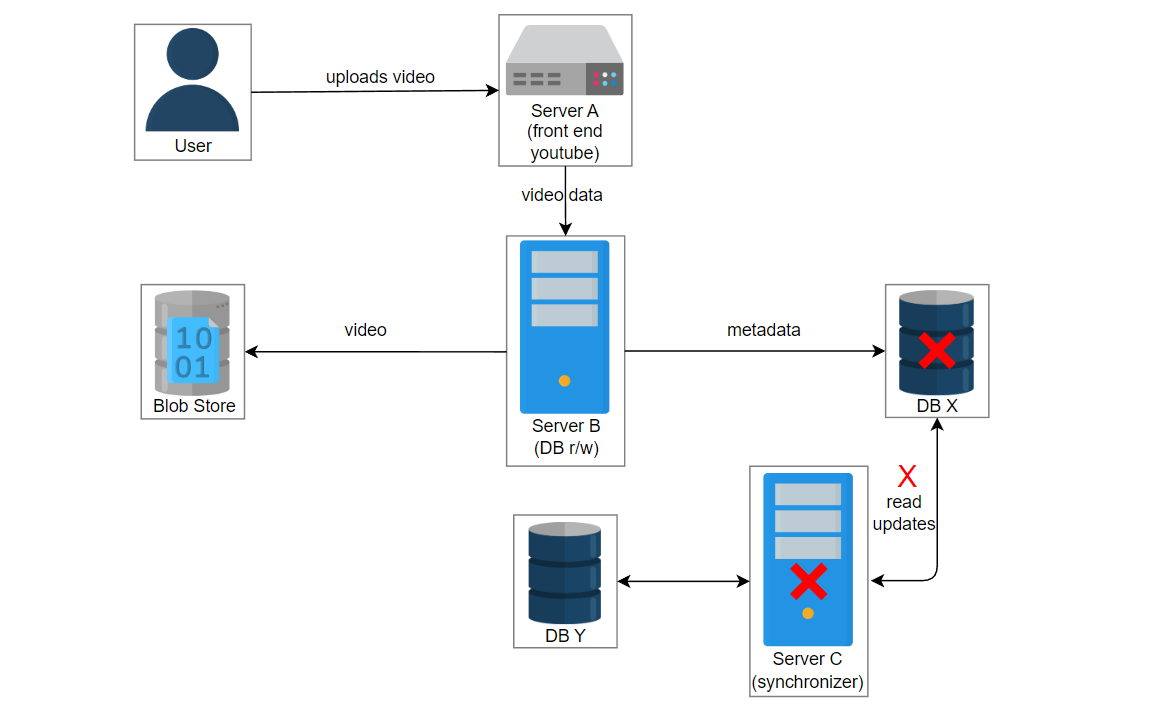
让我们考虑这样一个场景:用户上传一个名为“intro-to-system-design”的视频到YouTube。位于服务器A上的UI服务获取视频信息并将数据传递给位于服务器B上的服务2。服务2在数据库中创建一个条目并将视频存储在blob存储中。服务器C中的另一个服务3管理数据库X和Y的复制和同步。
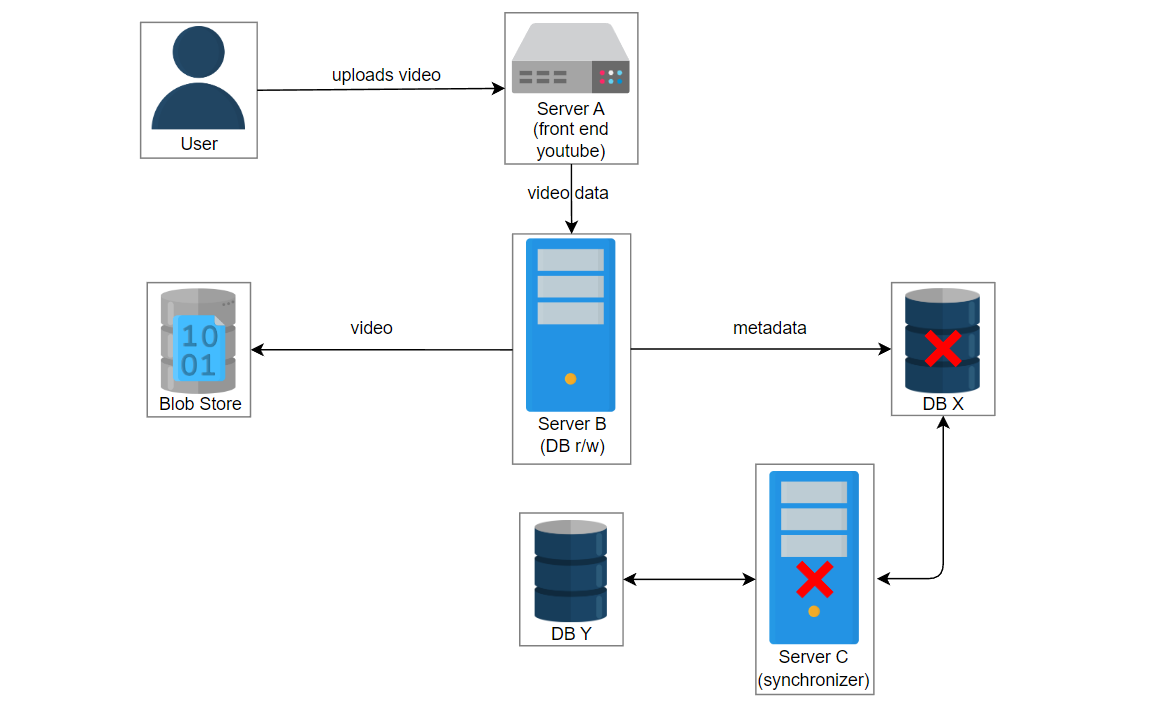
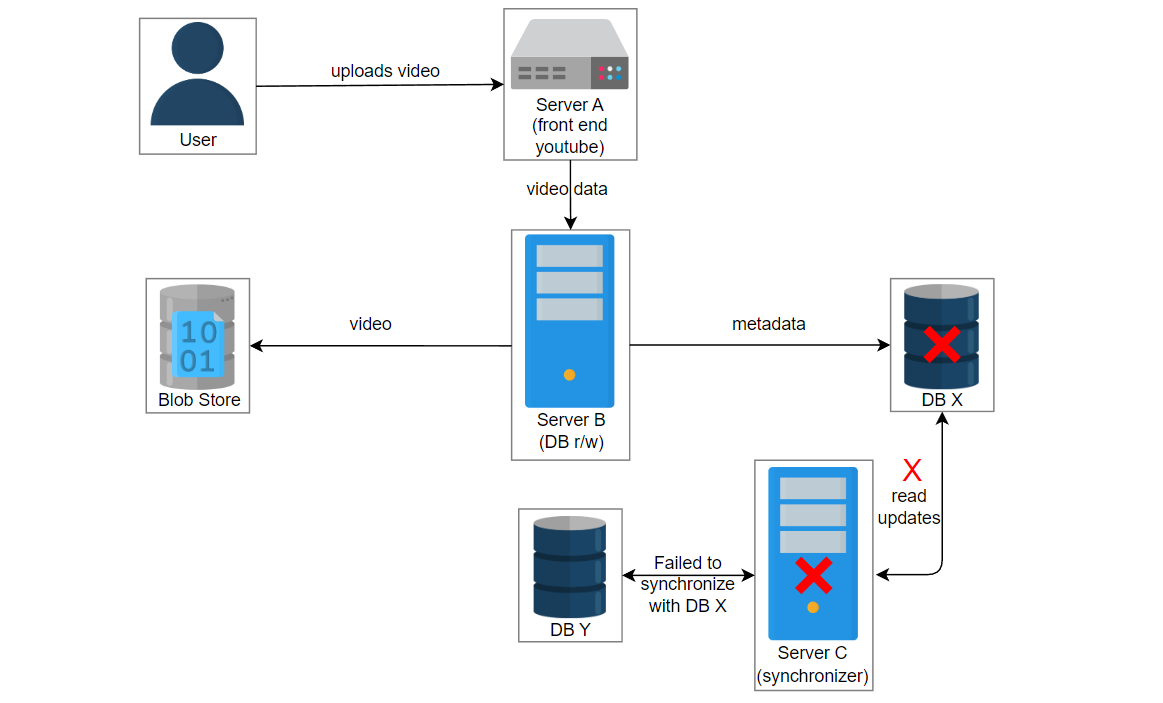
