DNS如何工作
了解域名系统的详细工作原理。
通过本课程,我们将回答以下问题:
- 如何使用不同类型的DNS名称服务器形成DNS层次结构?
- 在互联网的不同级别上如何进行缓存以减少DNS基础设施的查询负担?
- DNS基础设施的分布式本质如何帮助其健壮性?
让我们开始吧。
DNS层次结构
如前所述,DNS不是单个服务器,它接受请求并响应用户查询。它是一个完整的基础设施,具有不同层次的名称服务器。
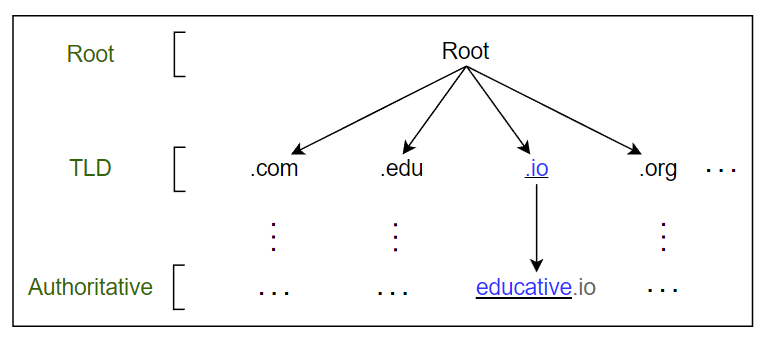
DNS层次结构中主要有四种类型的服务器:
DNS解析器: 解析器启动查询序列并将请求转发给其他DNS名称服务器。通常,DNS解析器位于用户网络的范围内。但是,DNS解析器还可以通过缓存技术响应用户的DNS查询,稍后我们将详细介绍。这些服务器也可以称为本地或默认服务器。
根级别名称服务器: 这些服务器收到本地服务器的请求。根名称服务器基于顶级域名(如
.com、.edu、.us等)维护名称服务器。例如,当用户请求educative.io的IP地址时,根级别名称服务器将返回一个包含.io域的IP地址的顶级域名(TLD)服务器列表。顶级域名(TLD)名称服务器: 这些服务器持有授权名称服务器的IP地址。查询方将获取属于组织的授权服务器的IP地址列表。
授权名称服务器: 这些是组织的DNS名称服务器,它们提供Web或应用程序服务器的IP地址。
相关信息
问题
DNS名称如何处理?例如,educative.io将从左到右或从右到左处理?
答案:
与UNIX文件不同,DNS名称从右到左处理。对于educative.io,解析器将首先解析.io部分,然后是educative等等。
视觉上,DNS层次结构可以看作是一棵树。
迭代查询和递归查询解决方案比较
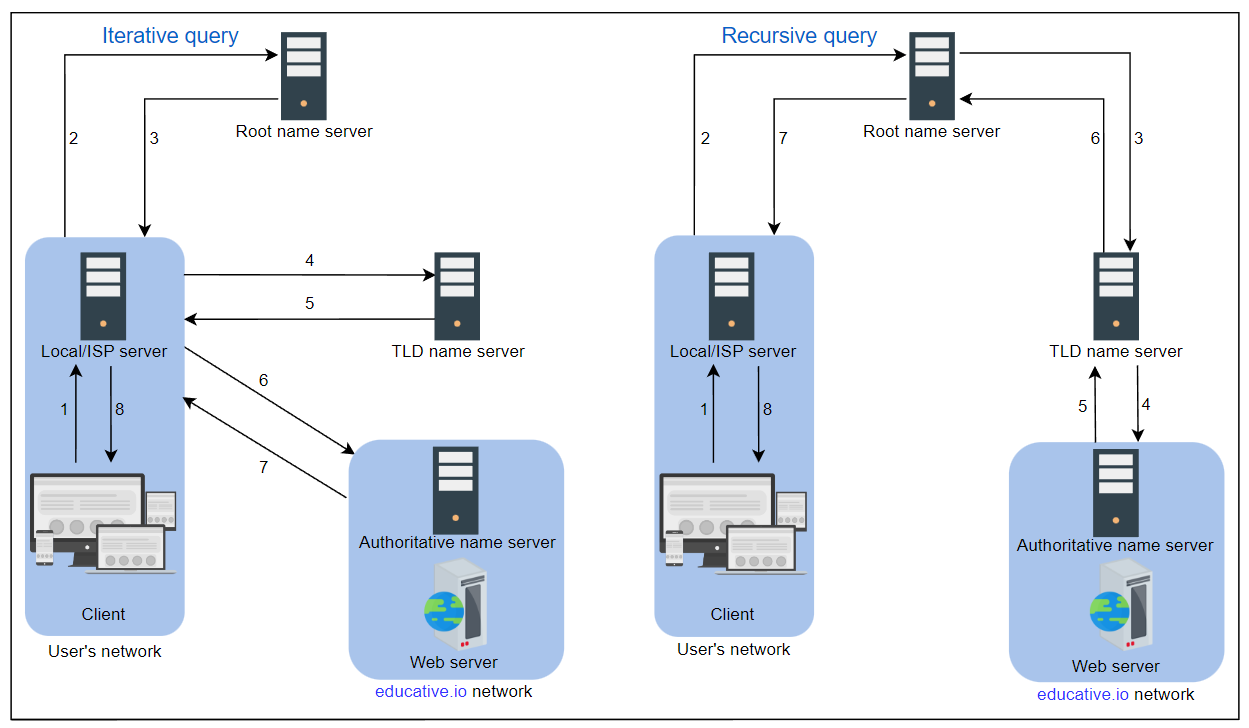
有两种方法可以执行DNS查询:
迭代: 本地服务器向根服务器、TLD服务器和授权服务器请求IP地址。
