唯一标识符生成器的设计
学习如何设计一个生成唯一标识符的系统。
在上一个课程中,我们了解到对于诸多用例(例如,识别对象、跟踪复杂服务网络中的执行流程等)我们需要唯一标识符。现在,我们将正式规定唯一标识符所需的条件,并讨论三个逐步改进的设计以满足我们的需求。
唯一标识符的条件
我们系统的要求如下:
唯一性:我们需要给不同的事件分配唯一的标识符进行识别。
可扩展性:ID生成系统每天应该生成至少10亿个唯一标识符。
可用性:由于多个事件甚至在纳秒级别发生,我们的系统应该为所有发生的事件生成唯一标识符。
64位数字ID:
我们限制ID长度为64位,因为这个位数足够满足未来很多年的需求。现在让我们计算多少年之后我们的ID范围将会循环。
总可用数字 = 2的64次方 = 1.8446744 x 10^19
每天估计的事件数量 = 10亿 = 10^9
每年的事件数量 = 3650亿 = 365 x 10^9
用尽标识符范围的年数 = 2^64 / (365 x 10^9) = 50,539,024.8595年
考虑到这些计算,64位应该足够作为唯一ID长度。
让我们深入讨论上述问题的可能解决方案。
第一种解决方案:UUID
我们设计的草案解决方案使用 UUID(通用唯一标识符)。这是一个128位的数字,看起来像是十六进制表示的 123e4567-e89b-12d3-a456-426614174000。它可以提供约 10^38 个数字。UUID有不同的版本,我们选择第4版,它生成一个伪随机数。
每个服务器都可以生成自己的ID,并将ID分配给其对应的事件。UUID不需要协调,因为它与服务器无关。使用UUID进行扩展和收缩很容易,并且这个系统也高度可用。另外,它具有较低的碰撞概率。下面给出了该方法的设计:
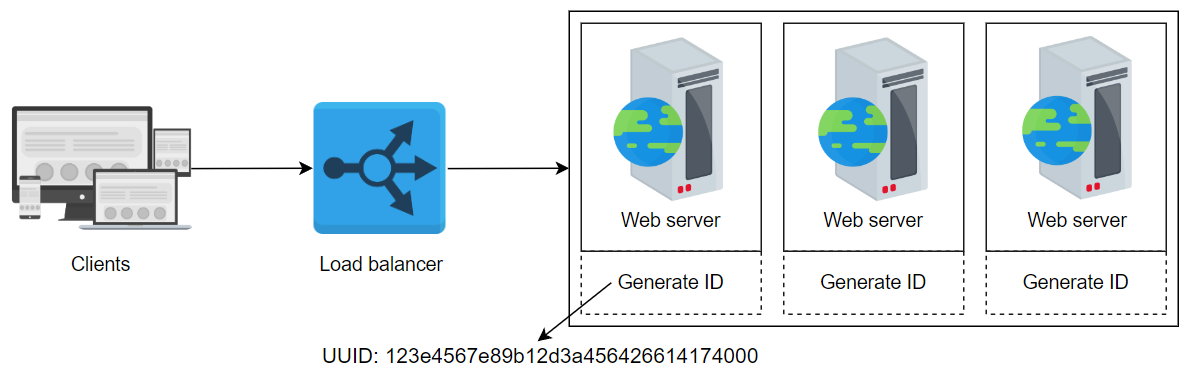
选择所有适用的选项:使用UUID方法的优点是什么?