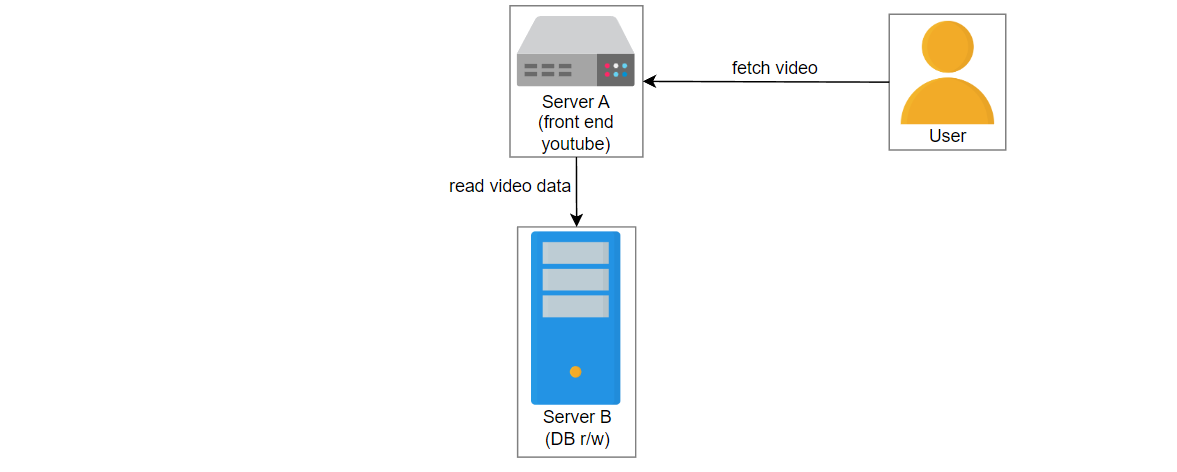
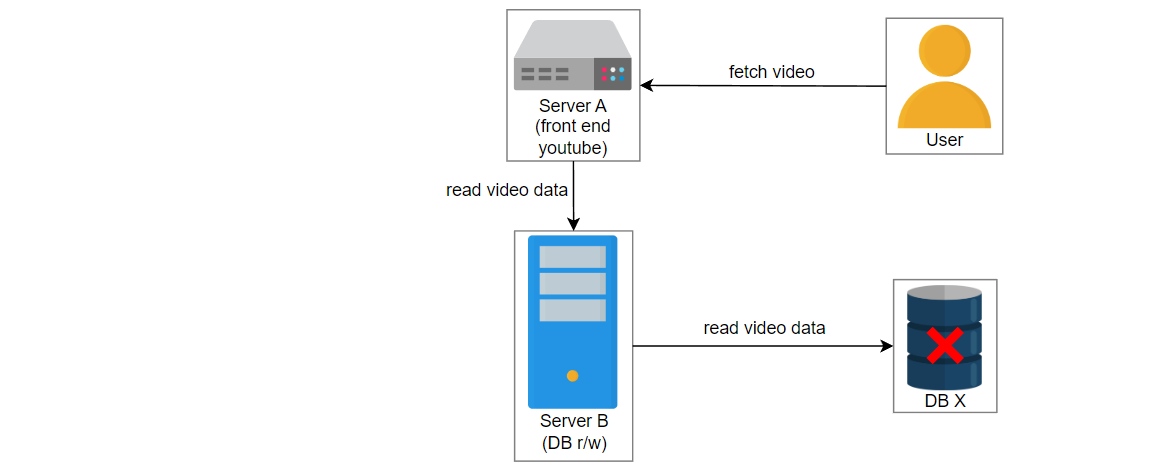
在这种情况下,由于某些错误,服务3失败了,并且服务2在数据库X中创建了一个条目。数据库X崩溃,获取视频的请求被路由到数据库Y。用户想播放 “intro-to-system-design” 视频,但是将显示“视频未找到”的错误。


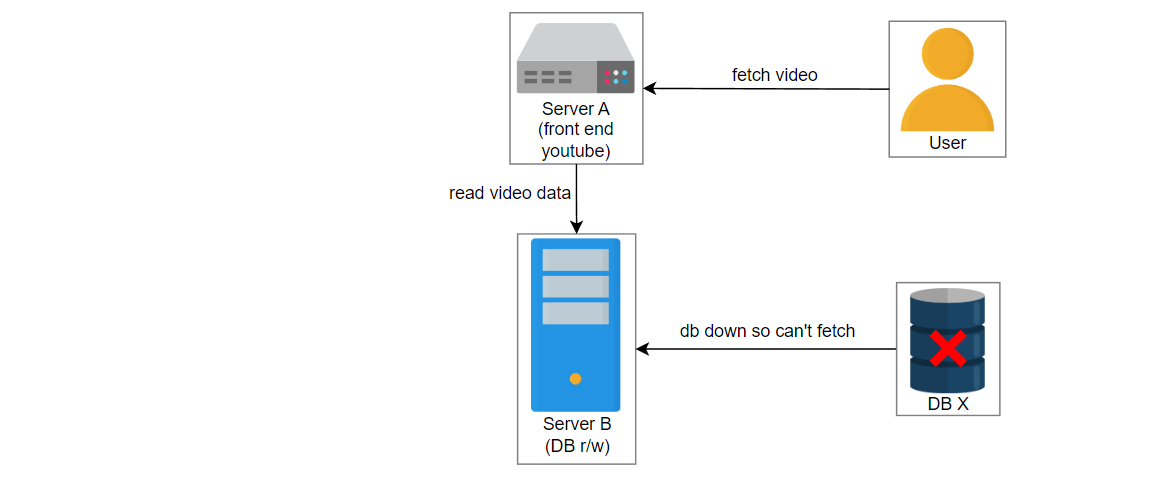
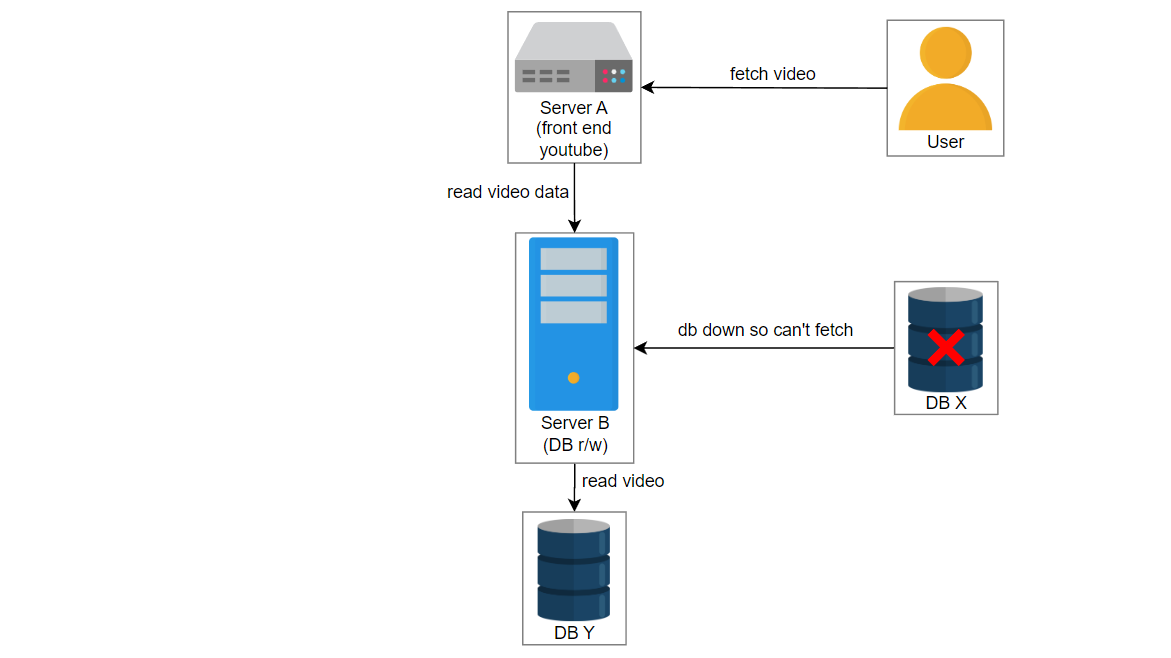
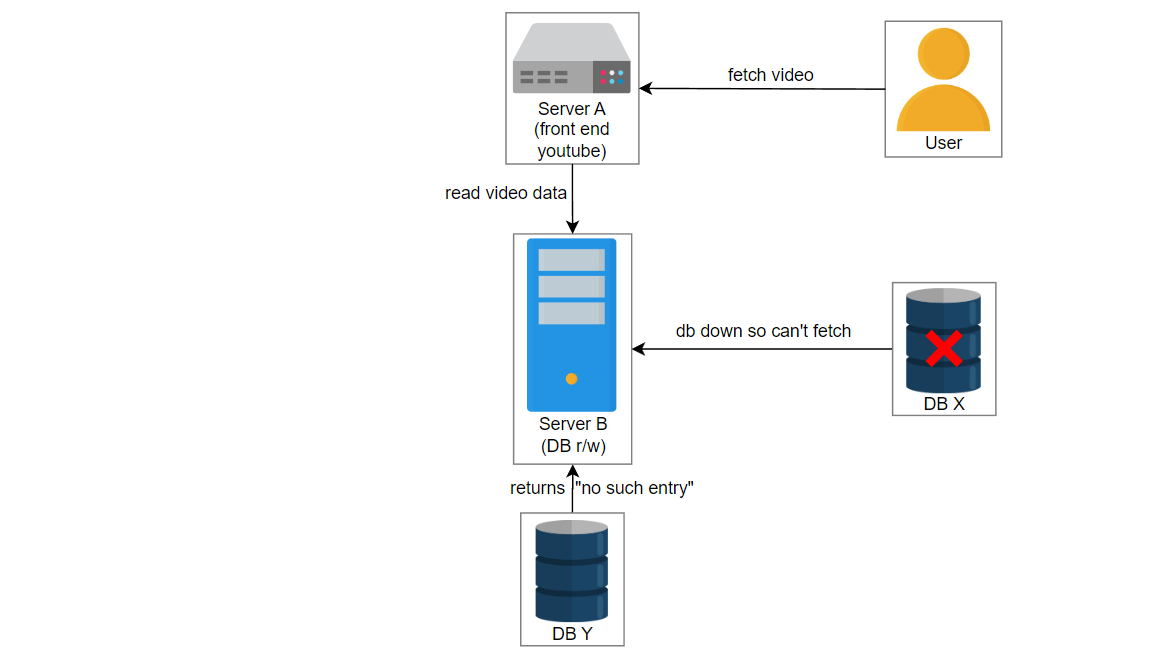
