量化概要计算的数字
学习在概略计算中使用适当的数字。
为什么要使用概略计算?
分布式系统有通过网络连接的计算节点。有许多不同类型的计算节点,它们可以以许多不同的方式连接。概略计算帮助我们忽略系统的细节(至少在设计层面),并关注更重要的方面。
一些概略计算的例子可能包括:
- 服务器可以支持的并发TCP连接数。
- Web、数据库或缓存服务器可以处理的每秒请求数(RPS)。
- 服务的存储需求。
在这些计算中选择不合理的数字可能导致有缺陷的设计。由于我们在许多设计问题中需要良好的估计,因此我们将在本课程中详细讨论所有相关的概念。这些概念包括:
- 数据中心服务器的类型。
- 不同组件的实际访问延迟。
- 服务器可以处理的RPS的估计。
- 带宽、服务器和存储估计的示例。
数据中心服务器的类型
数据中心没有单一类型的服务器。企业解决方案使用普通硬件以节省成本并开发可扩展的解决方案。下面,我们将讨论数据中心中常用于处理不同工作负载的服务器类型。
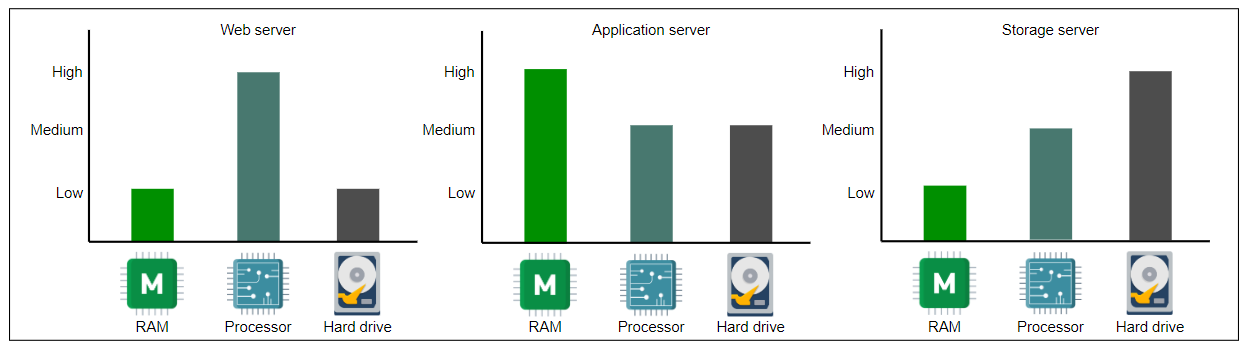
服务器 Web、应用和存储层所需资源的近似值。Y轴是一个分类轴,包括低、中和高的数据点。
Web 服务器
为了可扩展性,Web 服务器与应用程序服务器分离。Web 服务器是负载均衡器之后的第一个接触点。数据中心有一整个机架的 Web 服务器通常处理来自客户端的 API 调用。根据提供的服务,Web 服务器的内存和存储资源可以是小到中等。但是,这样的服务器需要良好的计算资源。例如,Facebook 曾使用具有 32 GB RAM 和 500 GB 存储空间的 Web 服务器。但对于其高端计算需求,它与英特尔合作构建了定制的 16 核处理器。
提示
注意:本课程中引用的许多数字是从 Facebook 在 2011 年开源的数据中心设计中获得的。由于 Moore 定律诱导的性能减缓约在 2004 年左右,这些数字并不陈旧。
应用服务器
应用服务器运行核心应用软件和业务逻辑。
Web 服务器和应用服务器之间的区别有些模糊。
应用服务器主要提供动态内容,而 Web 服务器主要为客户端(通常是 Web 浏览器)提供静态内容。
它们可能需要大量的计算和存储资源。存储资源可以是易失性和非易失性的。Facebook 曾经使用过具有最多 256 GB RAM 和两种存储(传统旋转硬盘和闪存)的应用服务器,容量高达 6.5 TB。
存储服务器
随着互联网用户的激增,巨型服务存储的数据量增加了。此外,各种类型的数据现在被存储在不同的存储单元中。例如,YouTube 使用以下数据存储:
- 用于编码视频的Blob 存储。
- 一个临时处理队列存储,可以容纳每天上传到 YouTube 进行处理的数百小时视频内容。
- 用于存储大量视频缩略图的专用存储称为 Bigtable。
- 关系型数据库管理系统(RDBMS) 用于用户和视频元数据(评论、点赞、用户频道等)。
其他数据存储仍用于分析,例如 Hadoop 的 HDFS。
存储服务器主要包括结构化(例如 SQL)和非结构化(NoSQL)数据管理系统。
回到 Facebook 的例子,我们知道他们曾经使用过具有多达 120 TB 存储容量的服务器。随着使用的服务器数量增加,Facebook 能够容纳 exabytes 的存储。
一个 exabyte 是 10^18 字节。按照惯例,我们以 10 进制而不是 2 进制来衡量存储和网络带宽。然而,这些服务器的 RAM 只有 32 GB。
提示
注意: 上述服务器不是数据中心中唯一的服务器类型。组织还需要服务器来提供配置、监视、负载平衡、分析、计费、缓存等服务。
由 Facebook 开源的数字现在已经过时。在下表中,我们展示了可以在当今数据中心中使用的服务器的能力:
典型服务器规格
| 组件 | 数量 |
|---|---|
| 插槽数 | 2 |
| 处理器 | Intel Xeon X2686 |
| 核心数 | 36 核心(72 线程) |
| RAM | 256 GB |
| 缓存(L3) | 45 MB |
| 存储容量 | 15 TB |