递归: 终端用户向本地服务器请求。本地服务器进一步请求DNS根名称服务器。根名称服务器将请求转发给其他名称服务器。
在下面的插图(图左)中,本地/ISP服务器的DNS查询解决方案是迭代的:
相关信息
注意: 通常,迭代查询优先于递归查询,以减少DNS基础设施的查询负载。
现在,我们会发现许多谷歌、Cloudflare、OpenDNS等提供的第三方公共DNS解析器。有趣的事实是这些公共DNS服务器可能会比本地ISP DNS设施提供更快的响应。
缓存
缓存指的是经常请求的资源记录的临时存储。
一个记录是DNS数据库中显示名称与值绑定的数据单元。
缓存减少了对用户的响应时间并减少了网络流量。
当我们在不同的层次使用缓存时,它可以减少DNS基础架构上的许多查询负担。缓存可以在浏览器、操作系统、用户网络内的本地名称服务器或ISP的DNS解析器中实现。
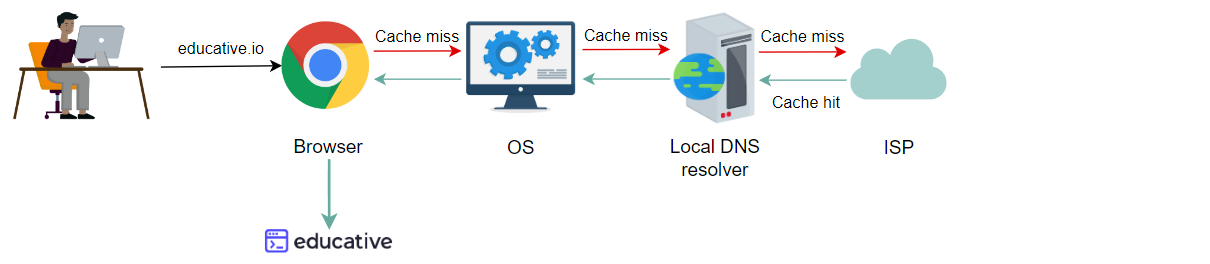
下面的幻灯片演示了DNS中缓存的威力:

用户请求访问一个URL,浏览器已经缓存了域名到IP地址的映射
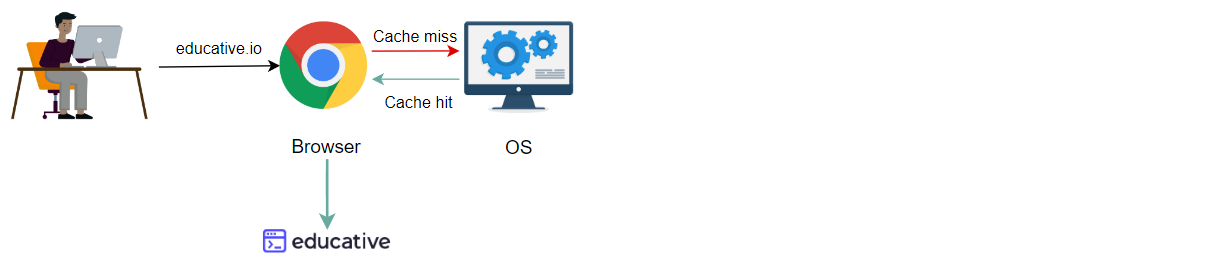
如果浏览器没有缓存域到IP地址的映射,接下来可以有该映射的OS
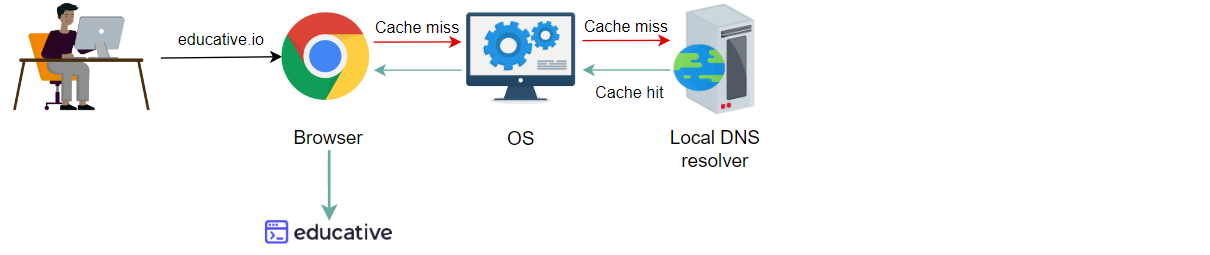
如果OS没有该映射,本地DNS解析器可以有缓存响应
如果本地DNS解析器没有该映射,ISP可以有缓存响应
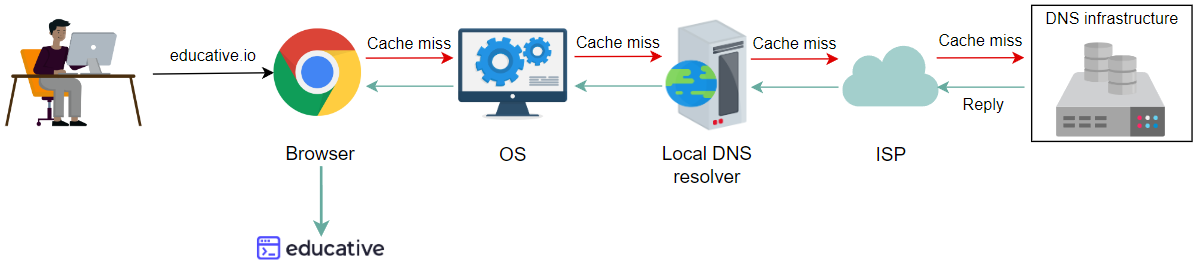
最后,DNS基础架构将以IP响应
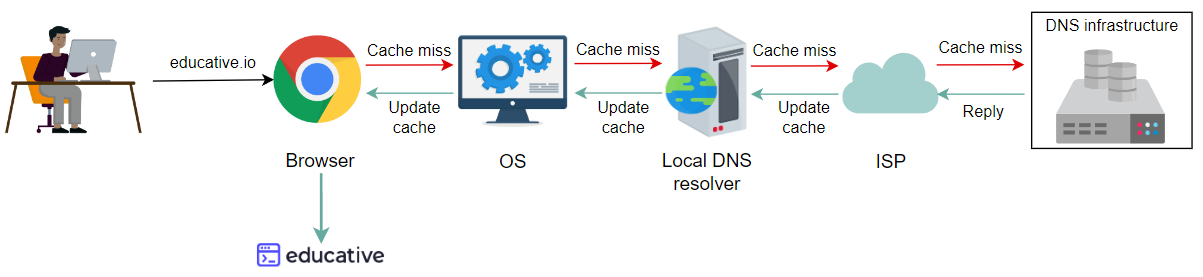
缓存将在每个层次更新

浏览器现在更新了缓存,所以用户请求将在本地得到服务
提示
注意: 即使没有可用的缓存来解析用户的查询并且访问DNS基础设施至关重要,缓存仍然有益。本地服务器或ISP DNS解析器可以缓存TLD服务器或权威服务器的IP地址并避免请求根级服务器。