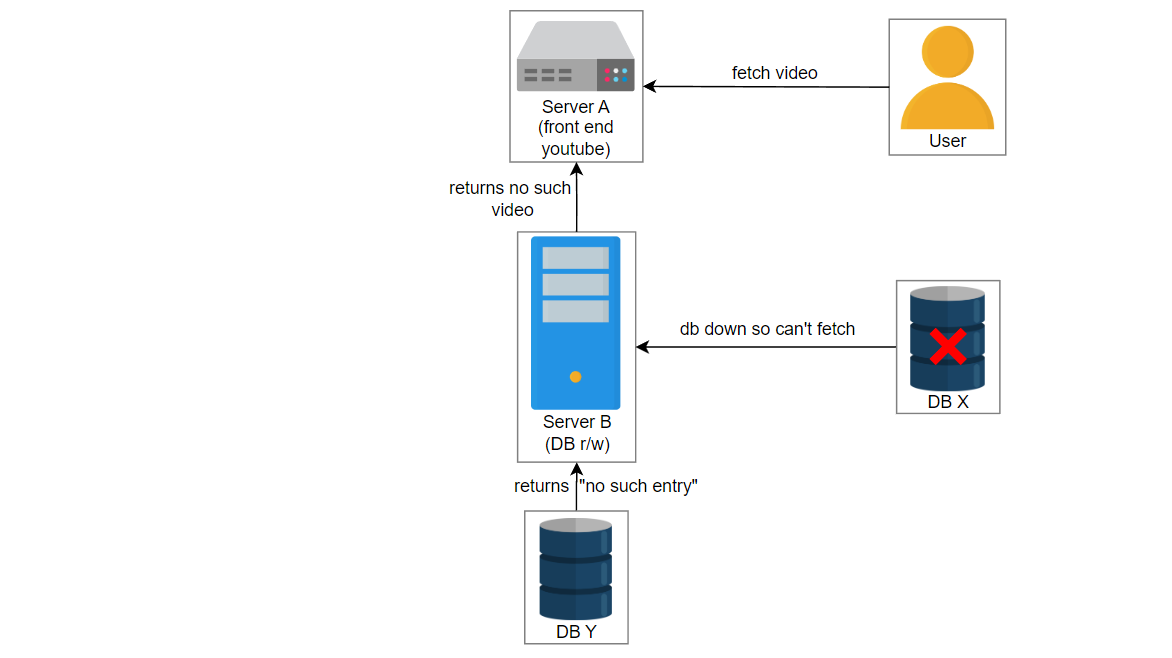
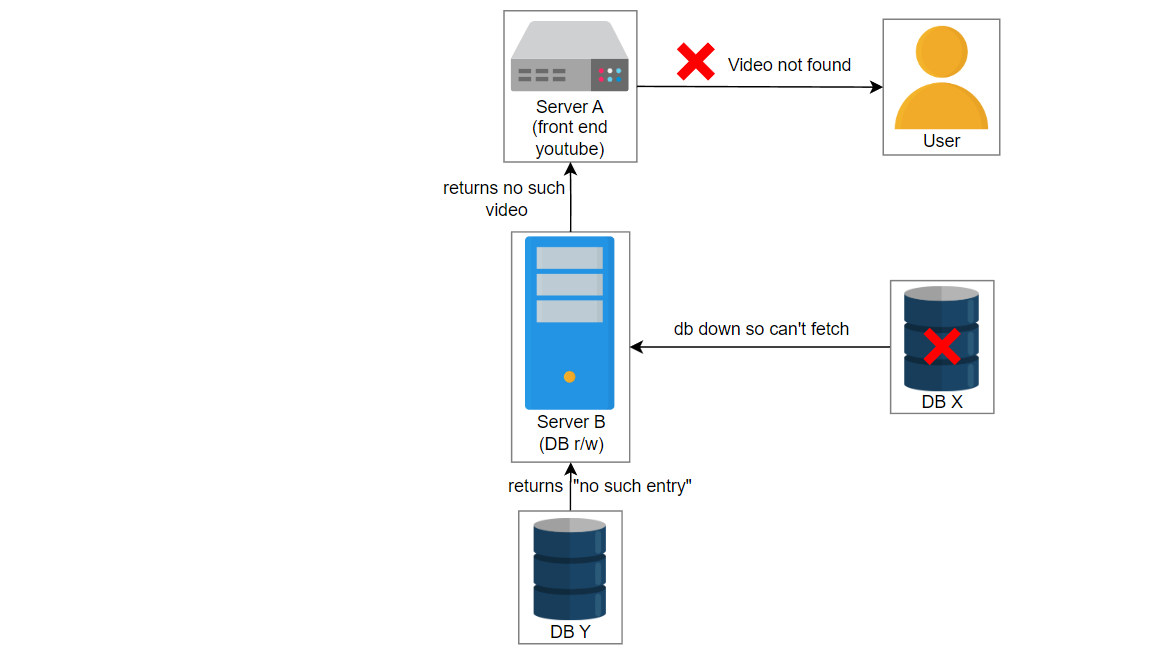
上面的示例相对简单。在现实中,由于我们有许多数据中心分布在全球各地,每个数据中心都有数百万台服务器,因此遇到了复杂的问题。由于人类管理员到服务器的比例逐渐降低,通常无法手动找到问题。拥有监控系统可以降低操作成本,并鼓励自动化地检测故障。
停机成本
有一些容错系统设计可以将大多数故障隐藏在终端用户之外,但是捕捉故障在它们成为更大问题之前是至关重要的。未经计划的服务停机可能会很昂贵。