一致性模型
本节目标: 掌握一致性模型, 做到根据需求确定应用程序的一致性模型。
什么是一致性?
在分布式系统中,一致性可能意味着很多事情。
- 每个副本节点在给定时间点具有相同的数据视图。(zookeeper/主从备份等)
- 每次读请求获取最近写的值。(数据一致性)
- 这些并不是一致性的唯一定义,因为一致性有多种形式。
通常,
实际的系统设计过程中, 我们不可避免要用到 第三方存储系统 (eg: S3 / Cassandra)等, 这些第三方存储系统直接支持的 一致性模型, 是我们做取舍的关键因素 。
一致性范围的两端是:
- 最强一致性
- 最弱一致性
在这两端之间存在一致性模型,其中一些如下图所示:
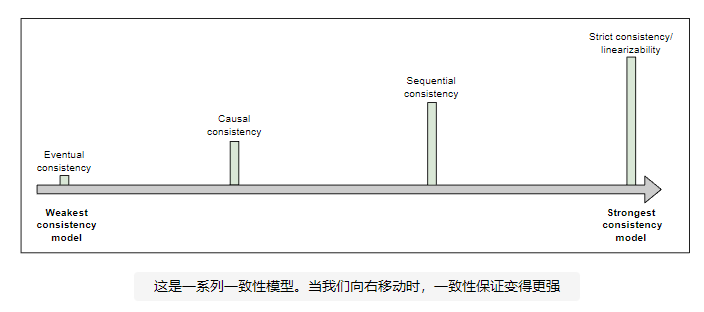
谈到一致性, 就不得不谈到如下两个概念:
事务的 ACID 属性:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
- 数据库规则是ACID 一致性的核心。
- 如果模式指定值必须是唯一的,则一致的系统将确保该值在所有操作中都是唯一的。
- 如果外键指示删除一行也将删除关联的行,则一致的系统确保一旦基行被销毁,该行所有关联的数据都应被销毁。
CAP定理
- 一致性(Consistency)\可用性(Availability)\分区容错性(Partition tolerance)
- 分布式数据库系统中, 只能保持三个特性中的两个 (可以思考下为什么)
- CAP 一致性保证
- 在分布式系统中,相同逻辑值的每个副本始终具有相同的精确值。
- 值得注意的是,这是逻辑而非物理保证。
- 由于光速,在整个集群中复制数字需要一些时间。
- 实际操作中, 可以通过防止客户端访问存在正在变化的值,从逻辑上保证系统的一致性。
最终一致性
最终一致性是最弱的一致性模型。对顺序要求不严格.
可以简单理解为: 系统不额外对数据进行监管操作, 系统中此刻物理地址对应的值, 即是你获取的值.
最终一致性确保所有副本最终将相同的值返回给读取请求,但返回值并不意味着是最新值。该值最终将达到其最新状态。
- T1: 系统创建变量 x=2
- T2: 羊某发出写入请求, 预计在T4时刻将x修改为10
- T3: 羽某 高某 同时尝试读取变量 x, 系统将 x=2 返回给两人
- T4: 羽某 高某 再次读取变量x, 此刻及以后, 系统都将 x=10 返回给两人
最终一致性确保 高可用性。
实例
域名系统是一个高度可用的系统,基于域名系统, 我们可以通过 Internet 对一亿台设备进行名称查找。它使用最终一致性模型,不一定反映最新值。
提示
注意: Cassandra 是一个高度可用的 NoSQL 数据库,提供最终一致性。
因果一致性
因果一致性 的工作原理是
- 将操作分为相关操作和独立操作。
- 相关操作 也称为因果相关操作。
- 因果一致性保留因果相关操作的顺序。
假设有这样一段业务逻辑:
x=a; b=x+5; y=b;
其中 x,y 两个变量分别由进程P1 P2 管理:
当P1进程对x进行赋值后, P2进程不能立刻对 y 进行赋值, 而是要先 read(x)a 在 write(y)b
这时, 我们称 read(x) 与 write(y) 之间有 因果一致性
此模型不确保对没有因果关系的操作进行排序。实际执行中, 未排序的操作可能出现在任何地方.
因果一致性总体上较弱,但强于最终一致性模型。它用于防止非直觉行为。
实例
因果一致性模型用于评论系统。例如,对于 Facebook 帖子上的评论进行回复,我们希望在其回复的评论之后显示评论。这是因为评论与其回复之间存在因果关系。
提示
注意: 除了本课讨论的四种一致性模型之外,还有许多一致性模型,并且仍有空间去定义新的一致性模型。研究人员开发了新的一致性模型。例如,Wyatt Lloyd 等人, 提出了因果+一致性模型来加速某些特定类型的交易。
因果+一致性模型论文Wyatt Lloyd 普林斯顿大学名誉教授
顺序一致性
顺序一致性 比因果一致性模型强。它保留每个客户端程序指定的顺序。然而,顺序一致性并不能确保写入是即时可见的,但可以确保写入的顺序是固定的。(保证了时钟顺序)
实例
在社交网络应用中,我们通常不关心一些朋友的帖子出现的顺序。但是,我们仍然希望单个朋友的帖子以正确的创建顺序出现)。同样,我们希望我们的朋友在帖子中的评论按照他们提交的顺序显示。顺序一致性模型捕获了所有这些特质。
严格一致性(线性化)
严格一致性/线性化 是最强的一致性模型。此模型确保来自任何副本的读取请求将获得最新的写入值。一旦客户端收到写入操作已执行的确认,其他客户端就可以读取该值。
分布式系统天然不支持线性化, 思考这样一个场景:
我们的系统拥有三个响应节点 NodeA NodeB NodeC
T1: 三个节点中拥有值: x = 2
T2: NodeA处理请求 x=10, 预计 T3时刻同步到NodeB T4时刻同步到NodeC
T3: 羊某 羽某 分别请求 NodeB NodeC 尝试获取 x; 两人获取到了不同的结果
该系统不符合 严格一致性
笔者: 实际生产环境中, 可以通过锁/修改集群方式 解决该问题, 但这无疑增加了系统开销,降低了系统可用性, 对压力非常大的读写系统来说, 是不可忍受的
线性化影响系统的可用性,这就是为什么它并不总是被使用的原因。具有强一致性要求的应用程序使用基于复制/仲裁等技术来提高系统的可用性。
实例
更新帐户的密码需要严格的一致性。例如,如果我们怀疑我们的银行账户有可疑活动,我们会立即更改密码,这样未经授权的用户就无法访问我们的账户。如果由于缺乏严格的一致性而可以使用旧密码访问我们的帐户,那么更改密码将是无用的安全策略。
提示
注意: Amazon Aurora 提供强一致性。
摘要
线性化的服务要求以顺序的/实时的顺序执行事务/操作。通过限制线性服务的步骤,降低交互次数, 我们可以更容易的在其之上创建应用程序.
线性化的服务比具有较弱一致性的服务具有更差的性能,但数据更为安全。
如果应用程序程序员使用具有强一致性模型的服务,则他们必须牺牲性能和可用性。这些模型可能会破坏基于它们构建的应用程序的不变性,以换取更高的性能。