A) 不需要服务器之间的同步。
B) 是一种简单的方法。
C) 具有可扩展性。
D) 是可用的。
缺点
使用128位数作为主键会使主键索引变慢,导致插入变慢。解决方法可能是将ID解释为十六进制字符串而不是数字。但是,非数字标识符可能不适合许多用例。ID不是64位大小。此外,存在重复的可能性,虽然这种可能性很小,但我们不能声称UUID具有确定性唯一性。另外,随着时间推移,分配给客户的UUID可能不是单调递增的。以下表格总结了我们使用UUID实现的要求:
| 唯一 | 可扩展性 | 可用性 | 64位数字ID | |
|---|---|---|---|---|
| 使用UUID | ✖️ | ✔️ | ✔️ | ✖️ |
第二种解决方案:使用数据库
让我们尝试模仿数据库的自动增量功能。考虑一个提供当前ID并将该值增加一的中央数据库。我们可以将当前ID用作我们事件的唯一标识符。
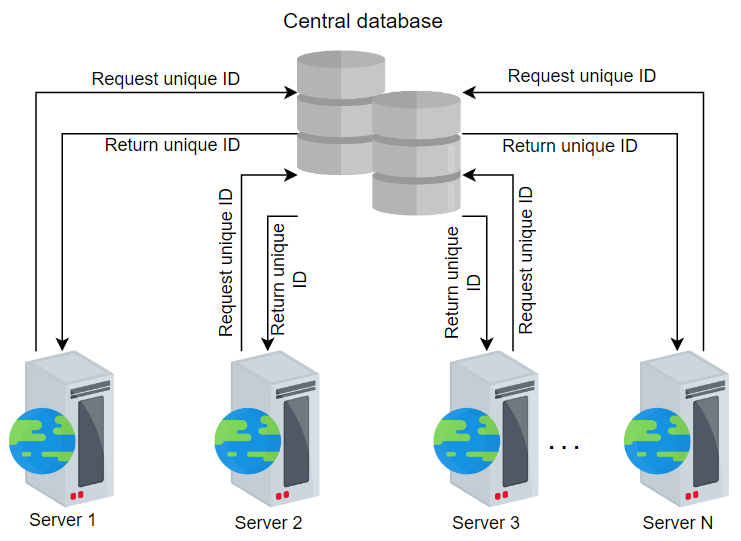
提示
问题:
使用中央数据库的潜在风险是什么?
答案:
这个设计有一个很大的问题:单点故障。依赖于一个数据库会严重影响整个系统。如果中央数据库崩溃,整个系统将停止工作。使用m值生成唯一ID的解决方法
为了解决单点故障问题,我们修改了传统的按一递增的自动增量功能。我们不再按一递增,而是依赖于一个值m,其中m等于我们拥有的数据库服务器数量。每个服务器生成一个ID,紧随其后的ID会在前一个值上加上m。这种方法是可扩展的,并且可以防止ID的重复。下面的图片提供了使用数据库生成唯一ID的可视化示例:
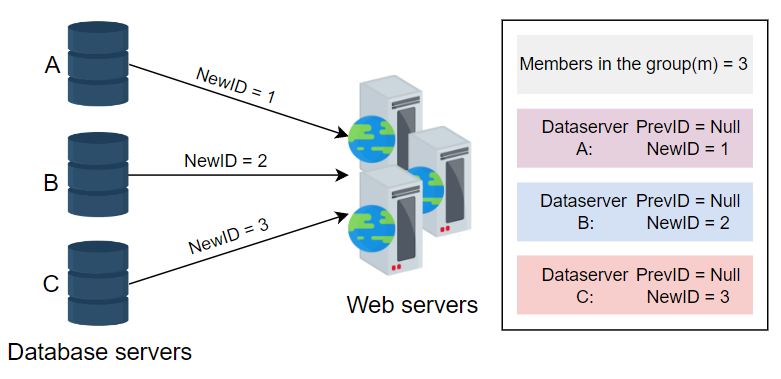
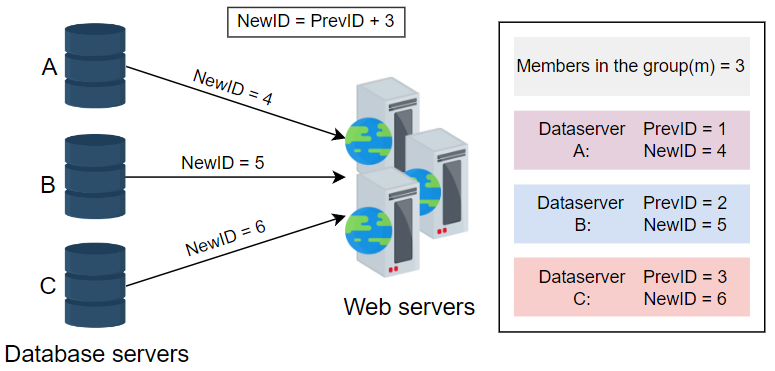
优点
该方法是可扩展的。我们可以添加更多服务器,m的值会相应更新。
缺点
虽然这种方法在某种程度上是可扩展的,但很难为多个数据中心扩展。添加和删除服务器的任务可能会导致ID的重复。例如,假设m=3,服务器A生成唯一的ID 1、4和7。服务器B生成ID 2、5和8,而服务器C生成ID 3、6和9。由于某些失误,服务器B面临宕机。现在,m的值已更新为2。服务器A生成9作为其后续唯一ID,但此ID已被服务器C生成。因此,ID不再是唯一的。
下表突出了我们解决方案的局限性。唯一ID生成系统不应该成为单点故障(SPOF)。应该是可扩展和可用的。
| 唯一 | 可扩展 | 可用 | 64位数字ID | |
|---|---|---|---|---|