上面的数字受到 Amazon 裸机服务器的启发,但可能会支持更高的 RAM(高达 8 TB)、磁盘存储(每个硬盘高达 24 个,每个硬盘容量高达 20 TB,大约在 2021 年左右)和缓存内存(高达 120 MB)的更强大机器。
记住的标准数字
规划和实施服务需要付出很多努力。但是如果没有任何有关机器可以处理的工作负载类型的基本知识,就无法进行规划。延迟在决定机器可以处理多少工作负载方面起着重要作用。下表显示了一些系统设计师需要知道的重要数字,以进行资源估算。
重要的延迟
| 组件 | 时间(纳秒) |
|---|---|
| L1 缓存引用 | 0.9 |
| L2 缓存引用 | 2.8 |
| L3 缓存引用 | 12.9 |
| 主存储器引用 | 100 |
| 用 Snzip 压缩 1KB | 3,000(3 微秒) |
| 从内存顺序读取 1 MB | 9,000(9 微秒) |
| 从 SSD 顺序读取 1 MB | 200,000(200 微秒) |
| 同一数据中心的往返时间 | 500,000(500 微秒) |
| 从速度约为 1GB/秒 的 SSD 顺序读取 1 MB | 1,000,000(1 毫秒) |
| 磁盘查找 | 4,000,000(4 毫秒) |
| 从磁盘顺序读取 1 MB | 2,000,000(2 毫秒) |
| 发送数据包 SF->NYC | 71,000,000(71 毫秒) |
除了上面列出的延迟之外,还有以每秒查询数(QPS)测量的吞吐量数字,一个典型的单服务器数据存储可以处理。
重要的速率
| MySQL 处理的 QPS | 1000 |
| 键值存储处理的 QPS | 10,000 |
| 缓存服务器处理的 QPS | 100,000–1 M |
上述数字是近似值,因为它们在很多方面都会因查询类型(点和范围)、机器规格、数据库设计、索引等因素而大大变化。
请求估计
本节讨论典型服务器可以处理的请求数。在服务器内,资源有限,根据客户端请求的类型,不同的资源可能会成为瓶颈。让我们了解两种类型的请求。
CPU 绑定请求: 这是一种限制因素是 CPU 的请求类型。
内存绑定请求: 这是一种受机器内存限制的请求类型。
让我们近似计算每种类型请求的 RPS。但在此之前,我们需要假设以下内容:
- 我们的服务器具有我们在上面定义的典型服务器的规格。
- 操作系统和其他辅助进程已使用了总共 16 GB 的 RAM。
- 每个工作者使用 300 MB RAM 存储来完成请求。
- 为了简单起见,我们假设 CPU 从 RAM 中获取数据。因此,缓存系统确保所有所需内容都可供服务,而无需访问存储层。
- 每个 CPU 绑定请求需要 200 毫秒,而内存绑定请求需要 50 毫秒才能完成。
让我们分别计算每种请求类型的 RPS。
CPU 绑定请求: 用于计算 CPU 绑定请求的 RPS 的简单公式如下:
在次计算中, 我们使用如下术语:
上面显示的计算的原理是,我们可以将一秒钟视为一个盒子,并计算有多少个小盒子(任务)可以适合大盒子内,即一些 CPU 可以在一秒钟内完成多少个任务。因此,更高数量的 CPU/线程将导致更高的 RPS。
内存绑定请求: 对于内存绑定请求,我们使用以下公式:
从上面 CPU 绑定请求的解释中继续我们的盒子比喻,我们首先计算有多少个盒子(一个服务器可以托管多少个内存绑定进程),然后计算每个更大的盒子中可以容纳多少个小盒子(任务)。 服务接收 CPU 绑定和内存绑定请求。考虑到一半的请求是 CPU 绑定的,另一半是内存绑定的,我们可以处理总共
上述计算仅是估算基本因素以了解估算 RPS 的基本因素。实际上,还有很多其他因素会发挥作用。例如,如果数据不在 RAM 中,或者如果向数据库服务器发出请求,则需要延迟才能执行磁盘查找。此外,查询类型也很重要。当然,故障、代码中的错误、节点故障、停电、网络中断等不可避免的因素也会对系统性能产生影响。
在典型的一天中,会有各种类型的请求到达,一台仅从 RAM 中提供静态内容的强大服务器可能处理多达 500k RPS。另一方面,计算密集型任务如图像处理可能只允许最多 50 RPS。
提示
注意: 实际上,容量估算是一个艰巨的问题,组织会在多年中学习如何改进它。监控系统关注我们基础设施的所有部分,以便提前警告我们服务器过载。