例如,2021年10月,Meta的应用程序中断了近九个小时,导致每小时损失约1300万美元。这种损失强调了停机的潜在影响。
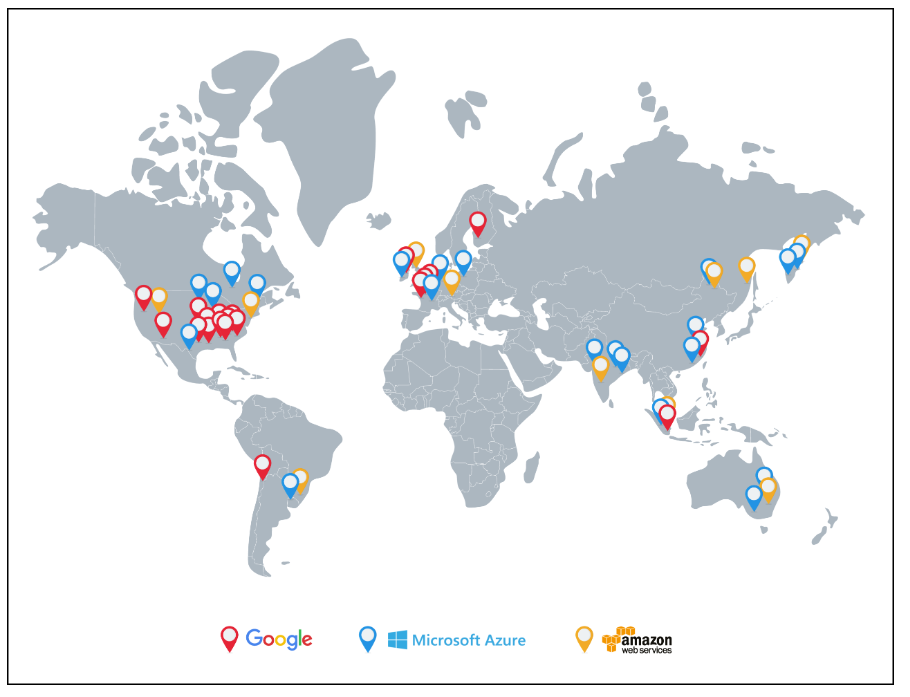
IT基础设施已经广泛分布在全球范围内。下文给出了主要云服务提供商在全球范围内分布的数据中心的概览,截至2021年。这些数据中心通过私有或公共网络连接。监控地理分离的数据中心中的服务器是至关重要的。
根据亚马逊表示,2021年12月7日,“在太平洋标准时间上午7:30,主要AWS网络中托管的AWS服务之一的自动扩容活动触发了大量位于内部网络中的客户端的意外行为。