| 使用UUID | ✖️ | ✔️ | ✔️ | ✖️ |
| 使用数据库 | ✖️ | ✖️ | ✔️ | ✔️ |
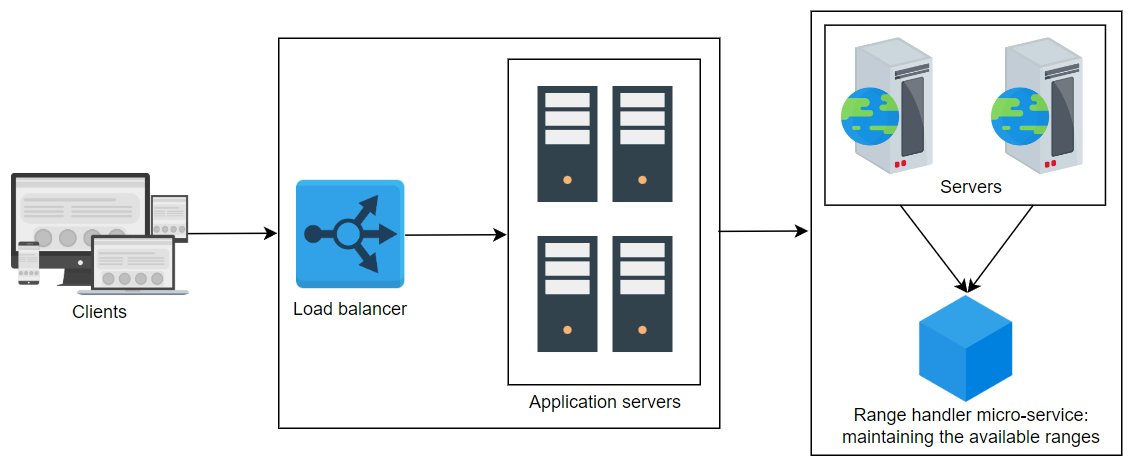
第三种解决方案:使用范围处理器
让我们试着克服以前方法中发现的问题。我们可以在中央服务器中使用范围。假设我们有多个范围,例如1到20亿,如1到100万;100万到200万;等等。在这种情况下,一个中央微服务可以在请求时向服务器提供范围。任何一个服务器需要时都可以申请范围,无论是第一次还是当它用完范围时。假设一个服务器有一个范围,现在它将范围的开始保留在本地变量中。每当请求ID时,它将本地变量值提供给请求者并将值加一。
假设服务器1声明号码范围300001到400,000。在此范围声明后,用户ID 300001分配给第一个请求。服务器然后将300002返回给下一个用户,并递增其当前范围内的位置。这将继续进行,直到用户ID 400000被服务器释放。然后应用服务器会查询中央服务器以获取下一个可用范围,并重复此过程。
这解决了重复用户ID的问题。每个应用服务器都可以同时响应请求。我们可以在一组服务器上添加负载均衡器以减轻请求的负载。
我们使用一个名为范围处理器的微服务,它记录了所有采取和可用范围的记录。每个范围的状态可以确定范围是否可用。状态(即哪个服务器被分配了哪个范围)可以保存在复制存储中。
该微服务可能成为单点故障,但是当主服务器宕机时,备用服务器可以拯救它。备用服务器在主服务器关闭时分配范围。我们可以从复制存储的最新检查点中恢复可用和不可用范围的状态。
优点
这个系统是可伸缩的,可用的,并且产生没有重复的用户ID。此外,我们可以在64位中维护此范围,这是数字化的。
缺点
当服务器死亡时,我们会失去很大的范围,只有在它再次启动之后才能提供新的范围。我们可以通过向服务器分配较短的范围来克服这个缺点,虽然范围应足够大,可以为标识符提供一段时间。
以下表格总结了这种方法对我们的满足要求:
| 唯一的 | 可伸缩的 | 可用的 | 64位数字ID | |
|---|---|---|---|---|
| 使用UUID | ✖️ | ✔️ | ✔️ | ✖️ |
| 使用数据库 | ✖️ | ✖️ | ✔️ | ✔️ |
| 使用范围处理器 | ✔️ | ✔️ | ✔️ | ✔️ |
我们开发了一个解决方案,为我们提供了一个独特的ID,我们可以将其分配给各种事件甚至用作主键。但是,如果我们添加了一个要求,即ID也是可排序的时间戳,会怎么样呢?