DNS作为分布式系统
尽管DNS层次结构促进了我们今天所知的分布式互联网,但它本身是一个分布式系统。 DNS的分布式特性具有以下优点:
避免成为单点故障(SPOF)。
实现低查询延迟,以便用户可以从附近的服务器获得响应。
在维护、更新或升级时获得更高的灵活性。
例如,如果一个DNS服务器宕机或负担过重,另一个DNS服务器可以响应用户查询。
相关信息
有13个逻辑根名称服务器(以字母A到M命名)在全球范围内分布许多实例。这些服务器由12个不同的组织管理。
现在,让我们来看看DNS如何具有可伸缩性、可靠性和一致性。
高度可伸缩性
由于其层次结构性质,DNS是一个高度可伸缩的系统。大约有1,000个复制的13个根级服务器实例在全球战略地分布,以处理用户查询。工作任务分配在TLD和根服务器之间以处理查询,最后,由组织本身管理的权威服务器使整个系统工作。如上所示的DNS层次树中,不同的服务处理不同部分的树,实现了系统的可扩展性和可管理性。
可靠性
DNS成为一个可靠的系统有三个主要原因:
- 缓存: 缓存在浏览器、操作系统和本地名称服务器中进行,ISP DNS解析器也维护着访问频率很高的服务的丰富缓存。即使一些DNS服务器暂时关闭,缓存记录也可以提供服务,从而使DNS成为一个可靠的系统。
- 服务器复制: DNS在全球范围内有每个逻辑服务器的复制副本,以在低延迟下处理用户请求。冗余服务器提高了整个系统的可靠性。
- 协议: 尽管许多客户端使用DNS通过不可靠的用户数据报协议(UDP),但UDP具有其优点。UDP要快得多,因此提高了DNS的性能。此外,自其成立以来,Internet服务的可靠性已经得到了改善,因此通常情况下UDP优于TCP。如果之前的UDP请求没有得到响应,DNS解析器可以重新发送UDP请求。这种请求-响应只需要一次往返,这比TCP需要三次握手更短的延迟。
相关信息
问题:
如果网络拥塞会发生什么?DNS应该继续使用UDP吗?