这导致连接活动的大量激增使得连接内部网络和主要AWS网络之间的网络设备不堪重负,结果导致这些网络之间的通信延迟。这些延迟增加了这些网络之间通信中的延迟和错误,导致更多的连接尝试和重试。这导致连接两个网络的设备上出现持续的拥塞和性能问题。”根据估计,亚马逊的停机时间成本是每分钟66240美元。
监控类型
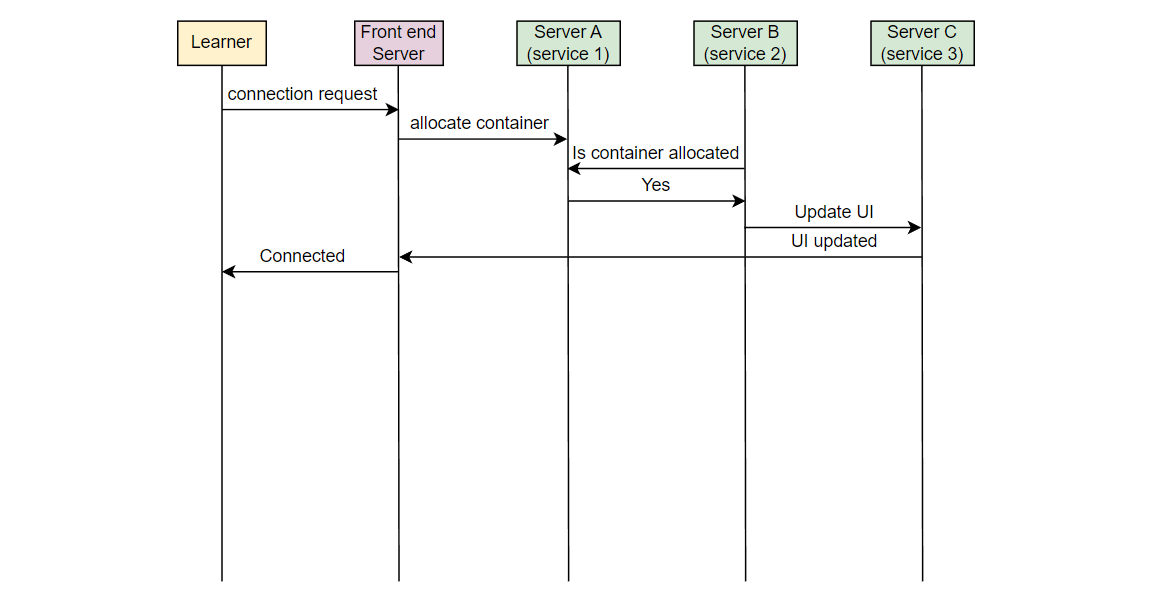
让我们以一个例子来理解我们想要监视的错误类型。在 Educative,每当一个学习者连接到可执行环境时,一个容器被分配。考虑在服务器 A 上的服务 1,它负责在学习者连接时分配容器。另一个服务,在服务器 B 上的服务 2,将该信息取出并通知负责 UI 的服务。