答案:
通常,DNS使用UDP。然而,当其消息大小超过512个字节的原始数据包大小时,DNS可以使用TCP。这是因为大尺寸数据包更容易在拥塞的网络中受到损坏。DNS总是使用TCP进行区域传输。一些客户端喜欢使用DNS over TCP来使用传输层安全性,出于隐私方面的考虑。
一致性
DNS使用各种协议在分层复制服务器之间更新和传输信息。
为了实现高性能,DNS在强一致性上做出了让步,因为与写入相比,数据经常从DNS数据库中读取。
然而,DNS提供最终一致性,并懒惰地在复制服务器上更新记录。
通常情况下,更新DNS服务器上的记录需要几秒钟到三天的时间。
将信息传播到不同的DNS集群中所需的时间取决于DNS基础架构、更新大小以及正在更新的DNS树的哪个部分。
由于缓存,一致性可能会受到影响。
由于权威服务器位于组织内部,因此可能会在组织服务器故障时在权威服务器上更新某些资源记录。
因此,在默认/本地和ISP服务器上缓存的记录可能已过时。为了缓解这个问题,每个缓存记录都有一个过期时间,称为生存时间(TTL)。
相关信息
问题
为了保持高可用性,TTL值应该是大还是小?
答案:
为了保持高可用性,TTL值应该是小的。这是因为如果任何服务器或集群发生故障,组织可以立即更新其资源记录。
用户将仅在TTL未过期的时间内体验到不可用性。但是,如果TTL很大,组织将更新其资源记录,而用户将继续ping已经崩溃了很久的过时服务器。
渴望高可用性的公司将TTL值保持在120秒左右。因此,即使发生故障,最大停机时间也是几分钟。
测试一下
让我们运行一些命令。单击终端以执行以下命令。将以下命令复制到终端中以运行它们。研究命令的输出:
nslookup www.google.comdig www.google.com
以下幻灯片展示了nslookup和dig输出的一些重要方面。
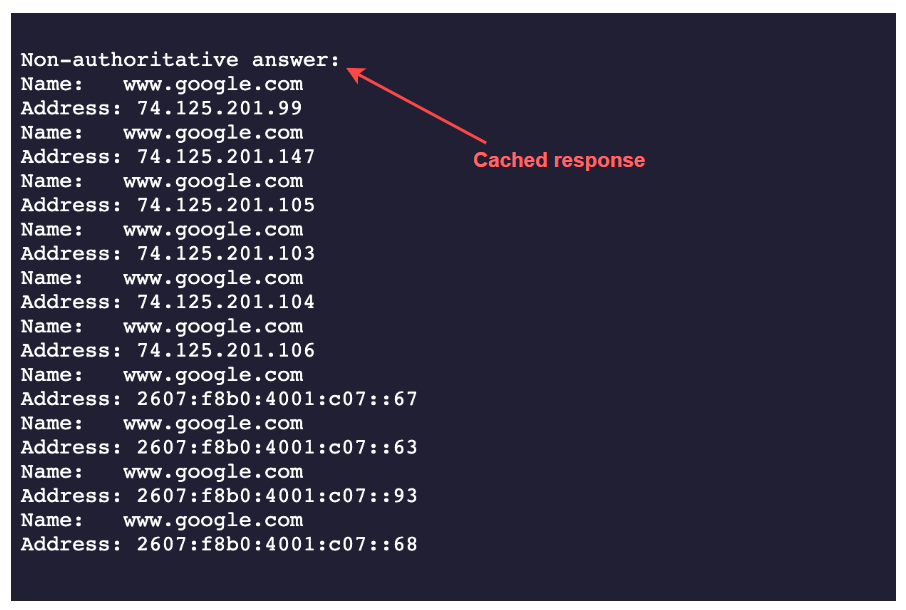
nslookup www.google.com的输出
让我们来看一下输出的含义:
nslookup输出