在服务器 C 上运行的 UI 服务为学习者更新 UI。假设由于某些错误,服务 2 失败,学习者看到“无法连接…”的错误消息。
Educative 的开发人员如何知道学习者面临这个错误?
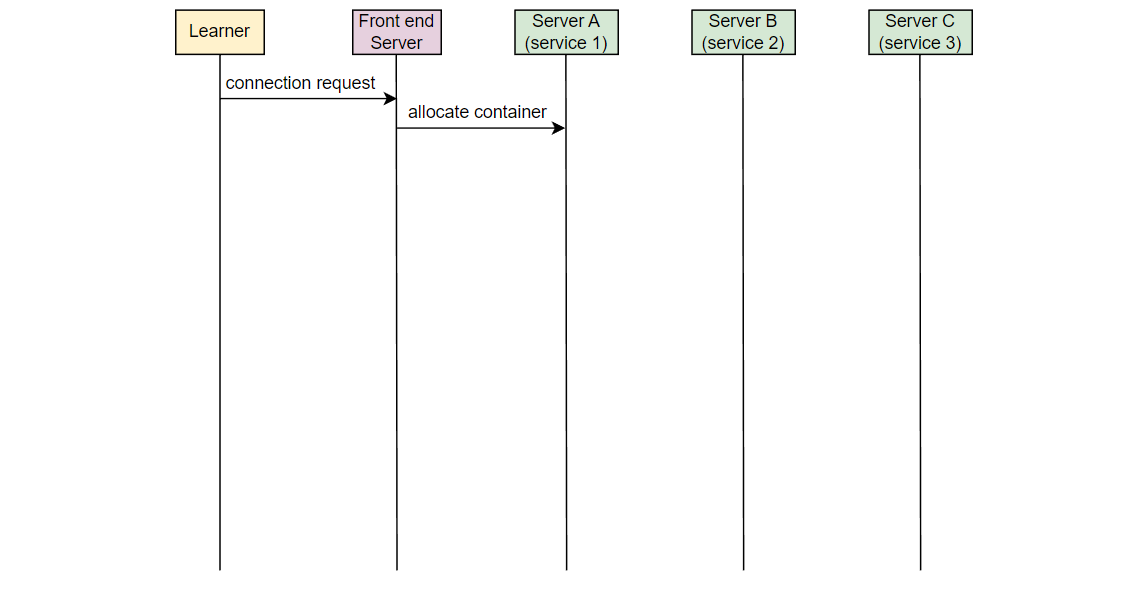
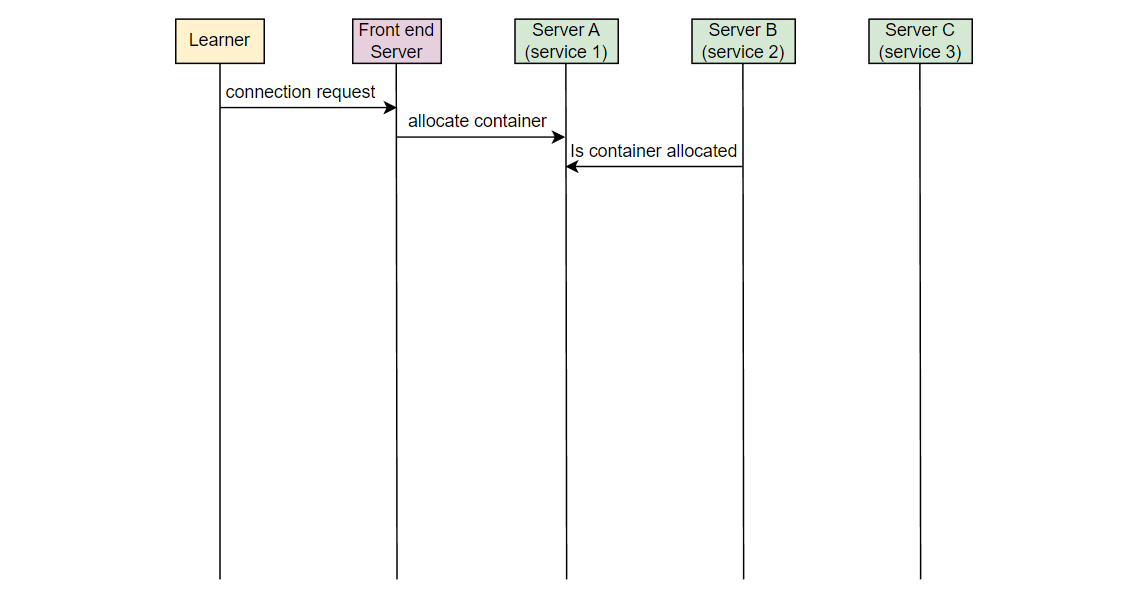
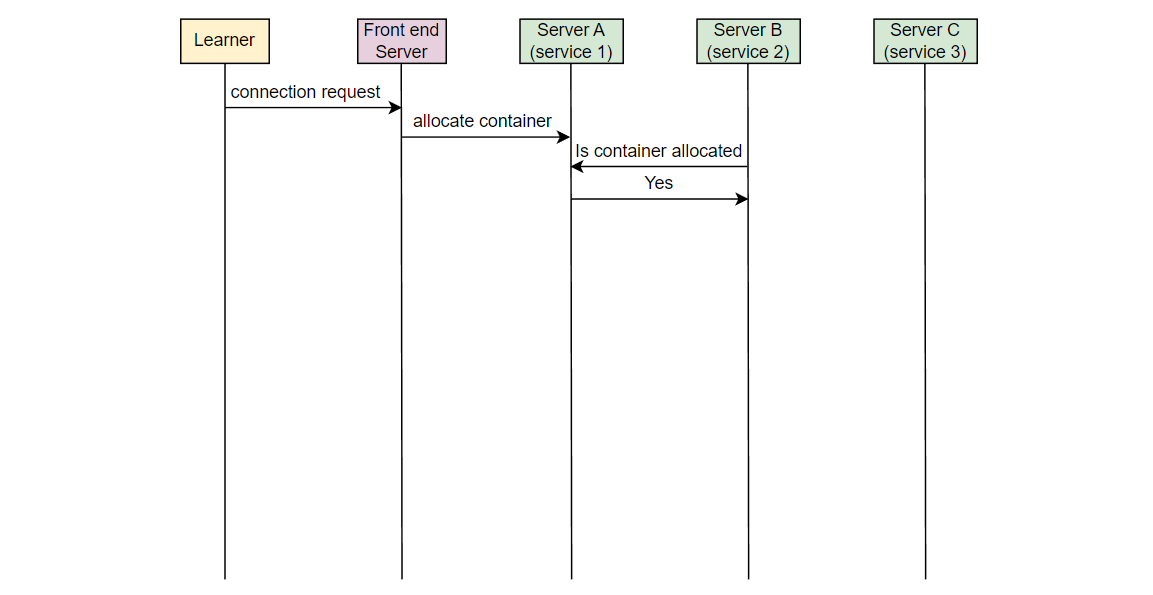
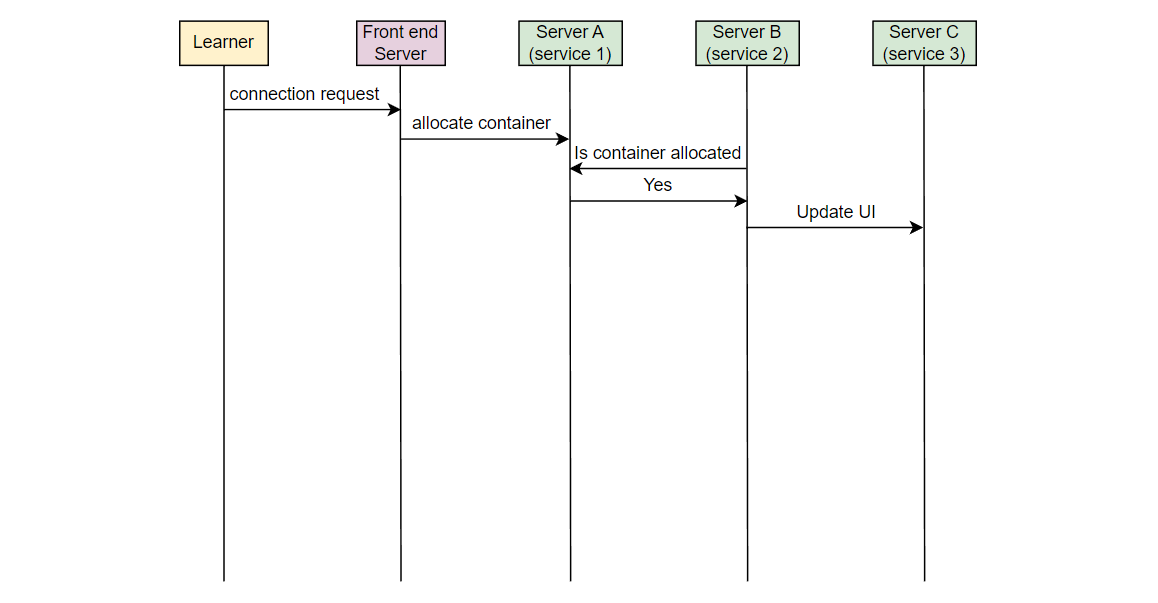