Non-authoritative answer正如名称所示,是Google的权威服务器未授权的服务器提供的答案。它不在Google维护的权威名称服务器列表中。那么答案从哪里来呢?答案是由二手、三手和四手名称服务器提供的,这些名称服务器被配置为响应我们的DNS查询,例如我们的大学或办公室DNS解析器、我们的ISP名称服务器、我们的ISP的ISP名称服务器等等。简而言之,它可以被认为是Google权威名称服务器响应的缓存版本。如果我们尝试多个域名,我们会意识到我们大多数时候收到的是缓存响应。- 如果我们多次运行相同的命令,我们将接收相同的IP地址列表,但每次顺序都不同。这是因为DNS间接执行了负载平衡。这是我们将在接下来的课程中熟悉的一个重要术语。
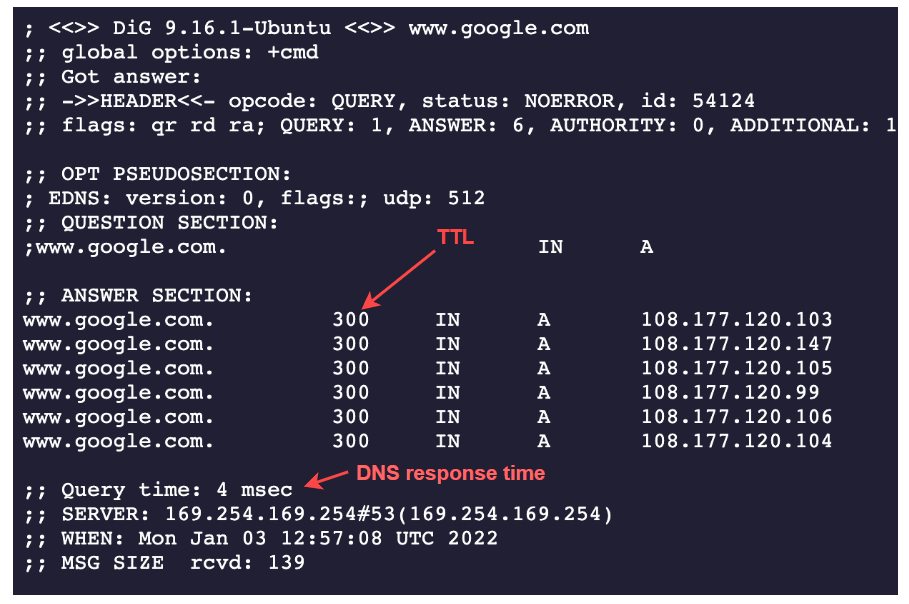
dig输出
ANSWER SECTION 中的 300 值表示DNS解析器维护的缓存的秒数。这意味着Google的ADNS保持了5分钟的TTL值。
Query time: 4 msec表示从DNS服务器获取响应所需的时间。由于各种原因,这些数字在我们的情况下可能不同。
提示
注意: 我们邀请您测试不同服务的TTL和查询时间,以加强您的理解。您可以想办法购买更多的服务器, 测试其不同的访问时间(毕竟没有人家官网的技术)
相关信息
问题
如果我们需要DNS告诉我们到达网站或服务的IP,我们将如何知道DNS解析器的IP地址?(这似乎是一个鸡和蛋的问题!)
答案
终端用户的操作系统具有配置文件(在Linux中为/etc/resolv.conf),其中包含DNS解析器的IP地址,这些DNS解析器随后为它们获取所有信息。 (通常,DHCP提供默认的DNS解析器IP地址以及其他配置。)
终端系统请求DNS解析器解析任何DNS查询。 DNS解析器安装了特殊软件,以通过DNS基础架构解决查询。
根服务器的IP地址在特殊软件中。通常,在DNS解析器上使用Berkeley Internet Name Domain(BIND)软件。
InterNIC维护13个根服务器的最新列表。因此,我们通过向每个解析器提供根DNS服务器的先验知识(其IP地址很少更改)来打破鸡和蛋问题。