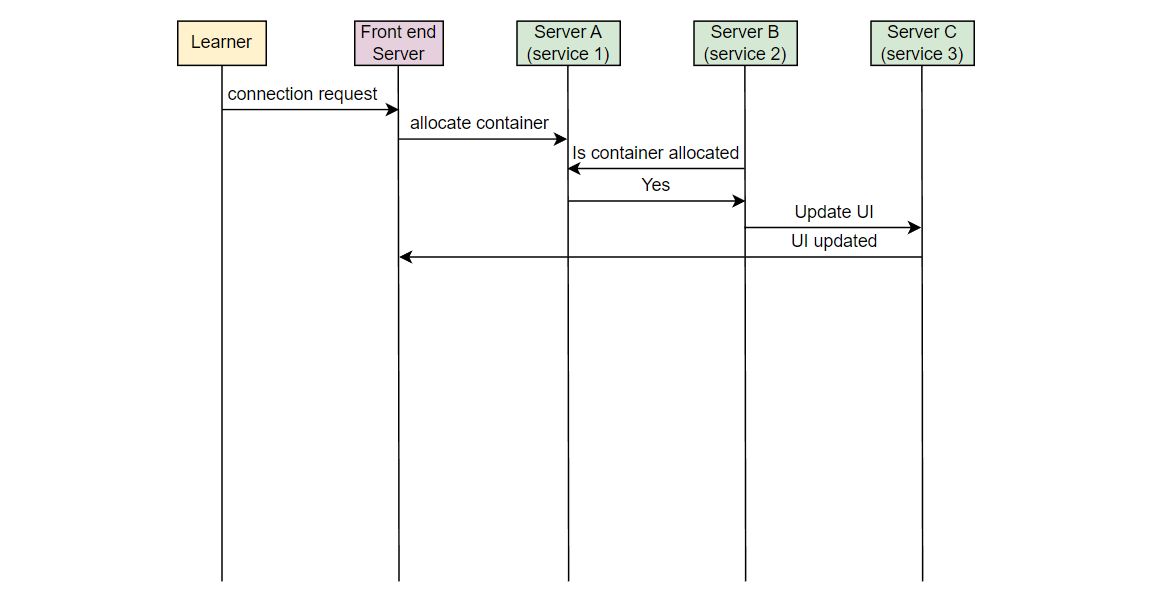
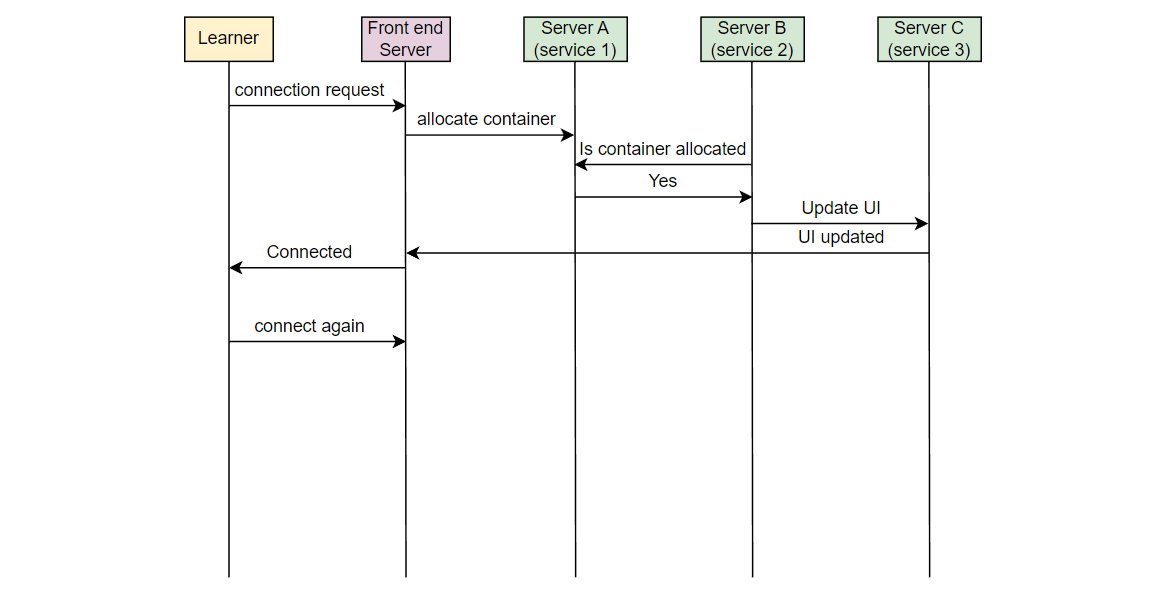
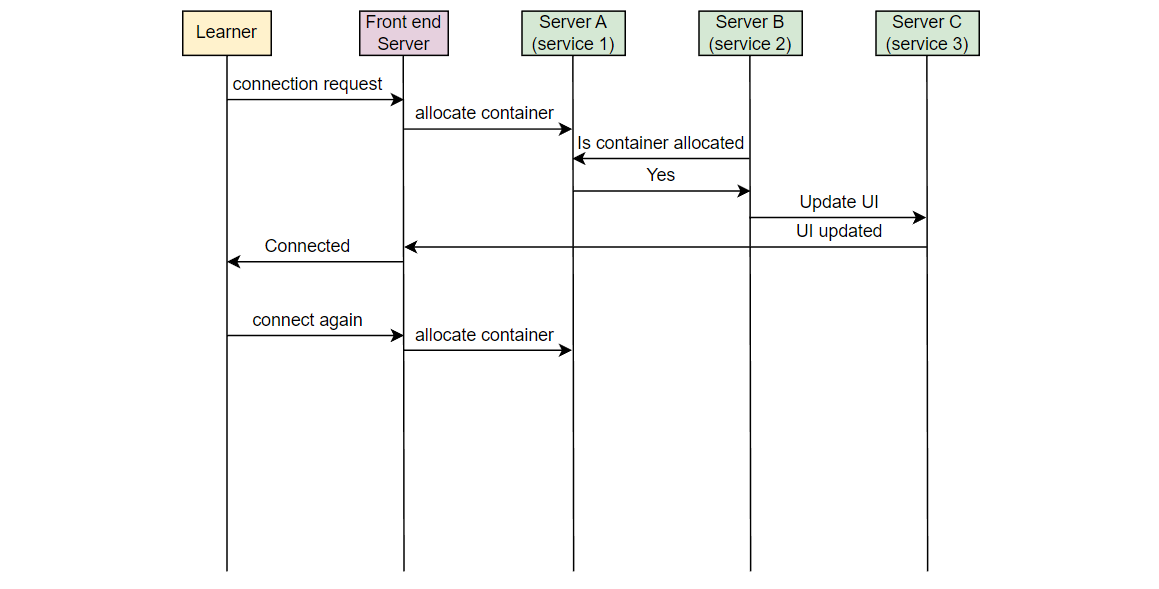
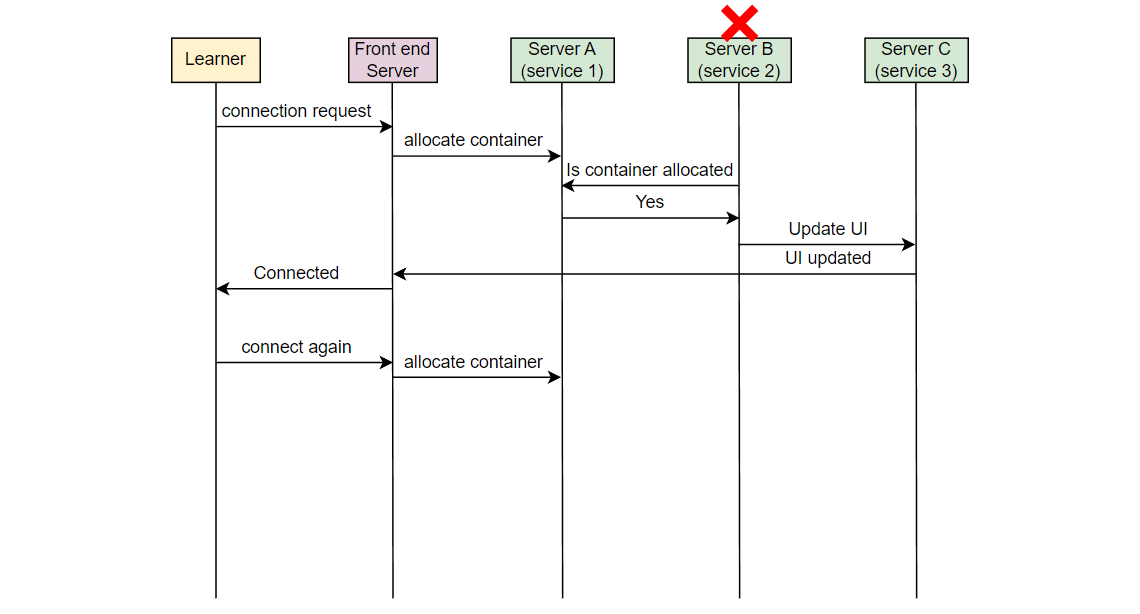
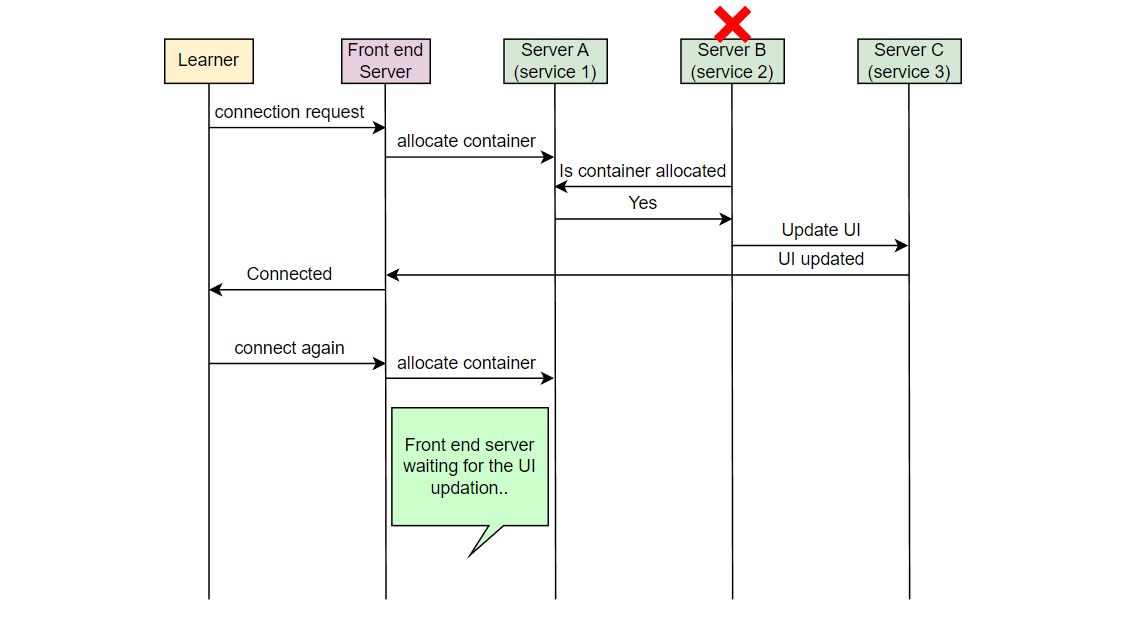
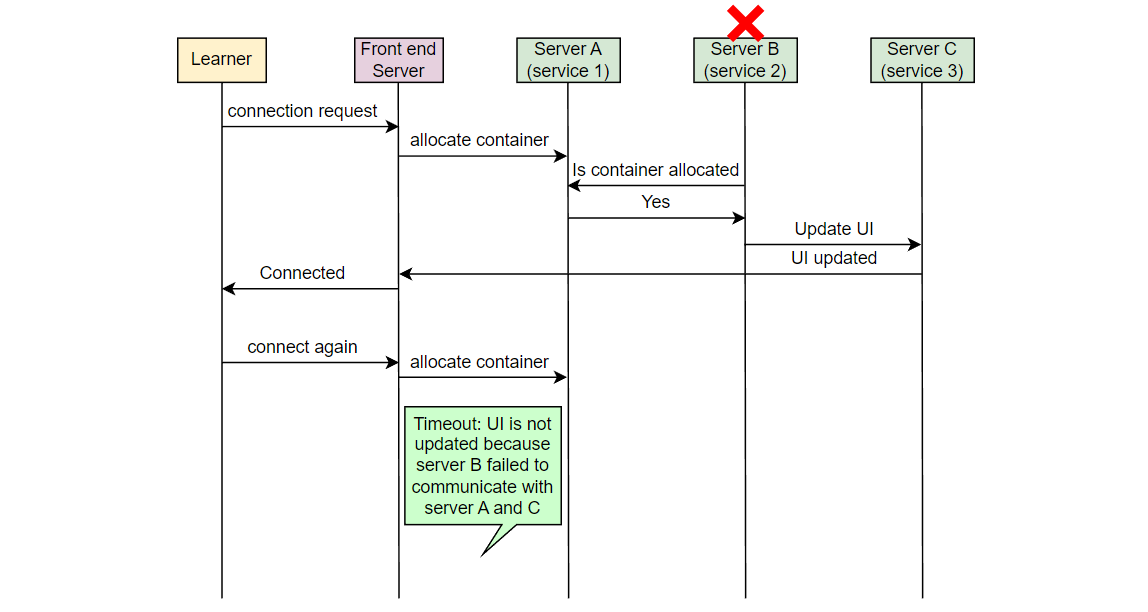
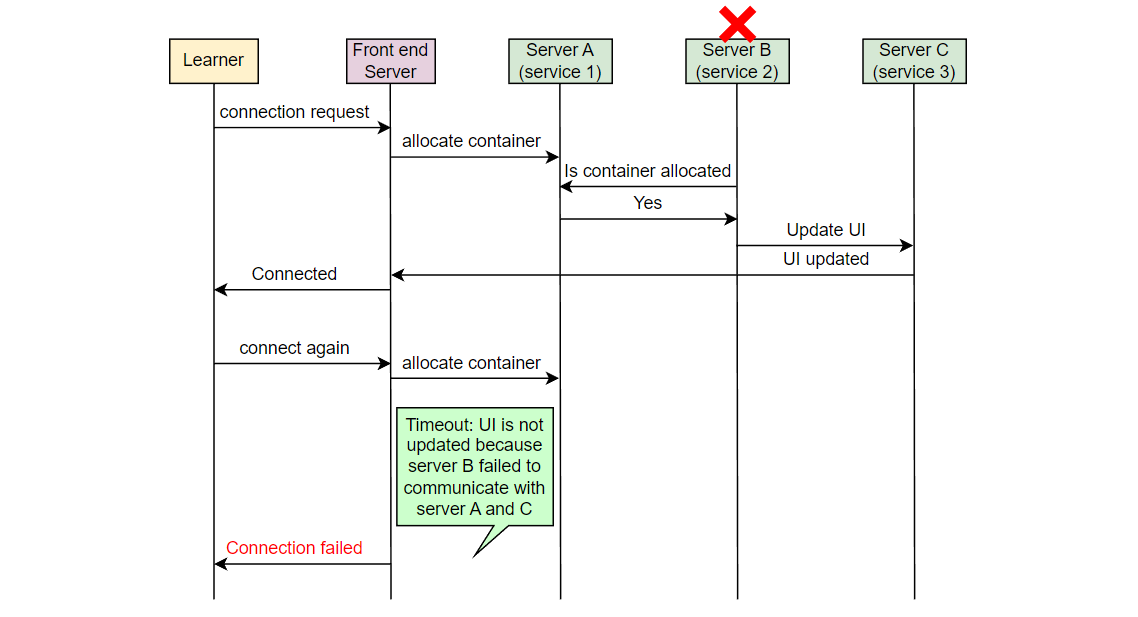
现在,如果一个学习者发出请求,但从未到达 Educative 的服务器,Educative 如何知道学习者面临问题?
通过上述例子,我们将监控焦点分为两个广泛的错误类别:
- 服务端错误: 这些错误通常在服务器上发生并对监控服务可见。这类错误在HTTP响应代码中被报告为错误5xx。
- 客户端错误: 这些错误的根源是在客户端。这类错误在HTTP响应代码中被报告为错误4xx。一些客户端错误在服务请求未能到达时对服务不可见。
我们将在即将到来的章节监控服务端错误和监控客户端错误中探讨如何设计监控服务来处理这两种情况。我们希望我们的监控系统能够分析我们全球分布的服务。这样可以更好地了解系统的组件,并能够敏捷地检测和响应故障。